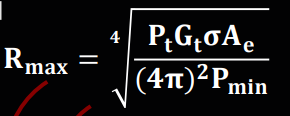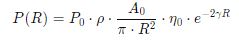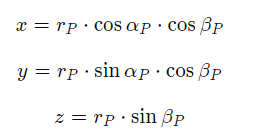Reviewing what I studied, how this work will be explained as well.
Dijkstra Algorithm is a shortest path algorithm that finds the shortest path from a starting node to all other nodes in a graph. Instead of using BFS, it uses priority queue to find the shortest path.
Constraints:
No negative weight edges
No negative cycles
This is not dependent on the how many nodes we are passing through, but the weight of the edges. (distance in this case.)
Let’s see the steps of the algorithm.
Initialize the distance of the starting node to 0, and the rest of the nodes to infinity.
Push the starting node to the priority queue & Pop the starting node from the priority queue.
Update the distance of the adjacent nodes (setting infinity to the edge weight), then push them to the priority queue.
Then select the node with the smallest distance from the priority queue and repeat the process.
Code is as follows.
#include<iostream>
#include<list>
#include<vector>
#include<limits>
#include<queue>
#include<iomanip>usingnamespacestd;// Sedgewick p. 642classDirectedEdge{public:intv;// edge tailintw;// edge headdoubleweight;// edge weightDirectedEdge(intv,intw,doubleweight){this->v=v;this->w=w;this->weight=weight;}doubleWeight(){returnweight;}intFrom(){returnv;}intTo(){returnw;}};classEdgeWeightedDigraph{public:intnum_vertices;intnum_edges;vector<vector<DirectedEdge>>adj;EdgeWeightedDigraph(intnum_vertices){this->num_vertices=num_vertices;this->num_edges=0;adj.resize(this->num_vertices);}voidAddEdge(DirectedEdgee){adj[e.From()].push_back(e);num_edges+=1;}vector<DirectedEdge>&Adj(intv){returnadj[v];}};classDijkstraShortestPaths{public:DijkstraShortestPaths(EdgeWeightedDigraph&g,ints):prev(g.num_vertices,-1),dist(g.num_vertices,numeric_limits<double>::infinity()),visited(g.num_vertices,false){dist[s]=0.0;// distance for self is 0pq.push(pair<double,int>{0.0,s});PrintIndex(dist);PrintDist(dist);while(!pq.empty()){intv=pq.top().second;pq.pop();if(visited[v])continue;visited[v]=true;Relax(g,v);}PrintPaths();}voidRelax(EdgeWeightedDigraph&g,intv){// Get the edge of the vfor(DirectedEdge&e:g.Adj(v)){intw=e.To();if(visited[w])continue;// updatedoublenew_dist=dist[v]+e.Weight();if(dist[w]>new_dist){dist[w]=new_dist;prev[w]=e.From();pq.push({dist[w],w});}}PrintDist(dist);}voidPrintIndex(vector<double>&dist){cout<<"Vertex: ";for(inti=0;i<dist.size();i++)cout<<setw(6)<<i;cout<<endl;}voidPrintDist(vector<double>&dist){cout<<"Dist : ";for(inti=0;i<dist.size();i++)cout<<setw(6)<<dist[i];cout<<endl;}voidPrintPaths(){for(inti=0;i<prev.size();i++){deque<int>path;path.push_front(i);intv=prev[i];while(v!=-1){path.push_front(v);v=prev[v];}for(autov:path){cout<<v;if(v!=path.back())cout<<"->";}cout<<endl;}}private:vector<int>prev;vector<double>dist;vector<bool>visited;priority_queue<pair<double,int>,vector<pair<double,int>>,greater<pair<double,int>>>pq;};
The update function is shown below, as new_distance is smaller than the current distance, we update the distance and push the node to the priority queue.
If we use just a simple array, you can get O(V^2), but if you use priority queue, you can get (V+E) * LogV because priority queue insertion / deletion (Log V), then this happens for each Vertex => V * Log V. Edge Iteration => O(E) Then for relaxation, we update the distance to add that edge would be E * LogV. So we can conclude that it is (V+E) LogV in average. So, sum all it up (O(ELogV + E + VLogV)) => O(V+E logV).
Reviewing what I studied, how this work will be explained as well.
Binary Heap is a complete binary tree that satisfies the heap property.
Heap Property
Max-Heap : Parent node is greater than or equal to child node.
Min-Heap : Parent node is less than or equal to child node.
Heap Constraints
Access the max element instantaneously (that’s why the max element in in the root) -> Max Heap
Min Heap
which extends to the idea that, the parent node should be bigger than the children node.
Swap (If we are to insert the last element into last tree level, then we need to compare the value, and update the tree)
Heap Operations
Search (O(N))
Deletion (Log N)
Peek (O(1))
Insertion (Log N) -> Worst Case / But Best Case is O(1)
Heapify (O(N))
Heapify
If you take a look at the heapify function, it is a function that takes an array, and makes it a heap. So this approximation can be done as follows.
In the logic, we don’t calculate the leaf nodes, we only did siftDown from the first non-leaf node (which is second last node). Maximum number of nodes in each level is floor(n_total / 2^h+1). (h is the height of the tree). Then we can calculate this… 1 * n/4 + 2 * n/8 + 3 * n/16 + … + h * n/2^(h+1).. then n/4 {1 + 2/4 + 3/8 + 4/16 + … + h/2^(h-1)}.. then n/4 {1 + 1/2 + 1/4 + 1/8 + … + 1/2^(h-1)}.. then n/4 {1 / (1 - 1/2)^2} = n. (1/(1-x)^2) = sigma(n *x^(n-1)). This is why it is O(N).
Heap Implementation
structMaxHeap{vector<int>heap;MaxHeap(){heap.resize(1);// heap 은 무조건 1 부터 시작, 안보이는 0 이 존재}// ---- priority queuevoidpush(intx){intindex=int(heap.size());heap.push_back(x);siftUp(index);}voidsiftUp(intindex){for(inti=index;i>1&&heap[i/2]<heap[i];i/=2)// O(logN)swap(heap[i/2],heap[i]);}inttop()const{returnheap[1];}boolpop(){intN=int(heap.size());if(N<=1)returnfalse;swap(heap[1],heap[N-1]);heap.pop_back();siftDown(1);returntrue;}voidsiftDown(intindex){intN=int(heap.size());cout<<N<<endl;for(inti=index,j=index*2;j<N;i=j,j*=2){if(j+1<N&&heap[j]<heap[j+1])j++;if(heap[i]>=heap[j])break;swap(heap[i],heap[j]);}}voidheapify(constintarr[],intsize){heap.resize(1);heap.insert(heap.end(),arr,arr+size);for(inti=size/2;i>=1;i--)siftDown(i);}};
The interesting fact about this heap.
Let’s mark that the parent heap is denoted as i, then child on left is i * 2, and right is i * 2 + 1. If you actually draw the tree, parent node is 0001, then left child is 0010, and right child is 0011. then parent node is 0100, left child is 0101, and right child is 0110. then parent node is 0111, left child is 1000, and right child is 1001. then parent node is 1010, left child is 1011, and right child is 1100.
This is interesting! Why? from the parent node, the resulting of left child is shifting left by 1, and right child is shifting left by 1 and adding 1. Then we can back track how many parent nodes are from the child node. For example, if node 9 is 1001, remove MSB, 001. We can see that 0(left)->0(left)->1(right) in that direction, so we have three parent nodes from child node 9.
In the next post, I will show you the leet code problem that uses this heap property.
intdietPlanPerformance(vector<int>&calories,intk,intlower,intupper){intpoints=0;intcurrent_sum=0;for(inti=0;i<calories.size();i++){current_sum+=calories[i];// 일단 현재의 Current Sum 을 구한다.if(i-k>=0){// 만약 윈도우 사이즈를 넘어가면, 왼쪽 원소를 빼준다. 즉 이말은 즉슨, k = 1 이면 전에 있던 0 을 빼줘, 1 만 보게끔 하는것이다. current_sum-=calories[i-k];}if(i-k+1>=0){// 윈도우의 시작점 Index 다. k = 2 라고 하면, i - k + 1 = 0 이, 0 부터 만들어진다는 뜻이다. if(current_sum<lower){points--;}elseif(current_sum>upper){points++;}}}}
Review
하… Easy 라고 했는데 오랜만에 하니까, Sliding Window 문제가 생각이 안나서 좀 헤맸다. Sliding Windows 라는건 Array[i] 가 있다고 하면, w size 만큼 윈도우를 옮겨가면서 처리하는 문제를 말한다.
