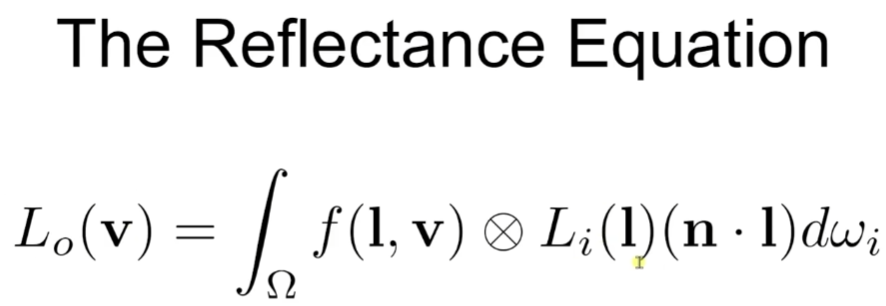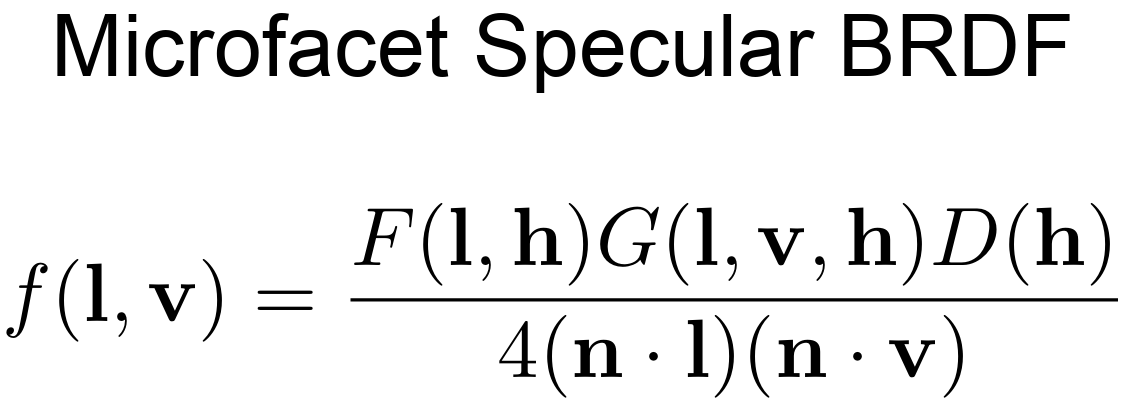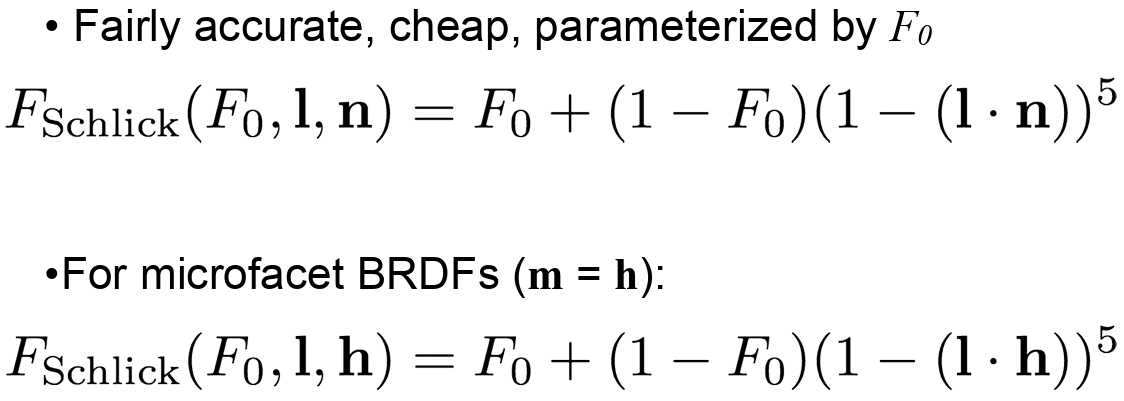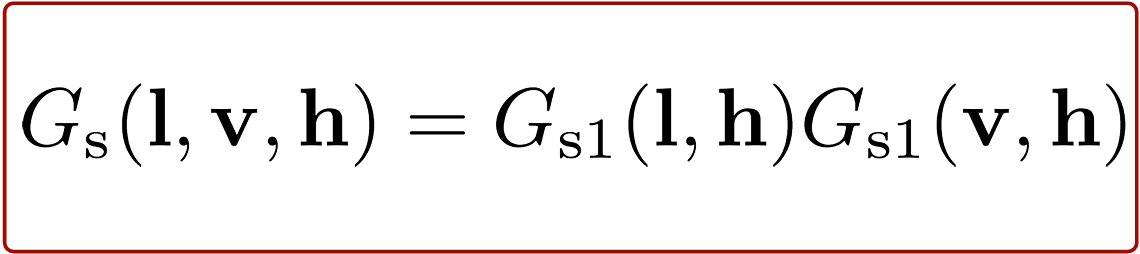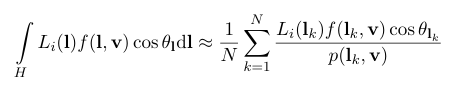In the previous post, we looked at the history of Gaussian Splatting. Now, let’s look at some experiments with 3D Gaussian Splatting and validation of the results. Also, I want to learn this as kinda of like top-down approach. So, I will start with running the 3DGS pipeline on a custom dataset and then analyze the results. The goal is to understand how the pipeline works end-to-end and to validate that it produces reasonable results on a real-world scene.
Objective
It was to run the 3DGS implementation en-to-end on a custom dataset. (self-capmtured indoor scene) for the first time and validate the results.
Experience the full pipeline: COLMAP SfM → 3DGS training → point cloud output → viewer visualization
Verify that training converges and produces visually reasonable results on a custom scene
The meta for first time running the 3DGS pipeline on playroom dataset. (225 Images). My GPU was NVIDIA GeFORCE RTX 2070 Super (8GB VRAM) and the training took about 2 days to complete. The viewer were used to visualize the output point cloud.
The config was as follows:
Namespace(data_device='cuda',
eval=False, # ← BUG: no train/test split → metrics are NaNimages='images',
resolution=-1, # original resolutionsh_degree=3, # Spherical Harmonics degreesource_path='C:\\Users\\skcjf\\project\\gaussian-splatting\\data\\my_scene\\playroom',
model_path='./output/858ba1ea-e',
train_test_exp=False,
white_background=False
)
Results
Training time: ~2 days (RTX 2070 Super)
Iterations: 30,000 (checkpoints at 7,000 and 30,000)
Then I did not get the results that I expected because I did not add –eval flag to the config, so I got NaN for all the metrics. But the point cloud output looked reasonable and the viewer visualization showed a decent reconstruction of the scene. The PSNR, SSIM, and LPIPS metrics were not computed due to the missing evaluation flag, so I will need to rerun with –eval to get those quantitative results.
