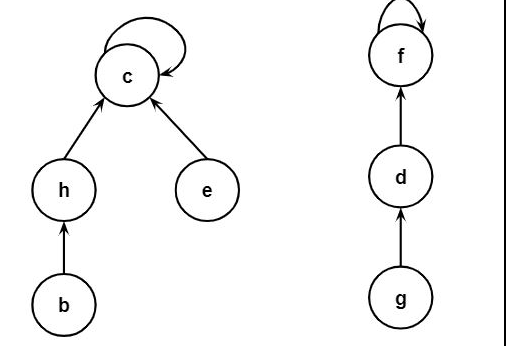
Given an array nums of n integers where nums[i] is in the range [1, n], return an array of all the integers in the range [1, n] that do not appear in nums.
Approach
I thought if you put all the numbers in Set, then it will make my life easier, so I created set, then if loop counter is not in, then append to outputs like below
Then I checked, and the time complexity was indeed O(n), but it took about 83 ms, which wasn’t what I wanted. One thing I was missing was considering the space complexity by switching to a set. However, as I looked at the hint, I realized that using the index itself was the key to improving performance.
One interesting aspect of the implementation below is that the elements at the corresponding index are marked as -1, indicating that the number exists somewhere, but the indices with positive values are the ones where the numbers do not correspond to their indices.
Reviewing what I studied, how this work will be explained as well.
Union-Find (Disjoint-Set) Concept
The Union-Find algorithm is used to manage disjoint-sets, which are collections of sets that are mutually exclusive, meaning they have no elements in common. This algorithm supports two primary operations: Find: This operation finds the representative element (root) of the set to which a given element belongs. Union: This operation merges two disjoint sets into one.
Disjoint-Set Tree
Disjoint-sets can be represented as a tree structure. Each node represents an element of a set, and child nodes point to their parents. The root node points to itself.
The Union-Find algorithm involves the following key operations:
Make-Set: Initializes all elements to point to themselves.
Find: Finds the root (representative element) of the set containing a given element.
Union: Merges two disjoint sets into one.
introot[max_size];// Similar to Make-Set functionfor(inti=0;i<max_size;i++){parent[i]=i;}intfind(intx){// O(1)if(root[x]==x){returnx;}else{returnfind(root[x]);}}voidunion(intx,inty){// O(N)x=find(x);y=find(y);root[y]=x;// set y's root to x's root}
Optimization on Find / Union.
But there are two issues in the code above. If the depth of tree is 6, and to find that root node, we have to recursively go through 6 steps. Simply, why do we have to take 6 steps to find the root node? can we just make depth 1, but connected to all node! Yes! we can certainly! this method is called path compression.
Another issue would be union. Let’s assume I have trees A and B. A has depth (3), and B has depth (6), Then would it better to merge B into A or A into B? It’s better to merge tree that have lower depth to greater depth. For example, if we put A into B, then the depth of union tree doesn’t change, but if we union B to A, you will get +1 depth in resulting tree. So this can be managed by the concept of rank, which is similar to depth.
The below algorithm has path compression and union by rank applied.
structUnionFind{vector<int>parent;// parent linkvector<int>rank;// depth informationUnionFind(intn):parent(n),rank(n,0){// set all element pointing to itself.for(inti=0;i<n;i++)parent[i]=i;// make-set}intfind(intx){if(parent[x]==x)returnx;}intmerge(intx,inty){intx_set=find(x);inty_set=find(y);if(x_set==y_set)returnx_setif(rank[x_set]<rank[y_set]){returnparent[xset]=yset;}else{if(rank[x_set]==rank[y_set])rank[x_set]++returnparent[y_set]=x_set;}}}
Time Complexity
Let’s look at the time complexity by the operation. makeSet is O(N) when n element is given. Find Operation is similar, but the worst case scenario it’s O(N). Since Union uses Find operation, it takes about O(N). Overall, it becomes O(N) times, but constant time O(a(n)) if path compression & union by rank. (a=> ackerman function).
Reviewing what I studied, how this work will be explained as well.