Given the root of a complete binary tree, return the number of the nodes in the tree.
According to Wikipedia, every level, except possibly the last, is completely filled in a complete binary tree, and all nodes in the last level are as far left as possible. It can have between 1 and 2h nodes inclusive at the last level h.
Design an algorithm that runs in less than O(n) time complexity.
You can use the priority queue to solve this problem or use the property of the complete binary tree.
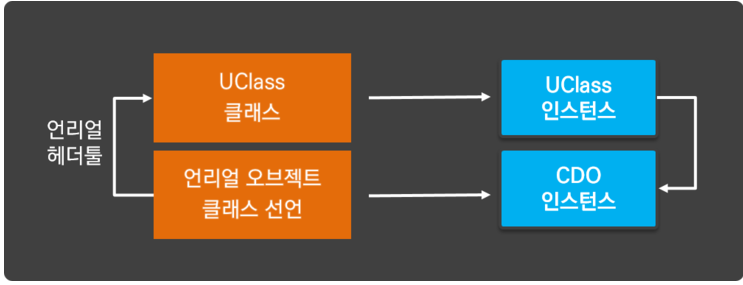
Unreal Object 가 만들어지기 위해서는, 실제 컴파일 전에 Unreal Header Tool 에 헤더 파일 분석하는 과정에서 선행이 되며, 이 과정이 완료되면, Intermediate Folder 에 Unreal Object 정보를 담음 Meta File 이 생성 된다.
이 Meta 정보는 Unreal Engine이 지정한 UClass 라는, 특별한 클래스를 통해서 보관됩니다.
UClass 에는 Unreal Object 에 대한 클래스 계층 구조 정보와 멤버 변수, 함수에 대한 정보를 모두 기록하고 있습니다.
하지만 단순히 검색하는 것에서 더 나아가, Run Time 에서 특정 클래스를 검색해 형(Type) 을 알아내 인스턴스의 멤버 변수 값을 변경하거나 특정 인스턴스의 member function 호출하는것이 가능하다.
Reflection
Java / C# 과 같은 경우 Reflection 이라는 이름으로 제공
Compile 단계에서 Unreal Object 마다 UCLass 가 생성된다면, 실행 초기의 Run Time 과정에서는 Unreal Object 마다 Class 의 정보와 함께 Unreal Object 의 Instance 가 생성됩니다.
이 특별한 Instance 는 Unreal Object 의 기본 세팅을 지정하는데 사용되는데, 이를 클래스 기본 객체 (Class Default Object: CDO) 라고 한다.
Unreal Engine 에서 CDO 를 만드는 이유는 Unreal Object 를 생성할 떄마다 매번 초기화를 시키지 않고, 기본 인스턴스를 미리 만들어 놓고 복제하는 방식으로 메커니즘이 구성되어 있기 때문이다.
예를 들어서 복잡한 기능을 수행하는 캐릭터를 담당하고, 기능이 커진다고 했을때 굉장히 큰덩어리로 될수 있다. 이럴때 100 개의 instance 를 만든다고 가정하면, 캐릭터를 하나씩 처음부터 생성 하고, 초기화 시키는 방법보다, 미리 큰 기본 객체 덩어리를 복제하고, 속성 값만 변경하는게 더 효율적이기 때문이다.
정리하자면, 아래와 같이 하나의 Unreal Object 가 초기화 될 때에는 두개의 Instance 가 항상 생성 됩니다.
이 생성자 클래스는 Instance 를 초기화 해 CDO 를 제작하기 위해서 사용되고, 초기화에서만 실행되고, 실제 게임 플레이에서는 생성자 코드를 사용할 일이 없다.
Unreal Engine 에서 게임 플레이에서 사용할 초기화 함수는 생성자 대신 Init() 이나 혹은 BeginPlay() 함수를 제공
위의 코드는 cardianl 이라는 std::vector<int> 타입이 존재 했을때, const_iterator type 으로 begin 과 end 를 각각 iter 와 iter_end 로 변수로 지정해놓았다. 그리고 while 문 에서는 total element 에다가 vector 에 있는 모든 int 을 곱해서 결국은, 벡터의 모든 원소들의 곱을 나타낸다.
이런 방법도 있지만, 조금 더 Modern C++ 로 다른 방법으로 해결한다면 Functor 를 이용할수 있다.
하지만 위의 코드는 product 라는 struct 를 만들고, for_each 로 while 문을 대신해서 사용된다. 하지만 struct 에 대한 operator 그리고 constructor 를 지정하므로 코드가 생각보다 길어진다. 그렇다면 어떻게 더 간단하게 만들수 있을까? 아래의 코드를 보자. 아래의 코드가 바로 lambda 로 구성한 코드이다.
각각의 부분은 introducer(capture), parameters, return type, statement 로 구성이 되어있다. introducer 같은 경우는 [] 안에 있는 my_mod 라는 변수를 람다 내부에서 사용할 수 있게 된다. 그리고, parameter: () 안에서는, 받을 인자를 적게 되는데 위의 예에서는 int 형을 가지고 와서 lambda 내부에서 사용할 수 있게 된다. trailing_return type 같은 경우는 따로 말하지는 않겠다. 이런 한 lambda 식을 결국은 쓰게된다. 여기서 바로 closure 과 lambda expression 에서 이야기를 하게 된다.
lambda expression 을 쓰긴 하지만, Runtime 에는 이름이 없지만, 메모리 상에 임시적으로 존재하는 Closure 가 생성이된다. 예를 들어보자. 아래의 = 옆에 부분에 lambda expression 이 있다고 가정하면, 결국 Runtime 에 closure 가 생성이되고, f 는 closure 에 대한 복사값이 될것이다. 물론 closure 를 복사하는 부분은 std::move 로 넘길수 있지만 f 가 closure 는 아니다.
autof=[&](intx,inty){returnfudgeFactor*(x+y);};
실제 closure object 는 이 statement 가 끝났을때, 파괴된다. 즉 closure 과 lambda 의 차이는 정확하게 클래스와 클래스 인스턴스의 차이인거다. 결국 class 같은 경우는 정의를 한거고, closure 는 class 의 instance 이다. 결국 class 는 소스코드에만 존재하고, runtime 에서는 존재 하지않고, class instance 들은 run time 에 존재하게 되는것들이다.
사실 나는 자율 주행과는 조금 가깝지도 멀지도 않은 직종에서 Simulator 와 그의 부가 되는 내용들을 개발을 하고 있다. 물론 실제 차량에 쓸수 있을지는 전혀 알지도 모르고, on-time 으로 뭔가를 할수 있다는것과도 거리가 멀지만, Autonomous Vehicle Simulator 이기에 또 가깝기도 하다. 그래서 뭔가 개요? Perception 에 대한 대체적인 것 들을 배우기 위해서 이 강의를 듣게 됬다. 그리고 SOS Lab 의 이용이님과 bitsensing 이재은, Seoul Robotics 의 이한빈님들의 알려주는 이야기를 짧게 또는 개요를 듣고 싶어서, 이 강의를 선택하게 되었다.
대부분의 이야기는 Perception 에 살짝 치우쳐져 있다는 느낌이 있었고, 인지 부터 시작해서 제어까지의 총 통틀어 하나로 나오는 Fullstack 은 어떻게 진행하고 있는지와 그리고 자율 주행에서의 큰 문제점을 어떻게 해결할지 (Perception Module 에서 부터 센서 퓨전 한 이후에 Command 까지 보내주는데에 있어서의 Latency 를 줄여야한다.) 등을 이야기 했고, Data-Driven 이 rule-based 보다 좋을수 밖에 없다라는 말도 조금 받아들이기는 쉽지 않았다.