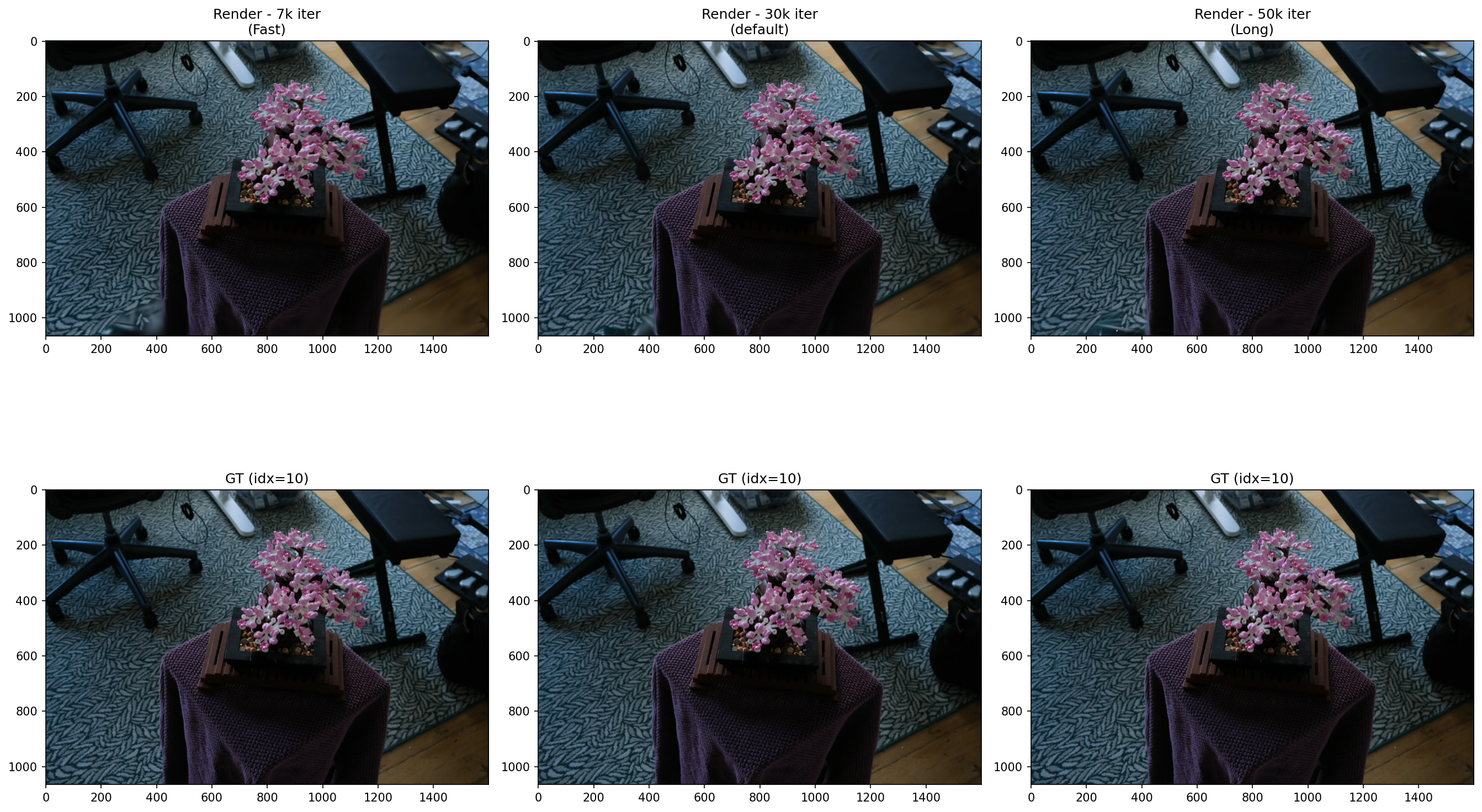
Iteration Comparison in Point Cloud Output:
Iteration
7K
30K
Front-facing view (looking into the room): 7k and 30k are nearly identical
Looking up at the ceiling: visible holes/gaps → likely insufficient training views from upward angles, or densification did not cover that region adequately
Problem Encountered:
Output folder names are random hashes (e.g. 858ba1ea-e), so locating the actual results was initially confusing
No build errors; used a separate Python virtual environment
Training took ~2 days on RTX 2070 Super, which saturated the GPU entirely (couldn’t even run YouTube simultaneously)
4 total attempts, 3 failed/aborted before the successful run
Second Run with Evaluation
Objective
Run 3DGS on a standard benchmark dataset with --eval enabled to obtain real quantitative metrics (PSNR/SSIM/LPIPS) for the first time. This fixes the [[3DGS First Run]] problem where eval=False produced NaN metrics.
Validate that the 3DGS pipeline produces results consistent with the original paper
Establish a quantitative baseline for future experiments (hyperparameter tuning, ablation)
Learn the full evaluation pipeline: train → render → metrics
I choose to use Google Colab for this run to leverage a more powerful GPU (A100 40GB with High RAN) and faster training times. Then, I ran multiple data (tandt_db / Mip-NeRF 360 dataset) as well to validate the results from paper.
The config was as follows:
Namespace(sh_degree=3,
source_path='/content/gaussian-splatting/data/tandt/train',
model_path='/content/drive/MyDrive/3dgs_output/train', # NOTE: mislabeled — actual scene is "train"images='images',
resolution=-1, # original resolutionwhite_background=False,
train_test_exp=False,
data_device='cuda',
eval=True # FIXED from First Run — train/test split enabled)
Results
Metric
Value
PSNR
22.12
SSIM
0.822
LPIPS
0.196
Gaussians
1,095,714
Iterations
30,000 (checkpoints at 7,000 / 30,000)
GPU
A100 40GB (Google Colab)
These were the metrics using for the dataset: tandt_db(train). The PSNR and SSIM values are consistent with the original 3DGS paper, which reported PSNR around 22-23 and SSIM around 0.8 for similar scenes. The LPIPS value of 0.196 also indicates a reasonably good perceptual quality compared to the ground truth images. The number of Gaussians (1,095,714) is also in line with expectations for a scene of this complexity.
Problems Encountered
Mip-NeRF 360 dataset URL (storage.googleapis.com) returned 404 — dead link
Initial !unzip extracted to wrong path → Could not recognize scene type! error. Fixed by ensuring sparse/0/ was in the correct location.
What I Learned
--eval is mandatory for quantitative evaluation — without it, no train/test split occurs
3DGS with default config on standard benchmarks reproduces paper results — the pipeline works
A100 vs RTX 2070 Super is a massive speed difference — Colab is the practical choice for experimentation
Dataset URL availability is not guaranteed — always have backup sources
Third Run with Mip-NeRF 360 Dataset
Objective
Experimentally verify the impact of 3 key 3DGS hyperparameters on the Mip-NeRF 360 dataset:
sh_degree: Spherical Harmonics degree (controls angular detail) for Kitchen Scene
The goal is to understand how these hyperparameters affect the final rendered quality (PSNR/SSIM/LPIPS) and visual appearance of the output point cloud. I will run multiple experiments varying one hyperparameter at a time while keeping others fixed, and then analyze the results.
Platform:
Google Colab with A100 High RAM for all experiments to ensure consistent training times and results.