자, Kruskal Algorithm 은 Union-Find 을 사용해서, 알고르즘을 Process 하며, 결국에는 어떻게 최소의 weight 으로 모든 Vertex 를 연결 할지를 찾기 때문에, greedy choice 를 가져간다. Prim’s 와는 다르게, 전역 Edge 에 대해서 weight 별로 정렬을 한다. 그리고 Union(a, b) or Union(b,a) 를 진행하면서 disjoint-set 들을 만들어간다. 즉 Prim’s 와는 다르게 어떠한 Random 한곳에서 시작하는곳이 아니라 Weight 이 제일 작은 것부터 시작해서, 모든 Edge 별로 disjoint-set 을 만들어가며, Minimum spanning Tree 를 만든다.
생각보다 Union Code 를 활용해서, Path Compression 및 Union-by Rank 를 사용하면, 코드는 간단해진다. 물론 코드가 간단해지지만 Union-Find 가 있다라는 가정하에 이 모든 알고리즘이 쉬워진다고 볼수 있다.
Reviewing what I studied, how this work will be explained as well.
Greedy 는 뒷일을 생각하지 않고, 가장 좋아보이는것부터 하나씩 순서대로 처리한다는 의미 (즉 명확한 기준 하나를 정하고 그기준에 따라 미리 정렬을 한다음에 하나씩 처리)! 즉 문제의 크기가 줄어드는 현상이 있다. 문제의 크기가 줄어들기 때문에, 전체의 시간 복잡도가 정렬에 더 치중이 많이 간다. 최적화 문제를 다룬다는 입장에서의 비교! 를 해보자.
Dynamic Programming 안에서는, n 번째 아이템을 넣는다 안넣는다의 차이가 있고, 그거에 따른 n-1 의 선택 을 하는지 안하는지에 따라서 Tree 를 결정할수 있다. Greedy 는 분기를 고려하지 않는다. 가장 좋은 아이템이 있다면, 넣는다, 아니면 안넣는다. 라는 방식으로 분기를 고려할 필요가 없다.
Greedy 의 장점으로서는 1. 구현하기가 쉽고 빠르며, 문제에 따라서 결과가 최적이 아닐 경우가 있다는 소리가 된다.
정리하자면, Greedy Algorithm 에서는 당장 눈에 보이는 최적의 것을 쫓는 알고리즘이라고 할수 있다. 항상 최적은 아니지만, 어느정도의 최적의 근사값? 을 빠르게 구할수 있다라는게 된다.
단순한 문제중 하나는 바로 거스름 돈 문제이다. 항상 적은 양의 화폐를 주는게 제일 편하다. 즉 560 원이라는게 있다면, 10 원짜리 56 개를 주는것이 아닌 500 원짜리 하나, 50 짜리 1개 10 원짜리 1개를 주는것이 총 3개로 편하다. 즉 무조건 더 큰 화폐단위 만큼 거슬러 주는게 좋다라는것으로 생각해서 이 문제는 Greedy 알고리즘으로 풀 수가 있다.
이러한 문제 처럼 주로 무조건 긴대로, 많은대로, 짧은대로 라는 개념이 들어가서, Sort 기법이 들어간다. 대표적인 Kruskal Algorithm 이 될것 같다. 모든 간선을 정렬한 이후 짧은 간선부터 연결하는 MST 가 있을것 같다.
Activity Selection
defactivitySelection(start,end):ans=0finish=-1foriinrange(len(start)):ifstart[i]>finish:finish=end[i]ans+=1returnansdefactivitySelectionNotSorted(start,end):ans=0arr=[]foriinrange(len(start)):arr.append((end[i],start[i]))arr.sort()finish=-1foriinrange(len(start)):ifstart[i]>finish:finish=end[i]ans+=1returnansif__name__=="__main__":# all sorted by the finished time.
start=[1,3,0,5,8,5]end=[2,4,6,7,9,9]print(activitySelection(start,end))
Reviewing what I studied, how this work will be explained as well.