일단 센서의 종류 부터 보자면, 아래와 같다. 딱히 HDmap 은 센서의 종류라고 말은 할수 없지만, 또 자율주행에 있어서 빼놓을수 없는 것이다.
Camera
Lidar
Radar
GPS / IMU
Hdmap
즉, 자율 주행 자동차가 주변 환경을 인지해 주행에 필요한 정보들을 획득 및 취득하고, 그리고 이렇게 다양한 센서가 필요한 이유는 각 센서별로의 장단점이 있기 때문이다.
GPS
차량의 위치를 위성으로 부터 지구 좌표계의 절대 위치 정보(lat, long, altitude)를 받아온다.
1 ~ 10 HZ 의 느린 주기를 가지고 있다.
지하 / 터널 / 도심등에서 음영 지역이 발생한다.(***)
일반적인 GPS 는 수 m 오차가 있으므로, 자율주행에서는 부적합하다. (DGPS, GPS-RTK 사용)
(***) GPS 의 단점이므로 이걸 해결하기 위해서는 IMU 의 센서가 보완할수 있게 이용된다.
IMU
결국엔 차량의 위치를 절대적 좌표만으로 볼수 없기 때문에, 차량의 가속도, 각속도, 지자기 를 측정해서 자기의 위치를 판단할수 있게 한다.
200 HZ 이상의 빠른 주기 이다.
추측 항법을 통해 이동 거리 및 방향 추정 가능
외부 환경에 대해서 강건하나, 시간에 따른 누적 오차가 발생한다.
HD Maps (센서 X)
IMU 와 GPS 들의 단점을 마지막 매칭하기 위해서, 자율 주행 차량이 필요한 도로 정보를 정밀하기 기록 되어있늕 지도
도로 규칙이나 도로의 형상, 교통 정보, 센서 데이터등이 포함도니다.
Camera
개체 인지 및 위치 추정에 활용
풍부한 텍스처 정보를 포함
30 ~ 60 HZ 의 빠른주기
HD 급 카메라를 다수 장착해 FOV (Field of View) 확보.
조명 환경 변화에 취약, 정확한 깊이 추정 불가 (***)
RADAR
장애물 회피 및 충돌 감지에 활용
전자기파를 이용해 측정한 거리, 속도 정보를 제공
근거리와 원거리에 대해 모두 측정가능
눈, 비 조명 등 외부 환경에 강건
작은 물체 측정에 취약, 낮은 해상도. (4D Imaging RADAR 로 발전해 가는중)
LiDAR
개체 인지 및 위치 추정에 활용
레이저를 이용해 고해상도의 정확한 3차원 거리 정보 제공
10 ~ 20 Hz 의 주기
대상체에 대한 반사도 정보 제공
조명 환경 변화에 강건
눈, 비, 안개 등 약천후에 민감하고, 높은 비용
위와 같은 센서를 이용해서 하나의 모듈을 같이 쓰기도 하고, 다같이 쓰기도 한다. 하지만 LiDAR 에 대한 설명으로서는 아래와 같이 비교가 나와있다.
LiDAR 를 약천후가 제외한다고 하고, 많은 채널을 사용한다고 하면, 높은 해상도를 얻을수 있다고 한다. LiDAR 의 원리같은 경우는 빛의 이동 시간 (Time of Flight) 으로 측정하는 원리를 이용해서 높은 정밀도의 3차원 공간정보를 고속으로 획득할수 있다는거에 대해서 큰 장점을 가지고 있다. 대표적으로는 Velodyne 64 channel 이 있고, 이건 Scanning Lidar 인데, Scanning LiDAR 같은 경우 Motor 로 Physically 하게 돌아가게 때문에, 기계적인 요소로 인해서 Maintain 하기도 쉽지가 않아서 MEMS (Mirror Scanning LiDAR) 을 사용한다고 한다. 결국에는 빛을 Mirror 에 쏘아서 스캐닝을 한다고 한다. 물론 여기에는 단점이 있는게 FOV 이다. 그래서 여러대를 달아서 모아놓고 정합하는 작업을 후처리로 한다고 한다.
또 LiDAR 의 단점으로서는 Transmitter 에 있는데, 파장을 905 또는 1550 사이에서 적당하게 laser source 를 사용해야된다는거다. 파장을 905 를 사용하게 되면, 사람의 눈에 피해가되고, 1550 를 사용하게 되면 카메라가 파괴될수도 있다고 하기에 모든건 적절? 하게 사용해야한다라는걸 알게됬다.
Radar in Deep
RADAR (RAdio Detection And Ranging) RADAR 는 사실 학부때 들었었는데 기억나는건 RADAR 공식 밖에 기억은 안나지만 결국에는 전자기파를 송신해서, 물체에 반사된 수신신호를 통해 물체의 위치(거리, 속도, 각도)를 감지 할수 있다.
앞에서 말했던것 처럼 RADAR 의 장점으로서는 기후에대해서 굉장히 강건하다, 하지만 작은 물체에 대해서는 Detection 이 불가능하고, 이 물체가 있는지 없는지만 판별이 가능하지 이게 사람인지, 차선인지, 차량인지는 알수가 없다.
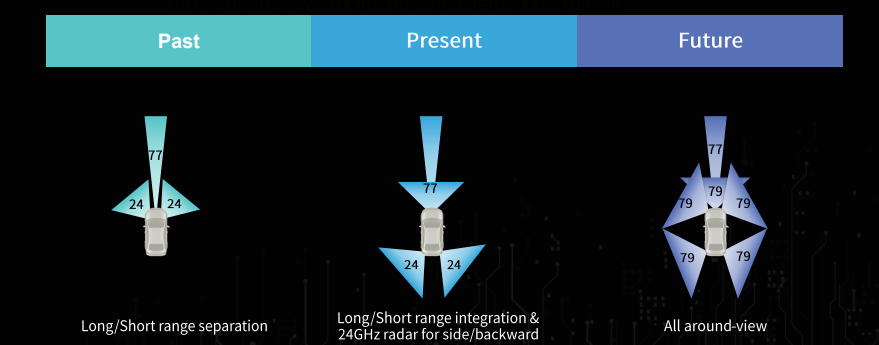
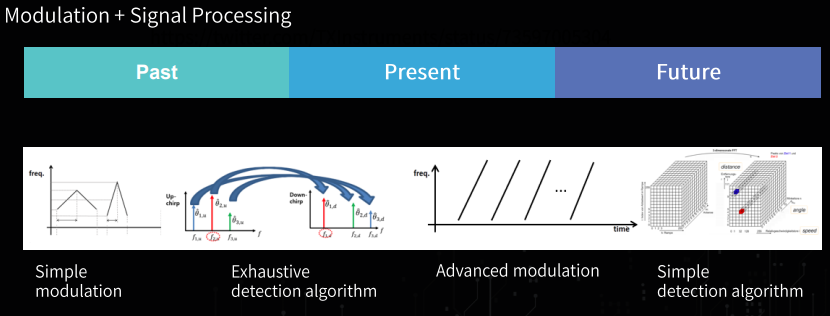
주로 사용되는 Frequency 는 77 GHZ (1Ghz Bw / 55dBm) 이고 나중에는 79 GHz(4GHz Bw, 55dBM, -3DBm/MHz) 정도 된다. 그리고 아래의 그림 처럼 현재와 미래에 대한 RADAR 가 달리는걸 보면 대체적으로 어떻게 RADAR 가 개발될지는 알수 있다.