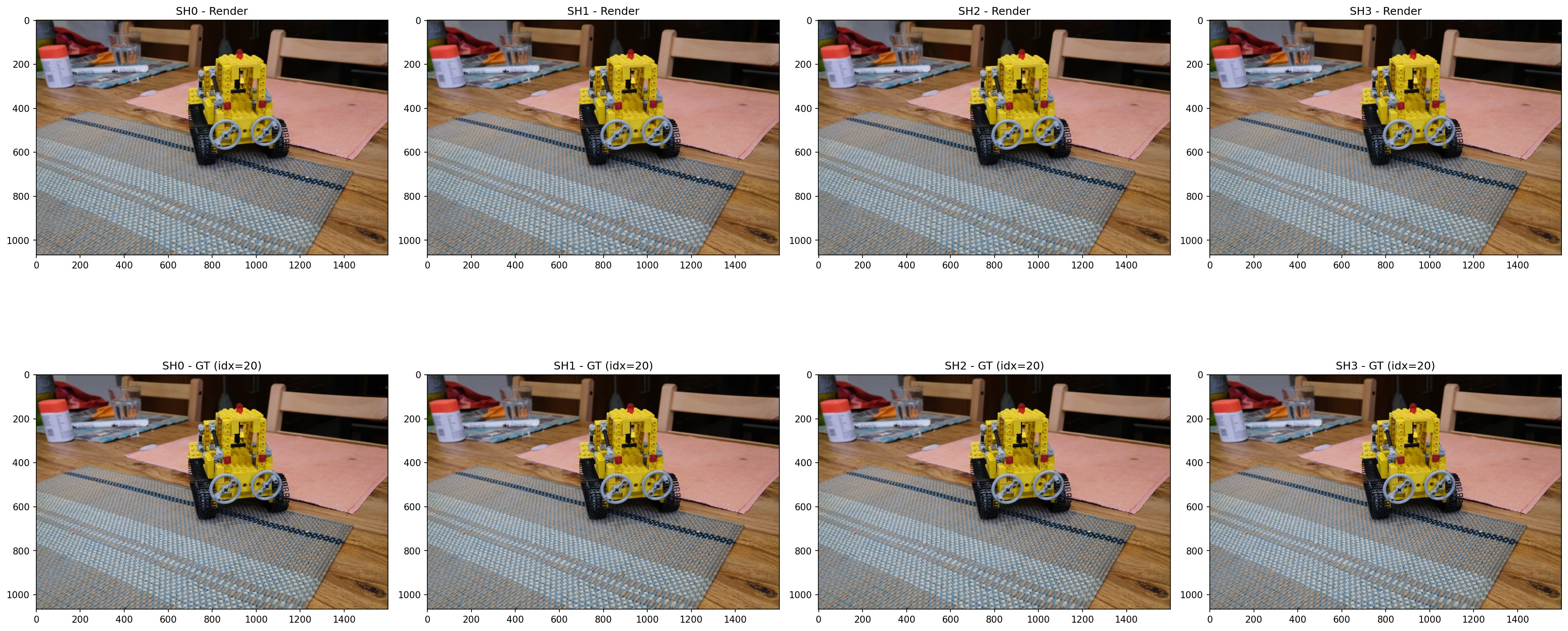
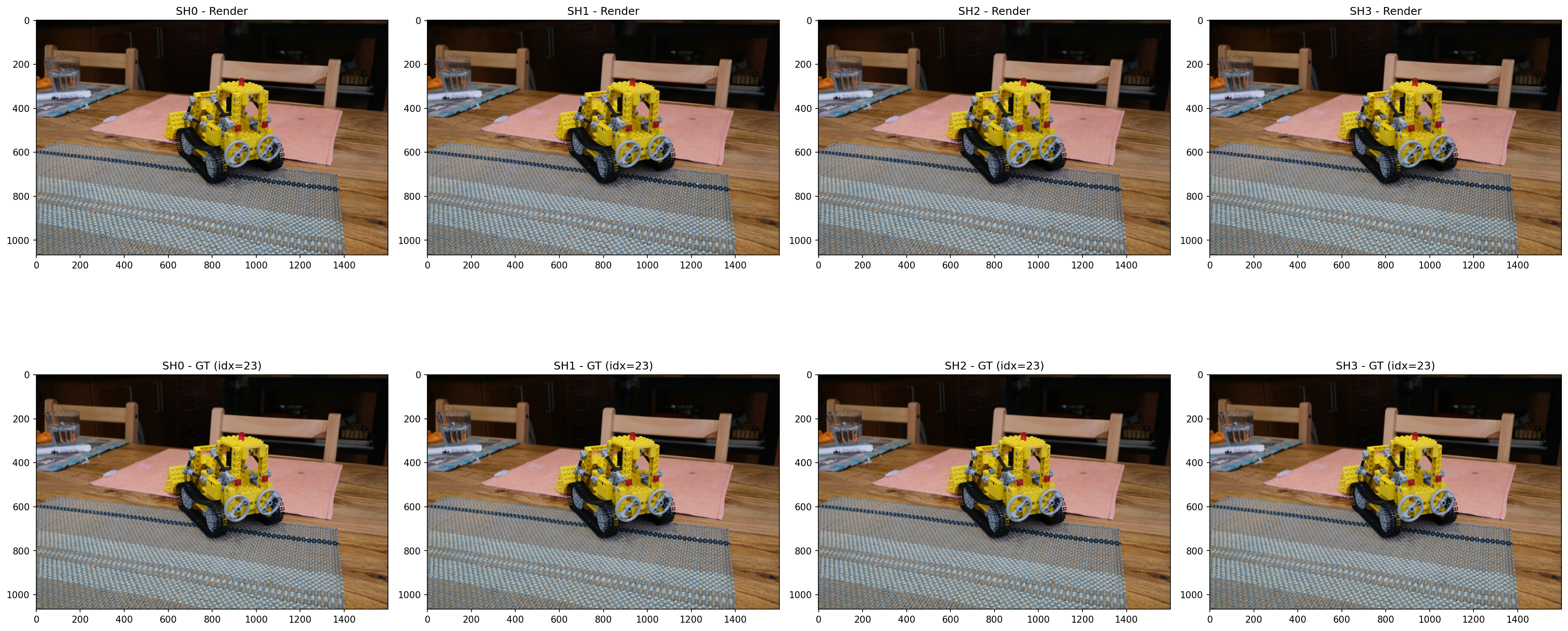
Note: sh0, sh1, sh3 trained at 7k iterations, sh2 at 30k → metrics for sh2 may be overestimated. Re-run with unified iteration count for fair comparison.
Image Index
Description
Image
18
SH degree 0 ~ 3 with ground truth Comparison
20
SH degree 0 ~ 3 with ground truth Comparison
23
SH degree 0 ~ 3 with ground truth Comparison
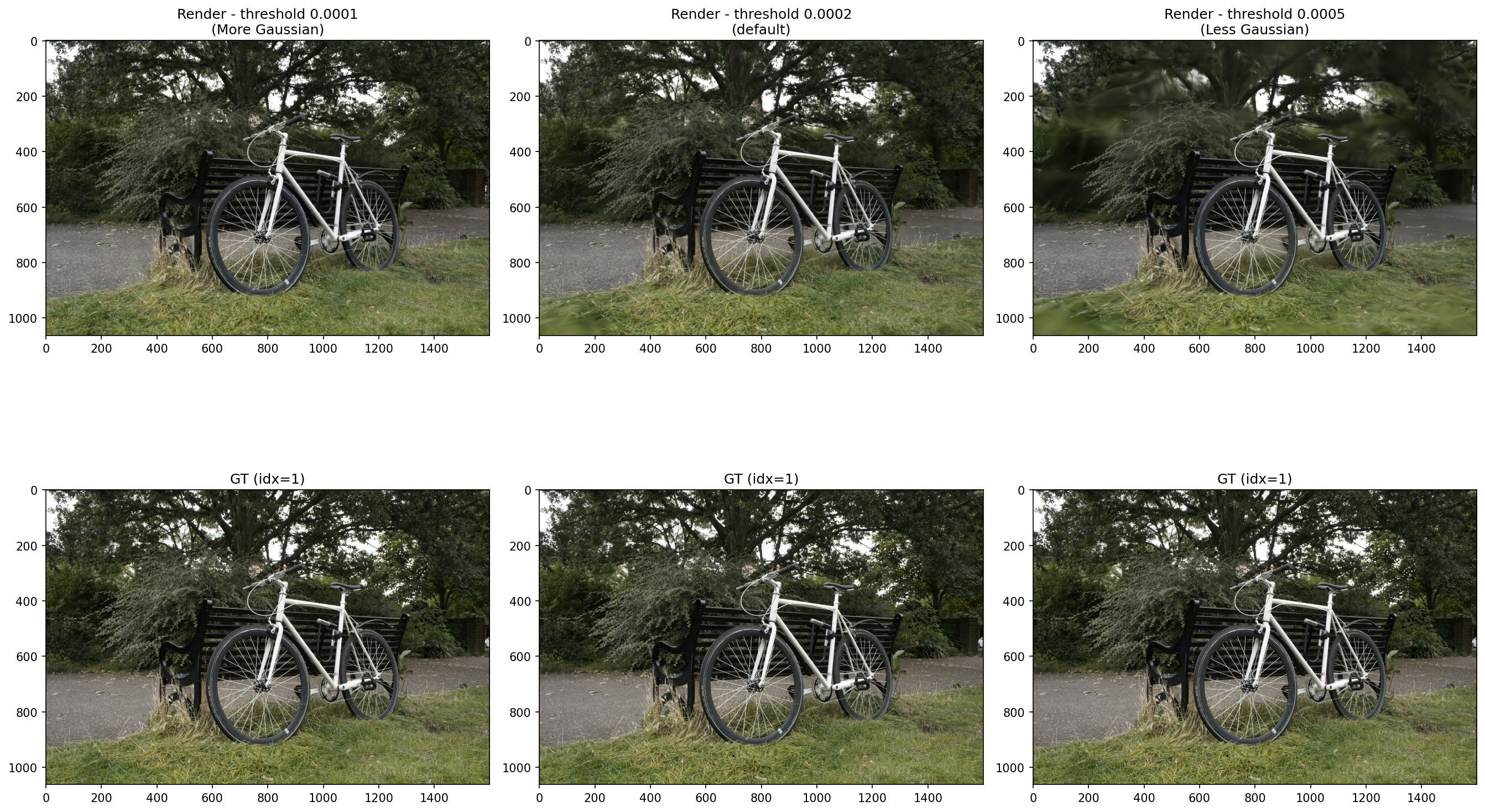
Hyperparameter 2: Densify Grad Threshold (densification)
Controls when Gaussians are split/cloned during training based on the gradient magnitude
Lower threshold → more aggressive densification → more Gaussians generated → better representation of thin structures (e.g. bicycle spokes, tree branches)
Higher threshold → fewer Gaussians → faster training but worse representation of fine details
Bicycle scene contains many thin structures (spokes, leaves, handlebars) that may benefit from aggressive densification and require 1–2 pixel level detail reconstruction
Neural Radiance Field (NeRF) is one of the interesting topics, which is kinds of extension of SIREN (Sinusoidal Representation Networks). NeRF is a method for representing 3D scenes using neural networks, specifically designed for novel view synthesis. Before this paper, there were Soft3D, Multiplane Image Methods (Multi-Layer, if views are different=>Orthogonal, it can’t be rendered), Neural Volumes (Memory Consumption issue <=> Resolution Issues), and many more. Most of them uses explicit 3D representation, such as voxel grids or points cloud. As you may know voxel representation can (1) leads to discretization artifacts or degrades view-consistency and (2) large memory consumption. But NeRF uses Implicit feature representation (Ligher than voxel representation), and continuous volumetric scene function. In detail or result, neural Radiance Field (NeRF) encodes a continuous volume within the deep neural networks, whose input is a single 5D Coordinate (spatial location (x, y, z) and viewing direction (θ, φ)) and output is the volume density and view-dependent emitted radiance(RGB Color) at that spatial location.