Introduction
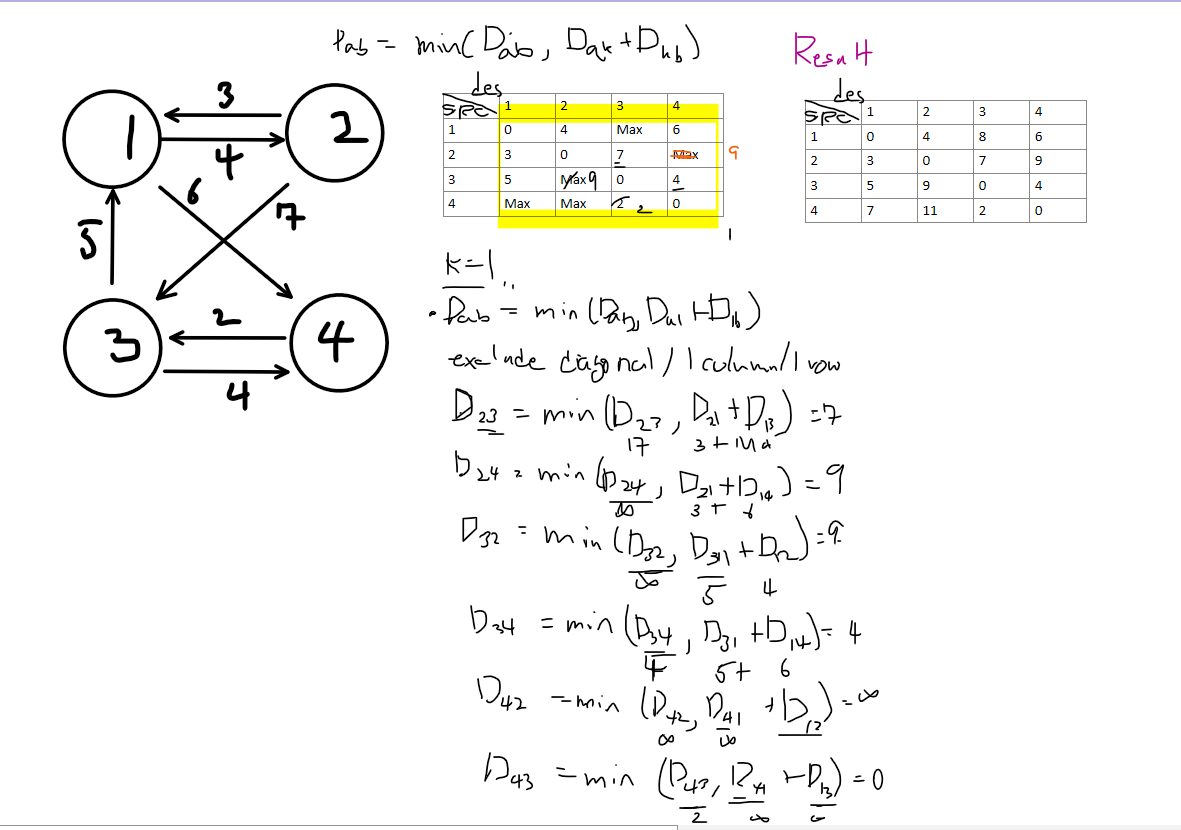
As we saw with Dijkstra’s and Bellman-Ford algorithms, we need to check if DP can be applied by identifying optimal substructure and overlapping subproblems. In the context of shortest paths, a portion of a shortest path is itself a shortest path, and overlapping subproblems occur when we reuse partial shortest paths. The approach involves finding three nodes u, v, and k where the path from u to v becomes shorter by going through k.
The key difference between Floyd-Warshall and the other two algorithms is that Floyd-Warshall isn’t fixed to a single starting vertex - it finds the shortest paths between all pairs of vertices. While the algorithm proceeds in stages based on intermediate nodes, it doesn’t require finding the unvisited node with the minimum distance at each step. Due to the graph’s characteristics, Floyd-Warshall can be implemented using an adjacency list, but it’s typically implemented with an adjacency matrix. This makes a bottom-up approach quite feasible.
Recurrence Relation:
Being able to solve a problem with Dynamic Programming means we can define a recurrence relation. At each step, we check if going through a specific node k provides a shorter path. We compare the direct path a->b with the path a->k->b:
Dab = min (Dab, Dak + Dkb) 이런식으로 세울수 있다.
Let’s look at an example using this recurrence relation. The right side shows the graph being updated when k = 1. By applying this process for each node k, we can see the final result in the upper right of the algorithm.
we can infer that the time complexity will be O(n³).