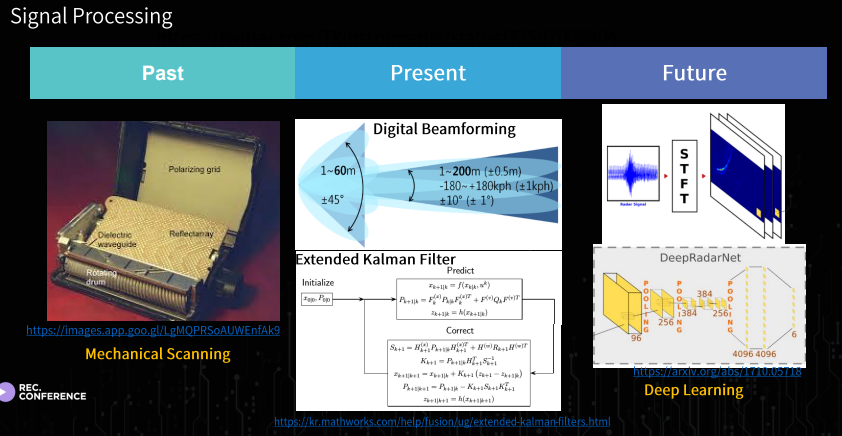
그리고 인지쪽을 결국에 하려면, Hardware 가 Support 가 되어야하며, 그거에따른 Modulation 과 Signal Processing 이 따로 필요하다는걸 강조하셨다. 또 여기서 볼수 있는건 결국엔 Data-Driven 의 강조가 보였다.
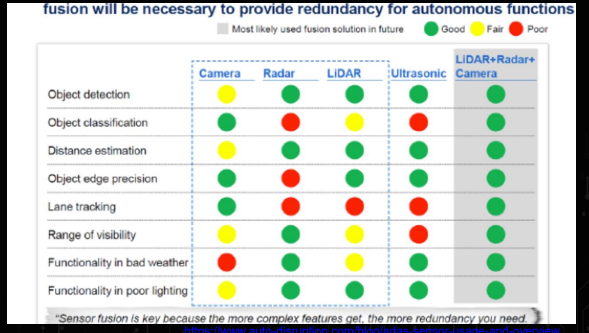
그리고 앞서 말했듯이 각 센서들의 단점들이 존재 하지만 결국엔 어떻게 쓰는지에 따라서 였는데, 앞에서는 LiDAR 로 해결할수 있는 부분이 있다고 말씀하셨지만, 이번 bitsensing 에 계시는 분은 Camera 와 Radar 두개를 한꺼번에 융합하는 시스템이 있다고 하면, 서로 단점을 더 잘보완할거다? 라는 말씀을 하셨다.
물론 자율주행이라는게, 굉장히 상용적이여야하면서, 완성이 되려면 보수적으로 볼수 밖에 없다고 한다.
사실 다른건, 조금 Career 적으로 인것같아서 적진 않겠지만, 그래도 좋은 자료와 어떻게 자율주행쪽에서 살아가려면 어떤게 필요하고, 어떤 마음가짐으로 임해야겠다라는 생각이들었다. 그래고 Data-Driven.. 정말 rule-based 를 선호했지만, 성능차이에서는 무조건적으로 좋을수도 있지만 이게 Model 이라는게 되게 Light 해야되고, 조금 더 사용할수 있게끔 될때까지는 오래걸리기에, 조금더 넓은 안목을 가지고 자율주행쪽으로 임하는 마음을 가지게 되었다.
정말 정말 2 년동안 이런일도 많고 저런일도 많아서, 글쎄? 어떤게 제일 나에게 좋은 선물을 할수 있을까? 할수 있었던데 바로 시애틀 여행이다. 뭔가 후회도 굉장히 많이 남는게, 미국에 있었을때, 여행을 같이 갈수 있었는데도 경제적 사정도 그렇고, 뭔가 부모님에게 덜 부담을 주기 위해서 생활비를 아껴야 한다라는 그런 부담감에 사로 잡혀 많이 하지 못했던 것도 있다. 그래서 이번엔 350 만원 정도 주고 미국, 시애틀에 다시 오게 되었다. 큰 설렘과 그리고 새로운 곳에 대한 무서움도 있었다.
첫날 (11/10/2023)
첫날은 시애틀에 도착했을떄는, 참 미국이 이런곳 이였지 하면서 화장실부터 느껴졌었다. 미국 화장실의 더럽고, 약간 순박한 그런것 들이 있었는데, 또 다시 보니 은근 반가웠었다. 그리고 도착해서 담배를 피면서, 미국에 대한 그리움이 점점 더 풀려가는것 같았고, 내가 진짜 이걸 하네? 그렇게 걱정도 많았고 탈도 많았었는데 이걸 하네? 이런 생각만 들었다. 캐리어를 가지고, 셔틀 버스에 올라 타는데 영어로 이야기하는게 정말 그래웠었나? 라는 생각들 들고, 그냥 스쳐 지나가는 말들도 귀에 꽃히더라. 확실히 나는 언어를 습득 한게 맞는것 같았다. 물론 완벽하지는 않지만, 아직 많이 부족한점도 굉장히 많은것 같다. 셔틀 버스에 내려서, 차 렌트를 하는데 200+ 600 불이 나와서 생각보다 많이 나왔다고 생각했다. 하지만 뭐 인슈어런스 드는것도 나쁘지는 않으니까? 어떻게 될지 모르니까? 이러면서 그냥 지나 보냈었다. 차를 타고, 호텔까지 찍는데 37 분이나 걸리는 거리였다. 내가 가는 곳은 Microsoft 옆 Redmond 라는 동네이다. 딱히 막 비싼곳도 아니고, 그렇게 도시에서 멀지도 않으니 숙박은 정말 잘잡은것 같다.
날씨는 흐리고 비가 왔었다. 축축하지만 운전하면서 보이는, 단풍나무랑 내가 미국에서 보지 못했던 언덕들 위의 집들은 정말 다 새로웠다. 와 대박? 그러면서 또 하는 생각은 나 미국인거 맞지? 나 이렇게 이런게 그리웠을까? 이렇게 차가 많은데도 운전하는게 즐거웠었던걸까? 정말 호텔가면서 뭔가 내가 진짜 잘왔구나? 이런 생각이 들었다. 호텔에 도착하자마자, 바로 미국에서 항상 짖는 나의 미소로 check-in 하고, 바로 방으로 들어와서 짐을 풀기 시작했다. 짐풀고 씻고, 누웠더니.. 밤 11시가 되버렸다?! 그래서 내가 대학원생때 진짜 많이 먹었던 two mac chicken & midium fries 를 먹으로 갔다. 근데? 와 확실히 물가가 거기에서 확 느껴지더라 원래는 6달러에 먹을수 있었던게 10 달라가 되버린거다. 시애틀이 물가가 비싸긴 하지만, 그래도 후회없이 뇸뇸하고 오늘 하루를 잘 끝냈다.
마지막 및 소감
항상 늘 똑같이 챗바퀴처럼 돌아갔던 삶을 잠시 내려두고, 여행을 온건 정말 잘한것 같다. 그리고 독립적으로 내 스스로 많은걸 했었다. 물론 그 과정들이 외롭고 무섭기는 했어도, 그리고 돈이 조금 들더라도, 큰 용기가 생겼다. 그리고, 항상 내가 스스로 결정이 아닌 환경에 의해서 나의 결정이 났었던것 같다. 내가 스스로 뭔가를 하려고 했지만, 늘 구체적인 계획을 세워서 실패와 실망감이 더많이 들었던것 같다 라는걸 알게되었다. 구체적인 플랜은 잠시 제쳐두고, 가볍고 추상적인 계획 부터 시작해서 하나씩 하나씩 붙여나가는걸 해야겠다라는 생각이 무척들었다. 물론 이 여정가운데서, 무서워서 운전하다가 손에 땀이 나고 그랬던 적이 여러번이였지만, 그만큼의 두려움은 결국 행복과 목표에 도달했을때의 성취감이 들더라. 후회는 남기지 않는 삶을 내가 만들어가야하겠다 라는 생각도 정말 많이 들었다. 감정을 잠시 제쳐두고, 내가 진짜 뭘하고 싶은지, 어떤 생각으로 내가 이런 저런것을 할수 있는지 부터 차근차근 살을 붙이는 작업을 해야겠더라. 미국의 삶 물론 외로운점도 굉장히 많고, 혼자 해내야할 산들이 정말 많았구나, 고생많았구나 라는 점도 많이 느끼고, 한국이랑 정말 다른점을 느끼게 되더라. 어느새는 내가 정말 한국인인가 보다 라는걸, 성급해서 맥도널드에 직접 찾아가서 버거 달라고 하는걸 보면 많이 한국 스러워졌다? 라고 말을 할수 있게되더라.