The image shown below is the overview of Explicit Representation vs Implicit Representation. As you can see, Explicit Representation uses Voxel Grid, Mesh, and Point Cloud, but Implicit Representation uses Signed Distance Function & Fields (SDF).
Background: Neural Fields(Coordinate-Based Neural Networks), Periodicity, Learning to Map
In order to understand NeRF, we need to understand the “Periodicity” and “Neural Fields” that underpin modern neural rendering techniques.
Neural Fields represent signals as continuous functions parameterized by neural networks. Rather than storing data in discrete grids or voxels, neural fields map input coordinates directly to output values - whether that’s color, density, signed distance, or any other signal. This idea shift allows us to represent complex 3D scenes implicitly through learned function approximations. For example, given an image, we train model with function that maps f_theta(x, y) -> RGB at position (100.4, 200.7) in the image, and compute this in neural network by inputing (x, y) coordinates. This makes us to query the scene at specific coordinates supporting different resolution.
There were major difficulties before neural field, which was spectral bias problem. Neural networks inherently suffer from spectral bias—they preferentially learn low-frequency functions and struggle with high-frequency details. A standard multilayer perceptron (MLP) with ReLU or similar activations tends to produce overly smooth outputs, missing fine-grained textures and sharp edges critical for photorealistic rendering. The image below shows ReLU and similar activations produce piecewise-linear outputs with zero second derivatives, making it hard to model fine detail or higher-order signal derivatives. This tells us the limitation becomes problematic when representing 3D scenes, which contain high-frequency details like edges, textures, and fine geometric features.
So, there are workaroudns can be used are in practice, for example, adding fixed Fourier features or sinusoidal positional encodings on the inputs. SIREN takes a more direct approach: it uses periodic (sine) activations throughout the network to build high-frequency capacity natively.
Let’s talk about SIREN(Sinusoidal Representation Network) little bit. This simply replaces standard nonlinearities with sine function. Concretely, computing this in each layer: \[x_{\ell+1} = \sin(\mathbf{W}_\ell \mathbf{x}_\ell + \mathbf{b}_\ell)\]
Why periodicity helps (SIREN)?
so, every neuron is a periodic oscillator. Why do that? there are two advantages using this. (1) Rich Frequency Bias, each weight vector $\mathbf{w}$ acts as an angular frequency for that neuron and each bias as phase offset. a SIREN is deep superposition of sinusoids. Adjusting this $\mathbf{w}$, the network can generate signal at arbitrarily high frequencies. Larger magnitude weights induce higher-frequency components, while smaller weights yield lower frequencies. SIRENs embedded a broad Fourier basis internally, making them naturally suited to fit complex, oscillatory signals. This is in contrast to ReLU/tanh networks, whose nonlinearities inherently bias toward smooth, low-frequency functions. (2) Smooth Derivatives The sine function is smooth and infinitely differentiable. Its derivative is a cosine (a phase-shifted sine), and further derivatives remain sinusoidal. In fact, as the authors note, “any derivative of a SIREN is itself a SIREN,” because $\frac{d}{dx}\sin(x)=\cos(x)$. This means a SIREN can represent not just a signal but also its gradient and Laplacian accurately. For physics-based tasks (e.g. solving PDEs or learning fields from gradient samples), this is crucial: SIRENs can easily encode higher-order derivatives, whereas ReLU networks have piecewise-constant first derivatives and zero second derivatives. Why am I focusing on this SIREN because this is preliminary information for positional encoding in NeRF.
SIREN Initialization and Training Behavior
Just to give you the heads up, the author mentioned that the SIREN needs to be initialized carefully, By drawing weights from a scaled normal distribution (standard deviation $\sqrt{2/n}$) and choosing the first-layer frequency scale $w_0$ so that $\sin(w_0 x)$ spans many periods over the input range, the authors ensure each layer’s pre-activations stay near unit variance. Concretely, they find setting $w_0\approx30$ (so that $\sin(w_0 x)$ oscillates quickly over $x\in[-1,1]$) yields fast, robust convergence. This principled init prevents the network output from collapsing or exploding with depth, preserving gradient flow. With this setup, SIRENs train stably via standard optimizers like Adam.
With this setup, SIRENs exhibit stable gradient behavior. The sine derivative $\cos(x)$ is bounded and nonzero almost everywhere, avoiding the dead zones of ReLU or saturation of $\tanh$. Empirically, Sitzmann et al. show that SIRENs converge much faster than baseline ReLU/tanh networks. For example, fitting a single 2D image takes only a few hundred iterations (seconds on a GPU) with SIREN – orders of magnitude faster than naive MLPs – while reaching higher fidelity. This is because the network immediately has the capacity to represent needed frequencies, rather than slowly adapting to them during gradient descent. In fact, subsequent analysis (Chandravamsi et al.) confirms that without proper init, even SIRENs can exhibit a form of “spectral bottleneck” – underscoring the importance of the initialization scheme.
To summarize to one point is that volme rendering itself is differential function. The goal in NeRF is to calculate the loss between GT and MLP output image.
NeRF: Neural Radiance Field
NeRF Key Points
This paper proposes a method that synthesizes novel view of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views.
This algorithm represents a scene using a fully-connected deep network, whose input is a single 5D Coordinates and whose output is the volume density and view-dependent RGB Color at that spatial location.
Classical volume rendering techniques are used to accumulate those colors and densities into a 2D Images
NeRF Overview
Since we cover the major components above, let’s look into details of NeRF
Ray Marching is one of those techniques that seems simple on the surface - march along a ray, sample something, stop when you hit it. - but hides a surprising amount of depth in the detail. Afterr writing fragment shaders on Shadertoy, integrating SDFs(Signed Distance Fields) into deferred pipelines, and later reading NeRF source code, it became clear that ray marching is the conceptual backbone connecting classical real-time rendering to modern neural rendering.
This post covers two distinct favors of ray marching that a graphics engineer encounters:
Sphere Tracing: ray marching through a signed distance field (SDF) for implicit surface rendering. This is the classic “ray marching” technique popularized by Inigo Quilez and others, where the SDF provides a guaranteed lower bound on distance to the nearest surface, allowing for efficient traversal.