Implementation
코드를 확인해보자…
constexprdoublekInf=numeric_limits<double>::infinity();vector<vector<double>>graph={{0.0,3.0,8.0,kInf,-4.0},{kInf,0.0,kInf,1.0,7.0},{kInf,4.0,0.0,kInf,kInf},{2.0,kInf,-5.0,0.0,kInf},{kInf,kInf,kInf,6.0,0.0}};voidFloyedWarshall(constvector<vector<double>>&graph){vector<vector<dobule>>dist=graph;intV=graph.size();// The graph is already initialized above// If not, diagonal values should be 0 and other indices// should be filled with appropriate valuesfor(intk=0;k<V;k++){autodist_k=dist;for(inti=0;i<V;i++){for(intj=0;j<V;j++){if(dist[i][k]+dist[k][j]<dist[i][j]){dist_k[i][j]=dist[i][k]+dist[k][j];}}}}}
The implementation is surprisingly simple. We perform updates when necessary. Here’s a Python implementation which might be more straightforward, though it differs in indexing:
Cycle detection in a directed graph is a fundamental problem in graph theory with applications in deadlock detection, dependency resolution, and circuit analysis. The algorithm I’ve implemented uses a depth-first search (DFS) approach with a recursive traversal strategy to identify cycles in directed graphs.
Key Concepts
The algorithm relies on three key data structures:
A visited flag for each vertex to track which vertices have been explored
An on_stack array to track vertices currently in the DFS recursion stack
An edge_to array to maintain the DFS tree structure for cycle reconstruction
Time Complexity: O(V + E) where V is the number of vertices and E is the number of edges. Each vertex and edge is processed exactly once in the worst case
The cycle reconstruction takes at most O(V) time
Space Complexity: O(V)
on_stack, edge_to, and recursion stack each require O(V) space. The cycle array stores at most V vertices
Reviewing what I studied, how this work will be explained as well.
The Bellman Ford Algorithm is a graph search algorithm that finds the shortest path from a source vertex to all other vertices in a weighted graph. It is similar to Dijkstra’s Algorithm but can handle graphs with negative weight edges. However, it can detect negative cycles, which are cycles whose total weight is negative.
Key Differences from Dijkstra’s Algorithm
Negative Weight Edges: Bellman Ford can handle negative weight edges, whereas Dijkstra’s Algorithm assumes all edges have non-negative weights.
Negative Cycles: Bellman Ford can detect negative cycles, which is not possible with Dijkstra’s Algorithm.
Algorithm Overview
Initialization: Initialize the distance to the source vertex as 0 and all other vertices as infinity.
Relaxation: Relax the edges repeatedly. For each edge, if the distance to the destination vertex can be reduced by going through the current vertex, update the distance.
Negative Cycle Detection: After relaxing all edges V-1 times, check for negative cycles by attempting one more relaxation. If any distance can still be reduced, a negative cycle exists.
Time Complexity
The time complexity of the Bellman Ford Algorithm is O(V*E), where V is the number of vertices and E is the number of edges. This is because in the worst case, we relax all edges V-1 times.
Implementation
Here’s a corrected and complete implementation of the Bellman Ford Algorithm:
Then how do you think about getting the negative edges!? It’s basically same logic! if the distance the next edge is greater than the current(whole) distance, then we can conclude that there will be negative edge. Normally, the dist arrays two indices where negative values are very likely that it’s negative cycle.
Reviewing what I studied, how this work will be explained as well.
Rod Cutting Problem is a problem that we have a rod of length n and we want to cut the rod into n pieces, and we want to maximize the profit. For example, let’s look at the table below. If I have a rod of length 4, then we have 4 ways to cut the rod. Then we calculate the profit for each case
Cut the rod into 1, 1, 1, 1 => max profit = 1 + 1 + 1 + 1 = 4
Cut the rod into 2, 2 => max profit = 5 + 5 = 10
Cut the rod into 3, 1 or 1, 3 => max profit = 8 + 1 = 9
Then, let’s do bottom-up, Bottom-up Apprach is called tabulation, so we need kinda like table. I would say bottom up approch can be more familier if you are good at for-loop! (jk)
But when we think about the time complexity. it would be depending on the O (length). Of course, we do have space complexity which is about O(length + 1).
Reviewing what I studied, how this work will be explained as well.
Index Min Priority Queue
We’ve covered binary heap, priority queue and so forth, but one of the useful priority queue we’re going to look at is Index Min Priority Queue. This is a traditional priority queue variant which on top of the regular PQ operations supports quick updates and deletions of key-value pairs (for example, key can be double type, and value is int type).