미국에 가는건 더 clearer 해졌다. 뭔가 나의 행복과 삶을 찾기 위해서는 이게 방법이다 라는걸 쌓게 되는 계기가 되고, 그리고 목표도 조금 뚜렸해졌다. 이제는 사람에 이끌어지지말고, 조금 필요한곳에 자존심을 세워서 자신감있게 해내야겠다라ㅏ는걸 생각 하게 되었다. 물론 지금 현재는 부족한게 많을수 밖에 없지만, 그래도 이게 하나의 계기가 되서 좋은 기억과 추억들이 나의 하나의 Journey 가 될수 있게 하는 계기가 되서 좋았다. Having a freedom in my life is supposed to be getting out of comfort zone 이 맞는 말이라는걸 알게 되서 정말 좋은것 같다. 여행을 시작하기전과 여행을 끝내고 나서의 나의 모습들이 좋게 달라졌으면 하는 바램으로, 이번의 시애틀 여행을 잘 맞춘다.
Sensor 에는 Camera, Radar, Ultrasound, and Lidar 가 있다. Camera 같은 경우는 Lateral 의 정보들을 우리가 보는 View 에 들어오고, 그 View 에는 수많은 Pixel 정보들을 가지고 있다. Radar 같은 경우에는, Distance 의 정보들을 가지고 올수 있으며, 특히 Velocity 정보들을 가지고 올수 있기 때문에 driver assistance system 에 들어가는 “adaptive cruise control” 이나 “autonomous emergency braking” 등 사용이 간다. 일단 Radar 같은 경우 electromagnetic wave 를 쏴서, 어떤 물체에 부딫혔을때, run-time of the signal 을 받아서 distance 의 값을 가지고 올수 있으며, Dopller effect 로 인해서, 물체의 움직임의 frequency shift 를 활용해서, velocity 를 구할수 있다. Camera 와 달리 weather condition 에 영향을 받진 않지만 low spatial resolution 을 가지고 있다. 그 영향은 Metal 같은 Object 가 아닐경우 다 refracted 된다고 한다면, 그 signal 은 약한 return signal 이 기 때문이다. [참고: radar 는 24GHz radar sensor 가 있는데, 이건 wider 하며, Long Range radar sensor 같은 경우 77GHz 가 있다.]
그다음은 최신 기술인 Lidar Sensor 이다. Lidar 는 beams of laster light 을 쏴서, object 로 부터 bouncing 한 시간을 기록한다. 이렇게 보면 Radar 랑 비슷하지만, 일단 Lidar 는 360 degree arc 를 쏴서, 3D point maps 에 대한 정보를 per second 당 Measure 을 한다.
너무 비싸다른것(lowering the price per unit)
Decreasing package size
Increasing sensing range and resolution
등이 존재한다. 그래서 LiDAR 의 Alternative approach 는 non-scanning sensor(Flash Lidar) 를 사용하는건데, 여기서 “Flash” 라는 거는 FOV(Field of View) 에 Laser source 를 한번 다쏘는식이다. 마치 필름카메라가 사진을 찍을때처럼 빛을 한번 뽱 싸주는거고, 쏴서 reflected laser pulse 만 가지고 오면 된다. 하지만 FOV 가 정해져있으니, narrow field 와 limited range 를 들고 있다는점이 drawback 이다. 그래서 우리가 실제 보는건 Roof-mounted scanning Lidar 를 사용하고 4 쪽 사이드에 사용되는건 non-scanning lidar sensor 를 사용한다.
간단한 Sensor Criteria 를 인용된걸 써보려고 한다.
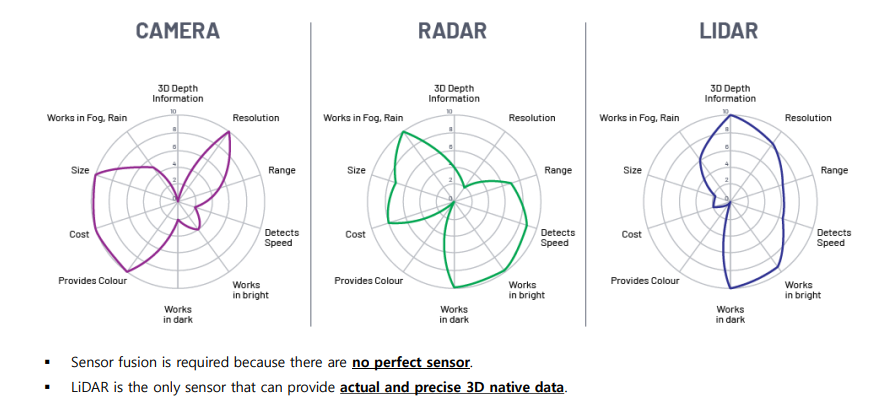
Range : LiDAR and radar systems can detect objects at distances ranging from a few meters to more than 200m. Many LiDAR systems have difficulties detecting objects at very close distances, whereas radar can detect objects from less than a meter, depending on the system type (either long, mid or short range) . Mono cameras are not able to reliably measure metric distance to object - this is only possible by making some assumptions about the nature of the world (e.g. planar road surface). Stereo cameras on the other hand can measure distance, but only up to a distance of approx. 80m with accuracy deteriorating significantly from there.
Spatial resolution : LiDAR scans have a spatial resolution in the order of 0.1° due to the short wavelength of the emitted IR laser light . This allows for high-resolution 3D scans and thus characterization of objects in a scene. Radar on the other hand can not resolve small features very well, especially as distances increase. The spatial resolution of camera systems is defined by the optics, by the pixel size on the image and by its signal-to-noise ratio. Details on small object are lost as soon as the light rays emanating from them are spread to several pixels on the image sensor (blurring). Also, when little ambient light exists to illuminate objects, spatial resolution decreases as objects details are superimposed by increasing noise levels of the image sensor.
Robustness in darkness : Both radar and LiDAR have an excellent robustness in darkness, as they are both active sensors. While daytime performance of LiDAR systems is very good, they have an even better performance at night because there is no ambient sunlight that might interfere with the detection of IR laser reflections. Cameras on the other hand have a very reduced detection capability at night, as they are passive sensors that rely on ambient light. Even though there have been advances in night time performance of image sensors, they have the lowest performance among the three sensor types.
Robustness in rain, snow, fog : One of the biggest benefits of radar sensors is their performance under adverse weather conditions. They are not significantly affected by snow, heavy rain or any other obstruction in the air such as fog or sand particles. As an optical system, LiDAR and camera are susceptible to adverse weather and its performance usually degrades significantly with increasing levels of adversity.
Classification of objects : Cameras excel at classifying objects such as vehicles, pedestrians, speed signs and many others. This is one of the prime advantages of camera systems and recent advances in AI emphasize this even stronger. LiDAR scans with their high-density 3D point clouds also allow for a certain level of classification, albeit with less object diversity than cameras. Radar systems do not allow for much object classification.
Perceiving 2D structures : Camera systems are the only sensor able to interpret two-dimensional information such as speed signs, lane markings or traffic lights, as they are able to measure both color and light intensity. This is the primary advantage of cameras over the other sensor types.
Measure speed : Radar can directly measure the velocity of objects by exploiting the Doppler frequency shift. This is one of the primary advantages of radar sensors. LiDAR can only approximate speed by using successive distance measurements, which makes it less accurate in this regard. Cameras, even though they are not able to measure distance, can measure time to collision by observing the displacement of objects on the image plane. This property will be used later in this course.
System cost : Radar systems have been widely used in the automotive industry in recent years with current systems being highly compact and affordable. The same holds for mono cameras, which have a price well below US$100 in most cases. Stereo cameras are more expensive due to the increased hardware cost and the significantly lower number of units in the market. LiDAR has gained popularity over the last years, especially in the automotive industry. Due to technological advances, its cost has dropped from more than US$75,000 to below US$5,000. Many experts predict that the cost of a LiDAR module might drop to less than US$500 over the next few years.