Volumetric Ray Marching: marching through a participating medium (fog, smoke, fire) wit htransmittance accumulation. This is the core of volumetric rendering and neural radiance fields (NeRF), where we integrate color and density along the ray to produce a final pixel color.
Volume rendering is a technique used to visualize 3D volumetric data, such as medical scans (CT, MRI), scientific simulations, and fluid dynamics. Unlike traditional surface rendering, which only displays the surfaces of objects, volume rendering allows us to see the internal structures and variations within a volume.
Volume Rendering Techniques.
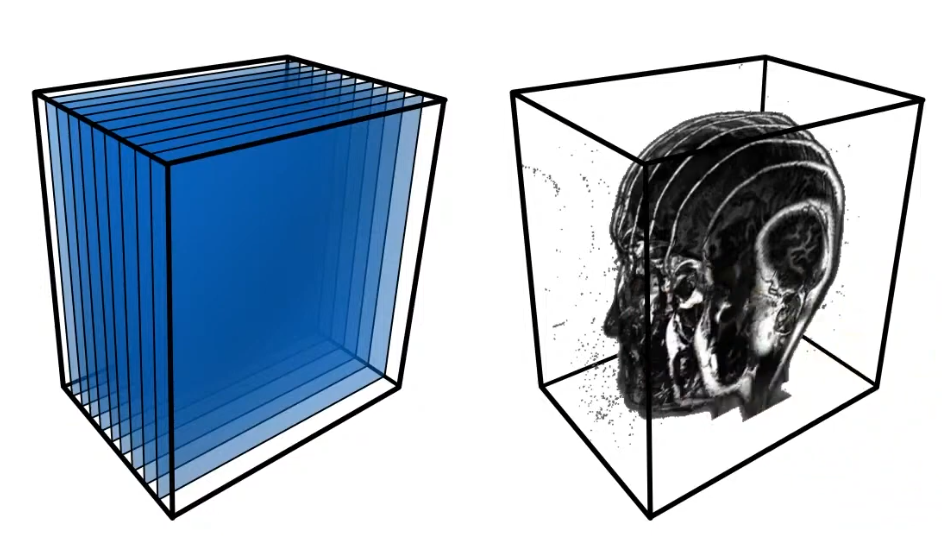
The simple way to do this is called “Volume Rendering with Slicing”. It is similar to alpha blending, where we take multiple 2D slices of the volume data and blend them together to create a 3D representation. Each slice is rendered with a certain opacity, allowing us to see through the volume and observe its internal features.
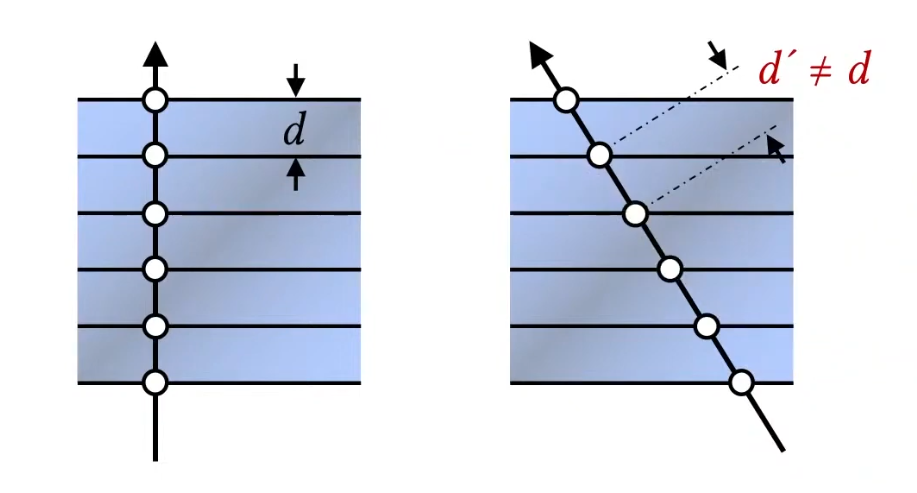
Then this data is typically stored in GPU as a 3D Texture, where each voxel (3D pixel) contains information such as color and opacity. During rendering(Back to Front), we sample the 3D texture along rays that pass through the volume, accumulating color and opacity values to produce the final image.. But the limitation is we can only see the 3D-like data when we look at it from certain angles, otherwise it looks like so many slices stacked together, and this statement will be shown below. (Rotating the camera, the distance between slices will be different, so it looks bad from certain angles = this means sampling distrubution for view direction changes.) But have you thought about why the distance matter? because if you have dense, which means that I have so many samples(slices) to render, then it will look good from any angles. But if you have sparse samples, then it will look bad from certain angles. So, this is the bottleneck of slicing-based volume rendering.
To resolve this issue, we can generate textures dynamically based on the view direction, which is called “View-Dependent Texture Generation”. This technique involves creating textures that change depending on the camera’s position and orientation. By doing so, we can ensure that the volume appears consistent and visually appealing from all angles, even with a limited number of samples. like the image shown below. (you can do this in geometry shader and make the different shape of slices based on the view direction, but it is still not good enough, or custom clipping plane based on the view direction)
or, you can render all this in blending returning zero alpha value.
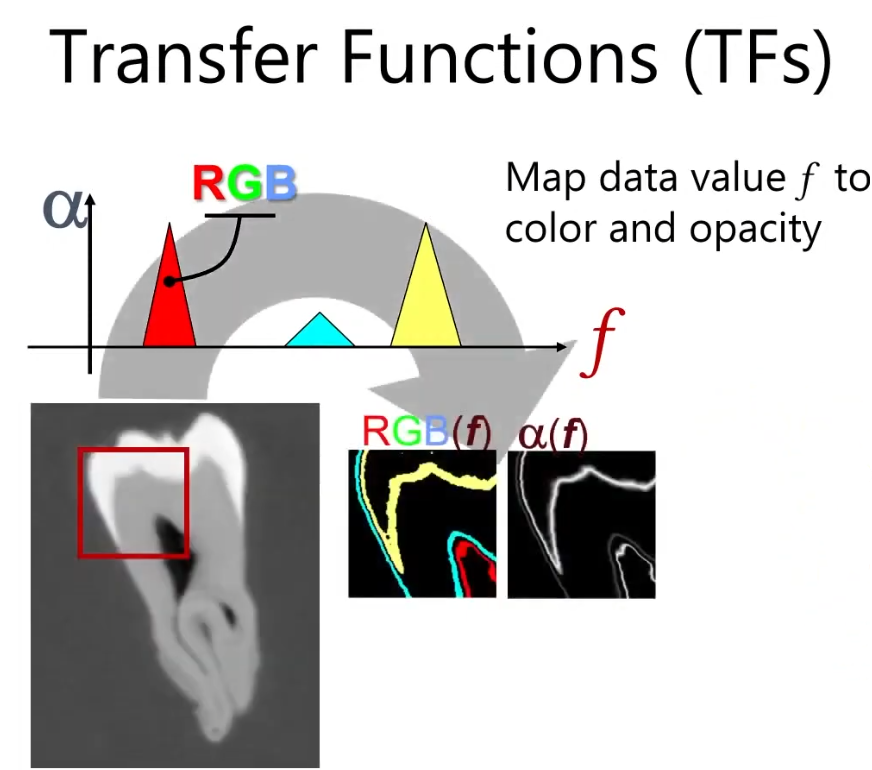
Transfer Function
Now, let’s talk about Transfer Function. This basically describes how we map the raw volumetric data (like density or intensity values) for visualization. The image below shows an example of a transfer function. So picking the transfer function, we can visualize what we want to see in the volume data. Then we can visualize whole image by accumulating these values. (Shading, Compositing…). How to define the transfer function is up to you.