Problems: Hospital Example
Suppose we have people who need to be taken care of, and it really depends on their conditions. For example, Mary is in labor, which has a higher priority than the others. Here is the issue: Richard went to a different hospital, and doesn’t really need to be taken care of anymore, and Nadia’s stomach pain + vomiting turned out to be an infectious disease, so she moved to high priority. This means our priority queue needs to be updated.
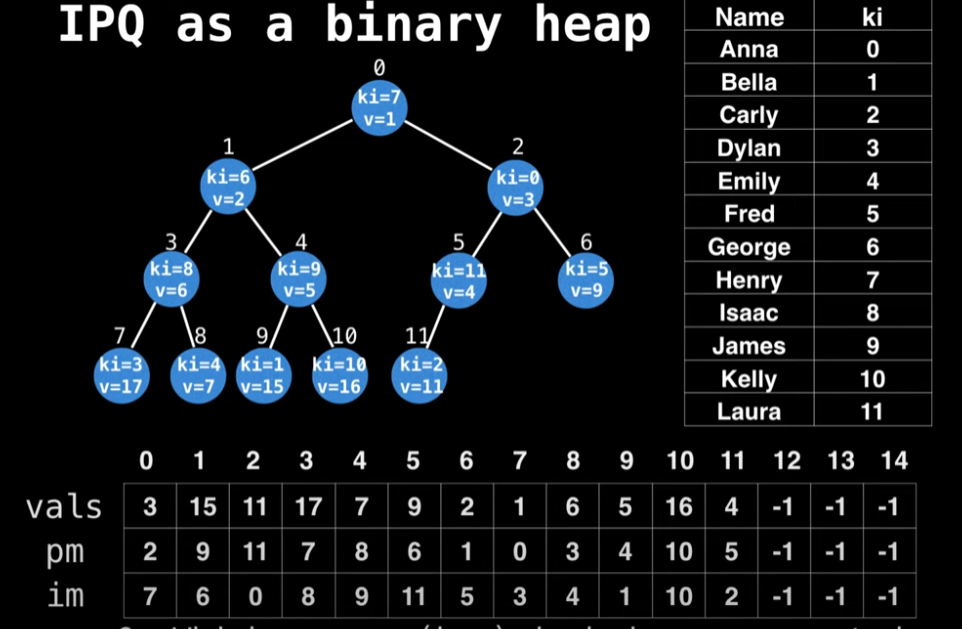
In the hospital example, we saw that it’s crucial to be able to dynamically update the priority (values) of certain people (keys). The Indexed Priority Queue (IPQ) data structure lets us do this efficiently. The first step in using an IPQ is to assign index values to all the keys, forming a bidirectional mapping.
Create a bidriectional mapping between your N keys and the domain [0, N) using a bidrectional hashtable.
Then why do I metion, it’s bidrectional mapping? Given the key value, we should be able to find the where this node is positioned in heap(position mapping). Also, Given the index value in value table, we should also be able to find the key value.
To show what is bidrectional, look at the image below:
Implementation
template<typenameKey>classIndexMinPQ{public:IndexMinPQ(intcap){capacity=cap;size=0;keys.resize(capacity+1);pq.resize(capacity+1);inverseMap.resize(capacity+1,-1)// InverseMap}boolEmpty(){returnsize==0;}boolContains(inti){returninverseMap[i]!=-1;}intSize(){returnsize;}voidInsert(inti,Keykey){size+=1;inverseMap[i]=size;pq[size]=i;keys[i]=key;Swim(size);}intMinIndex(){returnpq[1];}KeyMinKey(){returnkeys[pq[1]];}intDelMin(){intm=pq[1];Exch(1,size--);Sink(1);inverseMap[m]=-1;keys[m]=0.0;pq[size+1]=-1;returnm;}KeykeyOf(inti){returnkeys[i];}voidChangeKey(inti,Keykey){if(!Contains(i)){throw::std::invalid_argument("index does not exist");}if(key<keys[i]){keys[i]=key;Swim(qp[i]);}elseif(key>keys[i]){keys[i]=key;Sink(qp[i]);}}voidDecreaseKey(inti,Keykey){keys[i]=key;Swim(qp[i]);}voidIncreaseKey(inti,Keykey){keys[i]=key;Swim(inverseMap[i]);}voidDelete(inti){intindex=inverseMap[i];Exch(index,size--);Swim(index);Sink(index);keys[i]=0.0;inverseMap[i]=-1;}voidExch(inti,intj)// swap{intswap=pq[i];pq[i]=pq[j];pq[j]=swap;inverseMap[pq[i]]=i;inverseMap[pq[j]]=j;}boolGreater(inti,intj){returnkeys[pq[i]]>keys[pq[j]];}voidSwim(intk){while(k>1&&Greater(pq[k/2],pq[k])){Exch(k/2,k);k/=2;}}voidSink(intk){while(2*k<=size){intj=2*k;if(j<size&&Greater(j,j+1))j++;if(!Greater(k,j))break;Exch(k,j);k=j;}}private:intsize=0;intcapacity=0;vector<int>pq;vector<int>inverseMap;vector<Key>keys;}
The most important operation would be Swim and Sink.