Package size : Both radar and mono cameras can be integrated very well into vehicles. Stereo cameras are in some cases bulky, which makes it harder to integrate them behind the windshield as they sometimes may restrict the driver's field of vision. LiDAR systems exist in various sizes. The 360° scanning LiDAR is typically mounted on top of the roof and is thus very well visible. The industry shift towards much smaller solid-state LiDAR systems will dramatically shrink the system size of LiDAR sensors in the very near future.
Computational requirements : LiDAR and radar require little back-end processing. While cameras are a cost-efficient and easily available sensor, they require significant processing to extract useful information from the images, which adds to the overall system cost.
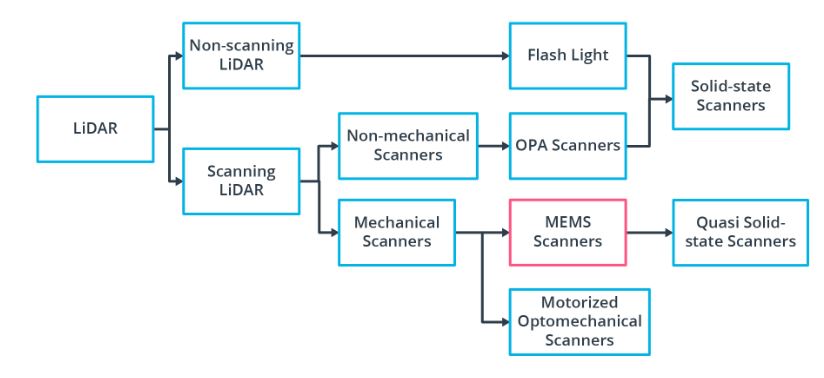
Available Lidar Types
일단 Lidar Type 중에 Scanning LiDAR 중에서 Motorized Optomechanical Scanners 가 most common 한 LiDAR Type 중에 하나이다. Velodyne 에서 만들어졌으며, 64-beam rotating line scanner 이다.
이 LiDAR 의 장점을 List-up 해보자면, 아래와 같은 장점을 가ㅣㅈ고 있으며, 이런 LiDAR 을 가지고 있는 Type 은 transmitter-reciever channel이 존재하고 360 도의 FOV 를 가지고 있고, Receiver 와 Emitter 가 Vertically 하게 잘싸옇져있다.
Long Ranging Distance
Wide Horizontal FOV
Fast Scanning Speed
물론 high-quality 의 Point-Cloud data 를 얻을 수 있는 반면, 이거에 따른 단점도 존재한다. 일단 High Power Consumption, Physical 한 충격에 대한 민감한 정도, 그리고 마지막으로 bulky 하기 때문에 high price 라는 단점을 가지고 있다.
다른 한종류로는 Non-Scanning Flash Lidar 가 있다. 일단 Non-Scanning 에서 알아볼수 있듯이, sequential reconstruction 을 할수 있는게 아니라, camera 처럼 flash 를 data 수집하는 원리이다. 어떤 Array 에서 광선이 나와서, 각 Element 들이 tof receive 를 하는 방식이다. 즉 이때에 각 Pixel 값들이 하나 나온다. 이 부분 같은경우는 2D 를 Rasterization 하는 기법과 비슷하다.
일단 vibration 에 robust 하지만 단점이라고 하면, 한번 Flash 했을때, 전체의 Scene 이 들어와야하므로 Beam 을 쏠때의 큰 Energy 지가 필요하다. 하지만, 이러한 Energy 를 줄이려고 한다면, Receive 할때의 SNR 도 고려해야한다.
그 이외에 Optical Phase Array (OPA) 및 MEMS Mirror-based Quasi Solid-State LiDAR 가 존재한다.
LiDAR
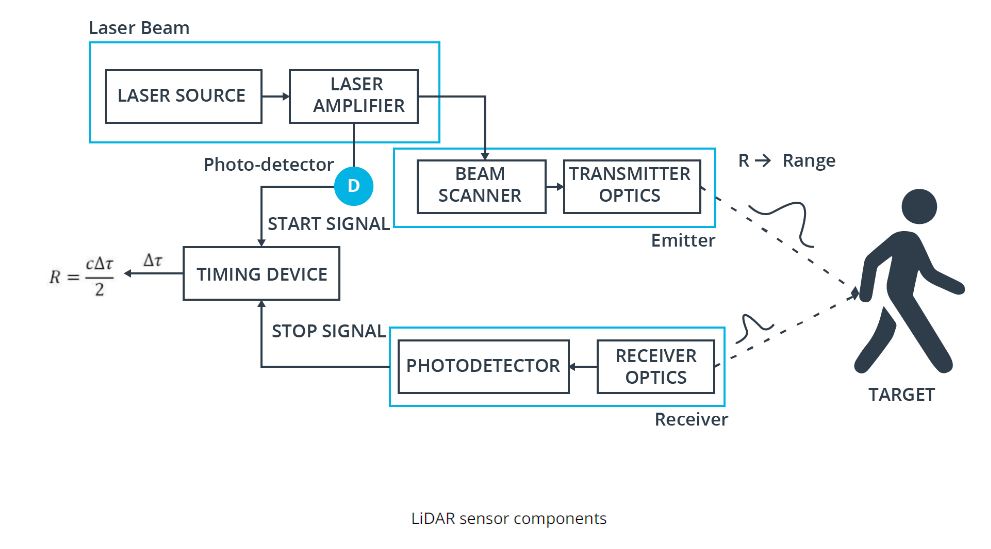
일단 Most Common Lidar Sensor 는 “pulsed Lidar” 이다. a laser source 로 부터 laser beam scene 으로 burst or emit 한 이후에, 어떤 물체에 부딫혔을때, 굴절되거나 반사를 통해서 LiDAR 의 receiver 로 도착한다. time of flight 을 구하기 위해선, range R (distance) 를 구할수 있는데, 바로 공식은 R = (1/2n) * c * (delta t). 여기서 c 는 speed of light 이고 n 은 eta 라고 부르기도 하며 1.0 이라고 가정한다.
typical lidar sensor 의 Pipeline 을 한번 봐보자.
Laser source 로 부터 burst 할수 있게끔 Amplifier 르 ㄹ 해준다. 이럴때 laser 의 pulse 는 picoseconds 나 nanoseconds 정도 generate 이 도니다. 그런다음 beam scanner 와 transmitter optics 의 도움을 받아 Target 에다가 쏜다. 그런다음에 어떤 물체에 부딫혔을때, scatter 된 pulse energy 가 receiver lens 에 도착한이후에 amplify 가 되고, voltage signal 로 변경한다.
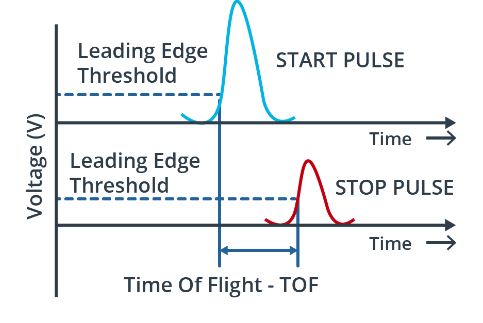
아래의 그림은 time of flight 을 구하는 부분을 그래프로 표현한거다.
Lidar Equation
Lidar Range Map
아래의 그림을 보면 Lidar 데이터가 왼쪽에서는 앞 차량의 뒷부분이 보이고, 전혀 차선(Lane) 또는 Road Surface 들이 보이지 않는다.