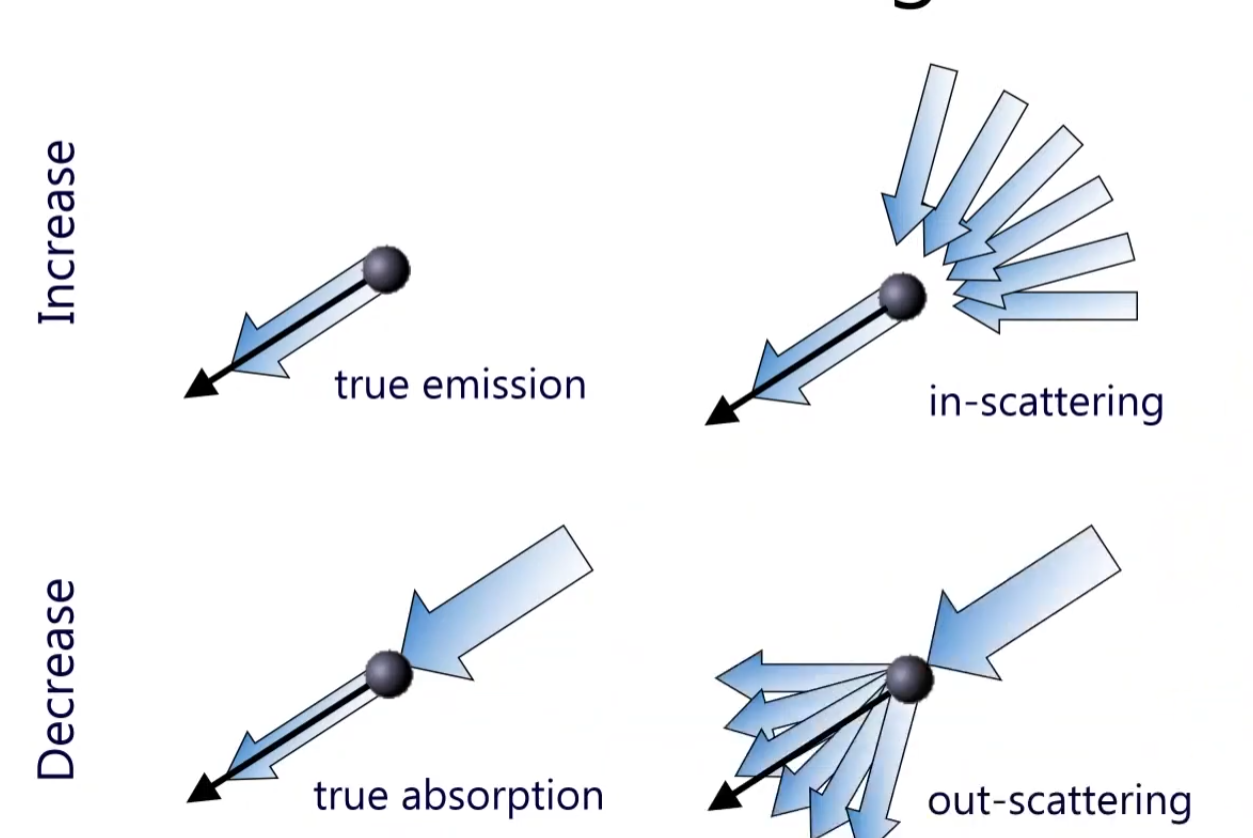
Volumetric Scattering
If the one particle is floating around, and light hits this particle, then this particle has true emission towards the view direction. (Basically I am looking at this emission) or if the particle doesn’t have the emission, but other scattering light towards to this one particle (in-scattering) in side of the volume. There are multiples of volumetric scattering, as shown below.
So, depending on the media type, we can have different volumetric scattering effects. For example, in a foggy environment, light scatters multiple times before reaching the viewer, creating a soft and diffused appearance. In contrast, in a clear medium like air, light travels more directly, resulting in sharper and more defined visuals. The visibility in a volume can be decaying function like I(s) = I0 * e^(-σt * s), where the absoprtion along the ray segment s0 - s, and the equation would be I(s) = I(s0) * e^(-t(s0, s0)). Then the t is defined as extinction, and t(s1, s2) = ∫ k(s) ds from s1 to s2 and k represents absorption coefficient.
If at one point, there is s_tilde that it’s emtting light towards the view direction, then this will be added to I(s) as shown above. So, to sum up equation would be I(s) = I(s0) * e^(-t(s0, s)) + ∫ e^(-t(s_tilde, s)) * k_a(s_tilde) ds_tilde from s0 to s. where k_a is absorption coefficient.
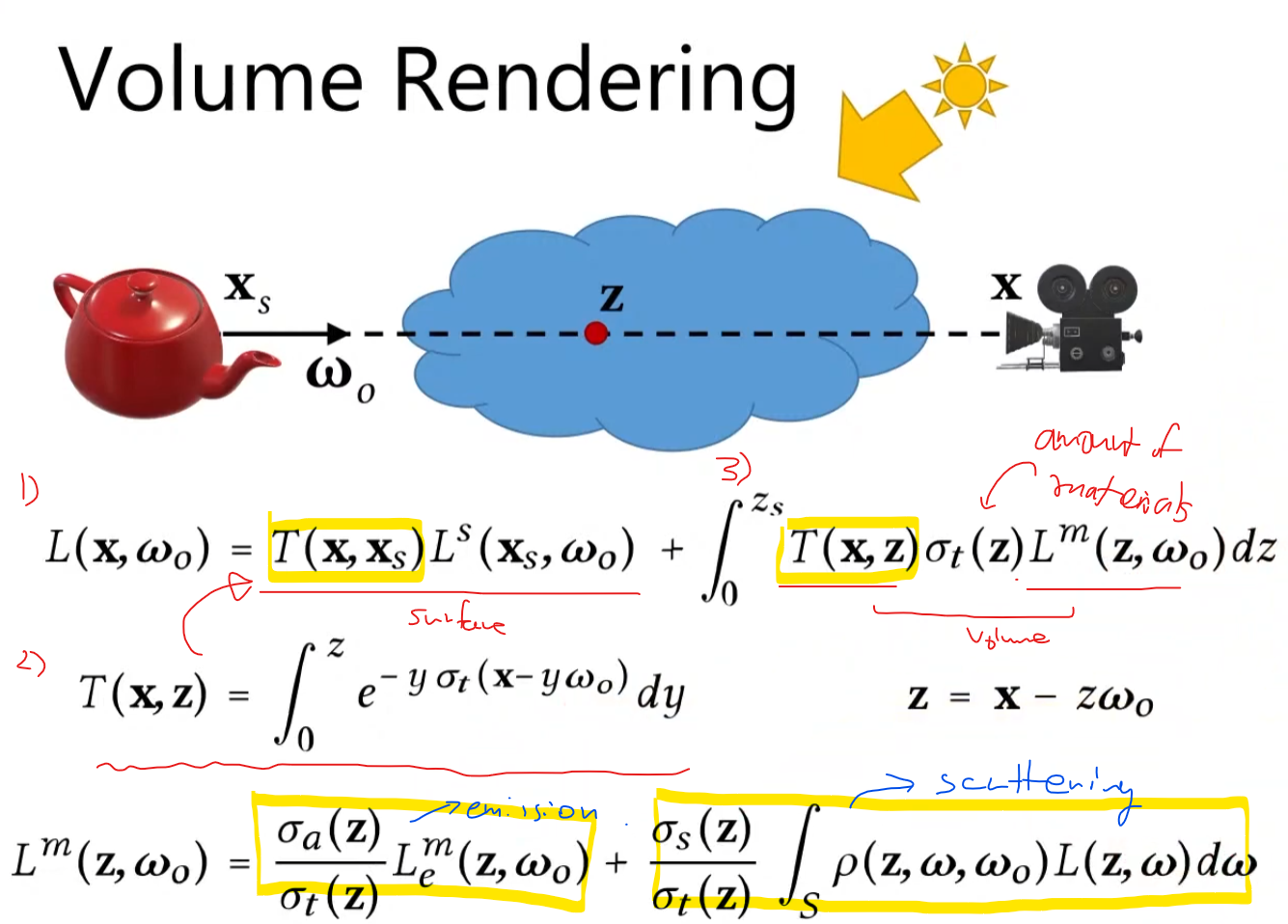
Let’s look at the image below!
The 1) shows the how much light blocks along the ray segment. We won’t be able to see the light source (L^s), but by this transmittance function T(x, x_surface) => Basically tells us how much light is getting through from point x_s to x. Then the 2) integral of how much(percentage) we can see along the z direction, then if we go up to surface level, that becomes the T(x, x_surface). Since it is possible that the inside of the volume can emit the lights, scatter, and absorb, we need to evaluate in this volume. T(x,z) will be absorbed, sigma_t(z) is the materials property.