The Swim operation works as follows:
Start with the element at index k that needs to be “swum up” the heap
Loop until either:
We reach the root of the heap (k > 1)
The parent is not greater than the current element (!Greater(pq[k/2], pq[k]))
In each iteration:
Compare the current element with its parent (located at index k/2)
If the parent is greater than the current element (in a min heap), exchange them (Exch(k/2, k))
Update k to the parent’s position (k /= 2) to continue moving up the heap
Sink Operation needs to go down the heap, which means we need to check both children. Here’s the complete process:
Loop until we reach the bottom of the tree (while 2*k <= size)
Calculate the index of the left child (j = 2*k)
Compare left and right children (if j < size && Greater(j, j+1))
If the right child exists (j < size) and is smaller than the left child (Greater(j, j+1)), select the right child by incrementing j
This ensures we select the smaller of the two children in a min heap
Check if the current node is already smaller than the selected child (!Greater(k, j))
If so, the heap property is satisfied, so break out of the loop
If not, exchange the current node with the selected child (Exch(k, j))
Update k to the position of the child (k = j) and continue the process
Reviewing what I studied, how this work will be explained as well.
Dynamic Programming is a method for solving a complex problem by breaking it down into simpler sub-problems. It’s one of a method for solving optimization problems. There are two components of Dynamic Programming:
Optimal Substructure
Overlapping Subproblems
Optimal Substructure
Optimal Substructure means that the optimal solution to a problem can be constructed from optimal solutions to its sub-problems. Basically, if you break it down to smaller array from big array, and you have an optimal solution to smaller array, you can use it to solve the big array. But when you think about this Optimal Substructure, it’s similar to Divide and Conquer. However there are differences. For example, in Divide and Conquer, we divide the big array into smaller array (divide), calculate, combine, and merge. But we try to find the set of sub-problems that have optimal solutions, and use it to solve the big problem. Also, we can compared this with Greedy Algorithm. Within all the solution that we get from optimal substructure (which is the set of sub-problems), we choose the best solution is the greedy algorithm.
This is normally done by using recursion.
Overlapping Subproblems
When we solve the problem using recursion, we solve the same sub-problem multiple times. This is called Overlapping Subproblems. For example, in the Fibonacci sequence, we can conclude in the following way:
[ 1 ] n = 1
fib = [ 1 ] n = 2
[ fib(n-1) + fib(n-1) ], n = 3, 4, 5, ...
Then, we can simply draw the tree of the sub-problems (draw yourself!). Then we can see that, fib(4) = fib(3) + fib(2) is calculated twice. This is called Overlapping Subproblems. Then, we can use the same sub-problem as cache to solve the problem.
Two types of Dynamic Programming
Top-Down (Memoization)
Bottom-Up (Tabulation)
Top-Down (Memoization)
Solve the sub-problem using recursing
Memoize the overlapping sub-problems
Reuse the memoized sub-problems to solve the big problem
Bottom-Up (Tabulation)
Solve the sub-problem using iteration
Using the tabulation, we can store the result of the sub-problem in a table
When to use Dynamic Programming?
State Transition
Simple Condition -> Fibonacci, Tiling, Digit DP(if digit condition is met, count the number of cases)
Array -> Kadane’s algorithm (sub-array sum), Kapsack Problem, Matrix(DAG, #of Path, Path Cost), String(LIS, LCS, Edit Distance), Max Profit (Buy and Sell Stock), Rod Cutting, Matrix Chain Multiplication
Tree -> DAG, DAG Shortest Path, DAG Longest Path, DAG Topological Sort, # of BST.
Optimization Problem -> Convex Hull, Matrix Multiplication Order