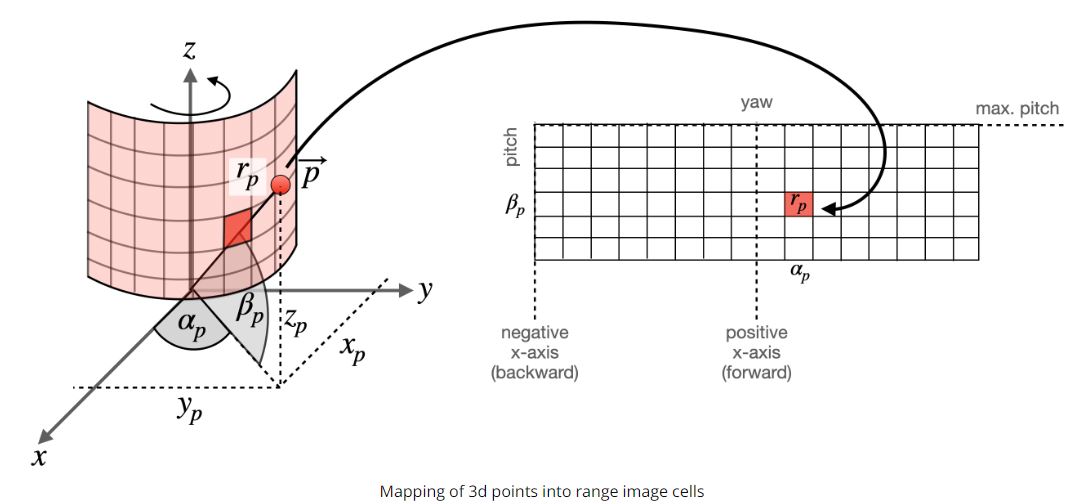
이런 Lidar scan 을 보는 방법중에 하나가 봐로 Range Image 이다. 이 Range Image 의 Data Structure 은 image 처럼 이지만 Lidar sensor 에서 한번 돌린 이미지라고 볼수 있다. 아래의 그림을 한번 보자.
일단 row 의 정보는 elevation angle, pitch 에 대한 정보가 있고, column 정보에는 azimuth angle, yaw 의 정보를 담고 있다. 즉 감아져있는 원통을 한번 쭉 펼치는것과 마찬가지이다. 그리고 각 Element 에는 intensity 들을 가지고 있다. 여기에서 alpha p 는 yaw 라고 하며, beta p 는 pitch 라고 한다.
Waymo Dataset
Range Image
Waymo Dataset 같은 경우, 고해상도의 다양한 센서(Lidar / Radar / Lidar) 들로 Dataset 을가지고 있다. 주로 밀집된 도시중심이나 풍경, 그리고 날씨의 변화에 따른 다양한 환경에서 센서데이터를 가지고 있다. 내가 실제로 받은 데이터의 version 은 1.2 이다. 그리고 이 dataset 을 사용하려면, WaymoDataFileReader tool 를 사용해서, waymo dataset 을 읽은 이후에 객체의 형태로 들고 올 수 있다.
일단 간락한 설명을 하기위해서, training 만 봐보도록 하자. training 안에 여러개의 Camera Label Segment 가 존재하고, 그 하위에 Lidar / Radar / Camera 의 정보들을 가지고 있다. 예를 들어서 Top Lidar 를 가지고 오려면, 아래의 Python Code 를 사용하면 된다.
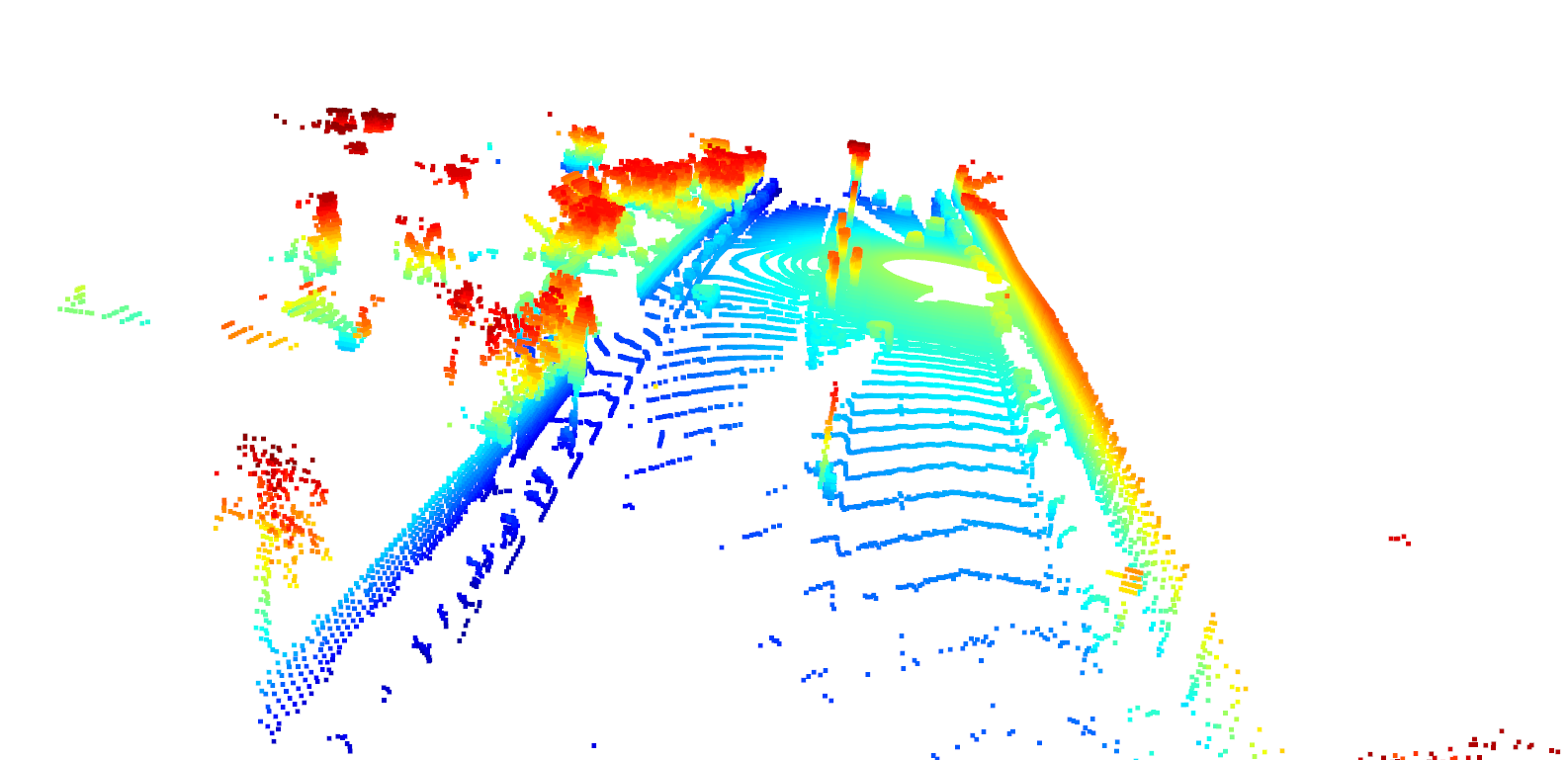
결국엔 이 Dataset 을 하기 위해선, Point Cloud Data 로 가지고 와야하지만, 여기에서 Point Cloud Data 이외에 표현하고 Visualize 를 하기 위해서는, 위의 Range Map 을 사용하면 된다. 여기에 Waymo Dataset 에서 한 Frame 당 구하기 위해선, 하나의 Frame 을 Matrix 로 변환이후에 reshape 을 해주면 shape (64, 2650, 4) 가 나온다. 아래의 코드는 Top Lidar 를 가지고 와서 Dimension 을 확인할수 있다.
Waymo Dataset 의 Range Image Structure 는 range, intensity, elogation, and vehicle position 을 가지고 있다. 그리고 Waymo dataset 에 elogation 값이 높고, intensity 가 낮은걸 날씨를 나타낼때 나타난다고 제시한다. 이 Range Image Structure 에서 내가 궁금한건 range 와 intensity 가 사용할것이다. 아래와 같이 Range Image 를 한번 확인 해보자.