Then this L_m basically tells us how much the part of material is emitting the light towards to the view direction, and the part of light is scattered towards to the view direction. So, the final rendering equation will be like this above.
Volume Tracing
As the ray traverses through the volume, we sample points along the ray at regular intervals. This is so called ray marching. This is expensive operation. Then, how do we handle it efficiently? There is a way called, Woodcook tracking / delta tracking. This method picks the random point along the ray, then generate another random position, and so on. What we can do is we create a fictitious medium with the highest desnsity in the volume. Then we can sample whether they are fictitious particle or real particle. If it is fictitious particle, then we just ignore it and keep going. If it is real particle, then we compute the scattering, absorption, and emission at that point. By doing this, we can avoid sampling in low-density regions where there are few interactions, thus speeding up the rendering process.
Volumetric Shadows
When rendering volumes, we also need to consider shadows. Just like in surface rendering, where objects can cast shadows on each other, volumes can also block light and create shadows within themselves. To compute volumetric shadows, we can use techniques like ray marching combined with shadow mapping or shadow volumes. This involves tracing rays from the light source through the volume to determine how much light reaches each point, taking into account any occlusions caused by denser regions of the volume. You can use Opacity Shadow Maps for this.
Practical Implemetation tips is Available on My Github.
It’s been quite a while after I left the previous job, which made me focus on what I really wanted to do with my career. When the AI technology governing the word, like CNN & Supervised Learning. At first, the AI itself seems to be intriguing; understanding from the data, and make an algorithm. However, I was skeptical if they can be deployed into real device, then I ponder I need to understand the optimization, but that’s when I saw myself being employed into Self-Driving Vehicle Simulator, which was Unity Based and switched to Unreal Engine Later.
I think I was fortunate. While developing the simulator as a testbed—although it was built on top of the Unreal Engine client—I had the chance to work on various subsystems and gain experience with the Observer Pattern, event-driven architecture, multithreading, and network programming (TCP/IP, ROS Bridge). Thanks to all of that, I feel like I finally started walking the path I wanted as a software engineer. And eventually, by developing sensor simulation modules needed for autonomous vehicles (LiDAR, Camera, RADAR, etc.), I had the chance to work on performance optimizations with real-time and sync modes as well. Of course, since these were simulations, they didn’t perfectly match reality 100%, but they still helped me transition from the vision side into graphics.
Hyundai Autoever
Back then, Hyundai Autoever was a solid company as an affiliate of the major corporation Hyundai Motor Company, and I thought my skills would fit in pretty well. Even though the position I applied for was a bit far from automobiles—specifically, the Smart Factory Digital Twin Platform development team within the SDx division—I felt that the interviews went reasonably well. There were a few awkward moments, but I enjoyed the take-home assignment and the coding interview. Compared to Amazon, they seemed a bit less strict in their selection process, but looking back, it still had a fairly long and structured pipeline.
I won’t go into details about the assignment, but I liked that it felt like working with a real application. I also felt that the work could later expand into Inverse Kinematics (IK). I’m not a roboticist, but I’ve always been confident in my understanding of 3D graphics and mathematics, so I approached it with a good amount of confidence.
Looking back now, there were definitely some unexpected questions during the second executive interview, but I answered with confidence and did my best to express why I was a good fit for the company. And now that the final result was acceptance, I can say that quitting my previous job and going through that period of struggle ended up becoming an opportunity to reflect on my career and grow from it.
I left out some details, but this is a brief summary of my interview experience with Hyundai Autoever.
The purpose was to make terrain in my Game Engine. In order to make terrain, you need to multiply the height scale based on Height Mapping for each model mesh in the vertex shader. However, one of my instincts was basically telling me “Would it be efficient to use height mapping if there are too many vertices, and transform those vertices according to displacement texture to show realism?” So, I’ve found that there is something called “Parallax Mapping”, “Parallax Steep Mapping”, and “Parallax Occlusion Mapping”. These methods originate from Per-Pixel Displacement Mapping. These methods give a sense of depth or illusion, and this approximation technique can be done in the fragment shader. Let’s take a look at Parallax Mapping first, then move on to Parallax Occlusion Mapping because steep mapping is an addition of steps - other than that, it’s similar to Parallax Mapping.
Idea
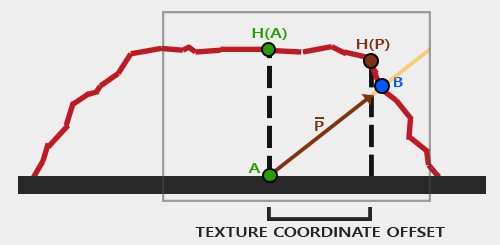
The idea is to think differently about the texture coordinate, considering that the fragment’s surface is higher or lower than it actually is. So the UV coordinate is literally above or below the actual vertices from the vertex shader. If you take a look at the image below, what we want to find is Point B, rather than A. But A is what we actually see (in fragment space). Then how would you calculate Point B? You can think of it as similar to ray casting. Since you have the view direction, you can figure out the P vector by using the height (displacement) map, then we can approximate the displacement to Point B. But it won’t always work - I will explain this in the limitations.
In terms of implementation, one important thing to note is to send the normal and tangent vectors. For each vertex, depending on where the surface is directing, you can set normal and tangent, and pass these through the render pass. In detail, you should calculate the Parallax mapping on tangent space, which means you need to transform the view direction to tangent space multiplying TBN matrix.
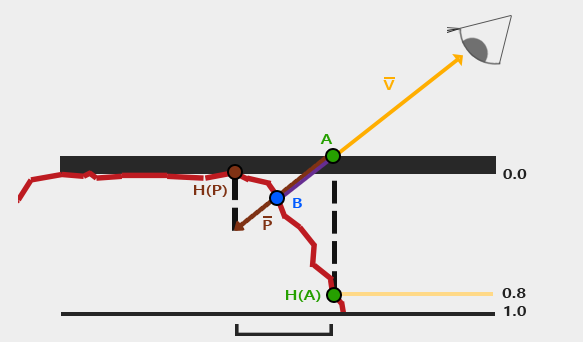
Okay! Let’s look at the calculation in detail. We think that we are looking at the surface (at height 0.0), and the camera is pointing at A, but we want to figure out Point B. We can calculate the vector P from Point A using the view direction. The key insight is that we use the height value H(A) sampled from the height map at point A to determine how far to offset our texture coordinates along the projected view ray. Then we sample through along the Vector P with the length H(A) to A. Then we can get the end of Point from Vector P and corresponding H(P) from height map. Like i said this is approximation. In order to make it more accurate, you can certainly use steep method where it takes multiple sample by dividing total depth range into multiple layers. The details are shown in this link.
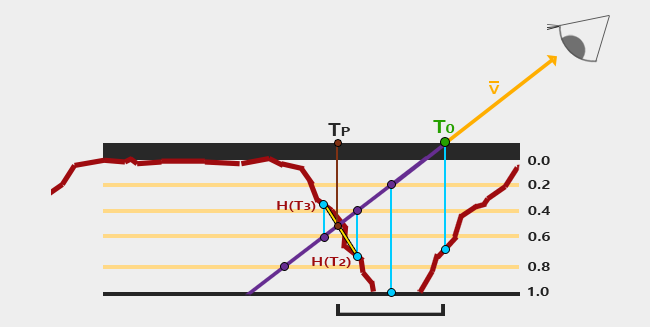
Finally, one more step is needed after steep parallax occlusion mapping. For each step we found T3 and T2, then we sample H(T3) and H(T2). Then we interpolatate those two points, treating like flat surface, if the depth is incorrect.
Results
Limitation
There are some limitation or usages I can mention by doing some experiments. The big issues is an aliasing exist when height map of that texture dramatically changes over a surface. You can test on this repo. I guess that’s why the usecase might be cave, stairs, bricks, some texture that have consistent height values. I can mentioned that each methods have a “bad effect”; it looks distorted in some angles in Parallax Mapping, and you can see the steep if the sample rate is very low in Steep Parallax Mapping. But if we know that why these downside appears to be true when you implementing, it all makes sense.