Waymo Dataset 에서 사용된 Top Lidar 같은 경우 Scanning Lidar 이므로 Horizontal Field of View 는 360 degree 를 가지고 있다. 즉 360 / 2650 을 나눠보면 약 0.1358 만큼 degree 만큼 움직였으며, 이걸 Angular Resolution (min) 변환하면, 8.8 정도를 가지고 있다. 하지만 Vertical Field of View 에서의 Vertical Resolution 도 구하는게 필요하다. 즉 Minimum 부터 maximum inclination 을 확인해야므로, pitch 를 구해야한다.
Python 으로 구해보자면 아래와 같다. 여기서 max 와 min 을 빼줘서, 64 의 채널로 나눠준 각도를 구해주는 것이다.
Range Image 이의 Range 의 Value 값들은, 환경속의 특정 포인트까지의 거리를 2D 이미지로 담아냈기때문에, 센서부터 거리(distance) 를 말한다. 근데 여기에서 min = -1 일때가 있는데 geometrically 하게 make sense 하지 않는다. 그래서 Filter 를 한번 해줘야한다. 자세한 내용은 Waymo Dataset Paper 을 참고하자. 일단 이부분을 구현한 부분은 아래와 같다.
defload_range_image(frame,lidar_name):lidar=[objforobjinframe.lasersifobj.name==lidar_name][0]ri=[]iflen(lidar.ri_return1.range_image_compressed)>0:# use first response
ri=dataset_pb2.MatrixFloat()ri.ParseFromString(zlib.decompress(lidar.ri_return1.range_image_compressed))ri=np.array(ri.data).reshape(ri.shape.dims)returnridefget_max_min_ranage(frame,lidar_name):ri=load_range_image(frame,lidar_name)# ri[:, :, 0] -> range
# ri[:, :, 1] -> intensity
ri[ri<0]=0.0print('max. range = '+str(round(np.amax(ri[:,:,0]),2))+'m')print('min. range = '+str(round(np.amin(ri[:,:,0]),2))+'m')
그 이후에 Range Image 를 Visualize 하기 위해서는 Range 의 Channel 을 살펴보아야한다. Range Image Structure 의 Shape 은 (64, 2650, 4) 이였다. 여기에서 할수 있는 방법은 Normalize 를 한이후에 8 bit grayscale image 로 다루어야한다. 그 이후에 OpenCV 를 사용해서 image_range 를 볼수 있다. 하지만 Range Image 는 Lidar 의 Full Scan 이미지를 가지고 있으므로, 차가 바라보는 방향만, ROI 를 정해줄수 있는게 필요하다. 여기에 Waymo Dataset Paper, 명시된것 처럼 -45 ~ +45 도 만큼을 잘라낼 필요가 있다.
아래의 코드는 위의 내용을 기반으로 -45 도와 45 도의 Range 를 가지고 Crop 한 Image 를 구하는 방식이다. range_image 의 결과의 이미지가 이싿.
Range Image 이외에 살펴봐야하는 부분이 바로 Intensity 부분이다. 결국 Lidar 는 64개의 Channel 을 쏘았을때, 물체에 부딫쳐서 돌아왔을때의 색깔을 결정하기 위한 Intensity 들을 Return 한다. 그리고 이러한 Range Intensity 를 가지고, 우리가 Detection Algorithm 을 사용할수 있게끔 Point Cloud 가 나오게 된다.
일단 min-max normalization 으로 그렸을때, 아래와 같이 나올수 있다. 이렇게 나온 이유는 reflective material 을 가지고 있는건 그대로 Intesnity 를 Return 할 경우가 있는데, 이때 intensity 가 엄청 밝은것과 어두운것은 확죽이는데 적당하게 밝은 애들은 Noise 들을 더키우기 때문이다. 그래서 heuristic 방법을 사용하면, 아래처럼 scaling 을 할수 있다. 이때 사용한 scaling 방법은 Contrast adjustment 이라고 한다.
그래서 위의 내용을 적용하면 아래와 같이 사진이나오는데, 차량의 licence plate 가 reflective 하기 때문에 차량의 뒷편에 intensity 가 높은걸 확인할수있다.
defvisualize_intensity_channel(frame,lidar_name):ri=load_range_image(frame,lidar_name)ri[ri<0]=0.0# map value range to 8 bit
ri_intensity=ri[:,:,1]# get intensity
ri_intensity=ri_intensity*255/(np.amax(ri_intensity)-np.amin(ri_intensity))img_intesnity=ri_intensity.astype(np.uint8)deg45=int(img_intensity.shape[1]/8)ri_center=int(img_intensity.shape[1]/2)img_intensity=img_intensity[:,ri_center-deg45:ri_center+deg45]cv2.imshow("img",img_intensity)cv2.waitKey(0)
다시 말해서, 우리가 결국 range_image 로 부터 구하고 싶은건 Point cloud 를 return 하는 거다. range image 에서 point cloud 로 변경하려면, range image 에서 어떠한 point 를 spherical coordinate 에서 world coordinate 로 변경해야한다.
일단 Range Image 로 부터 Point Cloud Data 를 가지고오려면, 위에 했던 내용을 결국은 사용해야하며, Calibration Data 를 Waymo Dataset 에서 가져와야한다. 그리고 결국엔 vehicle 이 x axis 로 보게끔 range image 를 correction 을 거쳐야한다. 이때, extrinsic calibration matrix 를 가지고 와야한다.
아래는 Python range_image 를 Point Cloud 변경하는 코드이다.
calibration 을 하기 위해서, calibration data 를 가지고 온다.
그 data 에서 extrinsic matrix 를 가지고 와서, azimuth 를 구해준다. 이때 값을 구할때, [1, 0] 과 xetrinsic[0, 0], spherical coordinates 에서 world coordinate 으로 변경한 Y 와 X 의 값이다.
실제 고쳐야되는 azimuth 가 있었다면 -180 부터의 180 까지에서 corrected 된걸 연산해준다.
Corrected 된걸 가지고, World Coordinates X, Y, Z 를 연산해줘서, 센서의 위치를 파악한다.
Sensor 위치가 나오면, extrinxisc 과 xyz_sensor 를 matrix multiplication 을 통해서 ego coordinate system 으로 변경한다.
Point Cloud Data 를 (64, 2560, 4) 변경시켜서, 일단 거리가 0 보다 작은것들은 row 로 masking 을 시켜서, filtering 을 한이후 0:3 까지의 값들은 가지고 온다.(3 의값은 1 –> Homogeneous Coordinates)
Point Cloud Data 를 그린다.
defrange_image_to_point_cloud(frame,lidar_name):ri=load_range_image(frame,lidar_name)ri[ri<0]=0.0ri_range=ri[:,:,0]# load calibration data
calibration=[objforobjinframe.context.laser_calibrationsifobj.name=lidar_name][0]# compute vertical beam inclination
height=ri_range.shape[0]inclination_min=calibration.beam_inclination_mininclination_max=calibration.beam_inclination_maxinclination=np.linspace(inclination_min,inclination_max,height)inclination=np.flip(inclinations)width=ri_range.shape[1]extrinsic=np.array(calibration.extrinsic.transofrm).reshape(4,4)azimuth_corrected=math.atan2(extrinsic[1,0],extrinsic[0,0])azimuth=np.linspace(np.pi,-np.pi,width)-azimuth_correctedazimuth_tiled=np.broadcast_to(azimuth[np.newaxis,:],(height,width))inclination_tiled=np.broadcast_to(inclinations[:,np.newaxis],(height,width))x=np.cos(azimuth_tiled)*np.cos(inclination_tiled)*ri_rangey=np.sin(azimuth_tiled)*np.cos(incliation_tiled)*ri_rangez=np.sin(inclination_tiled)*ri_range# transform 3d points into vehicle coordinate system
xyz_sensor=np.stack([x,y,z,np.ones_like(z)])xyz_vehicle=np.einsum('ij,jkl->ikl',extrinsic,xyz_sensor)xyz_vehicle=xyz_vehicle.transpose(1,2,0)idx_range=ri_range>0pcl=xyz_vehicle[idx_range,:3]pcd=o3d.geometry.PointCloud()pcd.points=o3d.utility.Vector3dVector(pcl)o3d.visualization.draw_geometries([pcd])pcl_full=np.column_stack((pcl,ri[idx_range,1]))returnpcl_full