Conclusion
Interestingly, we found the way to show the depth rather creating a lot of triangles. Of course the goal was to implement the terrain (height + tesselation), but it was good to develop new things!
Okay, this is a very difficult topics I could say from the point of muggles. (when I say muggle, it’s not like dumb people, just people who don’t know the background of physical rendering which include me). But we can simply narrow down about what we know. In order to fully understand physical based rendering, we need to understand how light behaves in real world. Basically we need to go over the physics in Light.
Physics
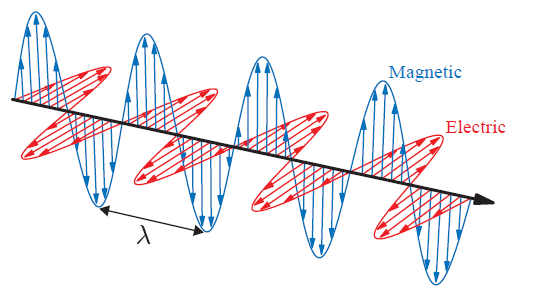
First of all, the one of the principle of physics is energy conservation. What !? where this idea coming from? When we think of the physics of light. Light waves carry the energy, basically saying that the density of the energy flow is equal to the product of the magnitudes of the electric and magnetic field.
Rendering, we care about the average energy flow over time, which is proportional to the squared wave amplitude, and this “average energy flow density” is also called irradiance. Summation / Subtraction of wave can be described as constructive and destructive interference, and also called coherent addition. Since those are not the most often case. If the waves are mutually incoherent, which means there wave’s phase can be random. We can simply say that they can interfere each other resulting almost “zero” amplitude or “some amplitude” in different location. This basically tells us that the energy gained via constructive interference and the energy lost via destructive interference always cancel out, and the energy is conserved.
Above information, in rendering scenario, using the average energy flow density is plausible, Then we can talk about the light interaction with molecule. Basically, when light hits the matter, then it separates the positive and negative charges, forms dipoles, then this matter itself radiates the energy back out as form of heat or form of new waves (scattered light) in new direction. So far, in reality, it is hard to simulate all these behavior.
While these molecular-level interaction are fascinating from a physics perspective, and implementing this simulation in rendering is computative expensive. When implementing rendering system, we don’t work with individual molecules - instead, we deal with surfaces composed of countlesss molecules interacting together. This collecttive behavior creates some interesting effects:
Group Behavior: Lights interactions with a cluster of molecule behave differently than with single molecules in isolation.
Wave Coherence: When light waves scatter from molecules that are close together:
They maintain a coherent relationship since they come from the same source wave.
This leads to interference patterns between the scattered wave between scattered waves.
These interference patterns significantly affect the final appearance material
To make these complex light interactions more manageable for real-time rendering, we can leverage fundamental principles from optics. Our foundation begins with the concept of homogeneous media - materials that maintain uniform optical properties throughout their volume.
The key characteristic of a homogeneous medium is its Index of Refraction (IoR), a property familiar from basic physics. There are two numbers associated with IOR, one part is to describe the speed of light through the medium, and the other part is to describe how much light are absorbed in medium. But simply put how it bends when crossing boundaries between different materials like we learn in science class.
Then, we assume that there are many molecules or isolated molecules inside of, what we called “Scattering Particle”. These bascially behave similarly as what we mentioned earlier. The right below image basically shows overall combination of absoprtion and scattering property. There are different types of scattering “Rayleigh Scattering” for atmospheric particles, and “Tryndall Scattering” in particle embedded in solids. Also, mie scattering when particle size goes beyond the wavelength.
In physically-based rendering, we need to design algorithms that simulate how light realistically interacts with surfaces—whether it’s glossy glass, brushed metal, or frosted plastic. When light hits a surface, two major factors influence the outcome:
The substances on either side of the surface
The surface geometry
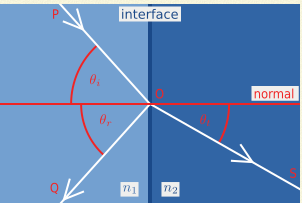
The first factor—the materials on either side of the boundary—is governed by the index of refraction (IoR). When a light ray encounters a boundary between two media (e.g., air and glass), it bends according to Snell’s Law:
sin(θt) = (n1 / n2) * sin(θi)
Here, n1 and n2 are the indices of refraction for the “outside” and “inside” media, respectively. Assuming the surface is perfectly flat, Snell’s Law predicts the direction of the refracted ray. This kind of behavior explains how materials like glass or water bend light in a physically accurate way.
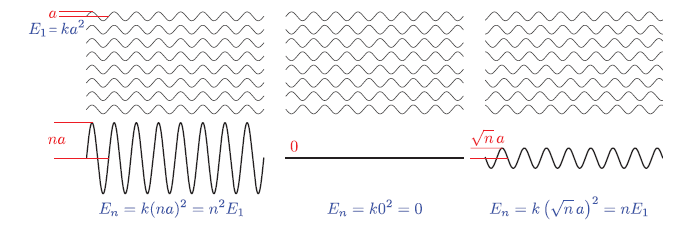
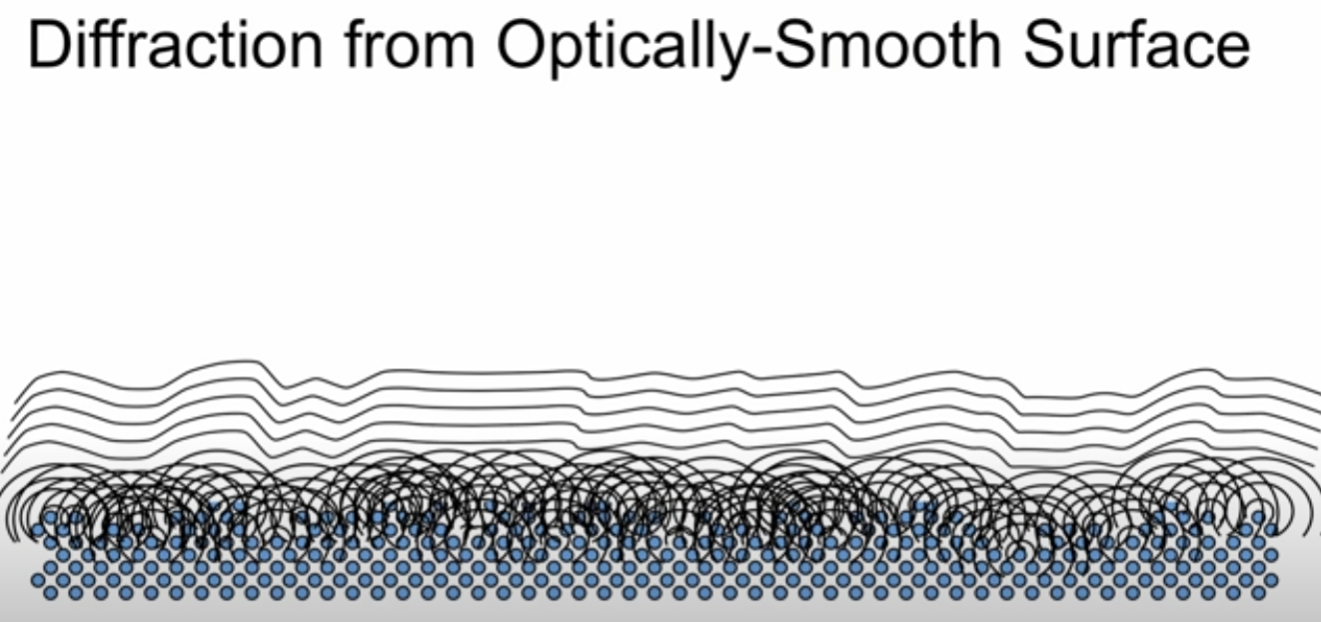
According to video, I’ve watched they talk about more geometry of the surface, so we’re going to talk about that! In terms of surface, we can mention nanogeometry in terms of atomic level (smaller than wavelength). What we see the image below is basically diffraction in atomic level creating waves by the Huygens Law.
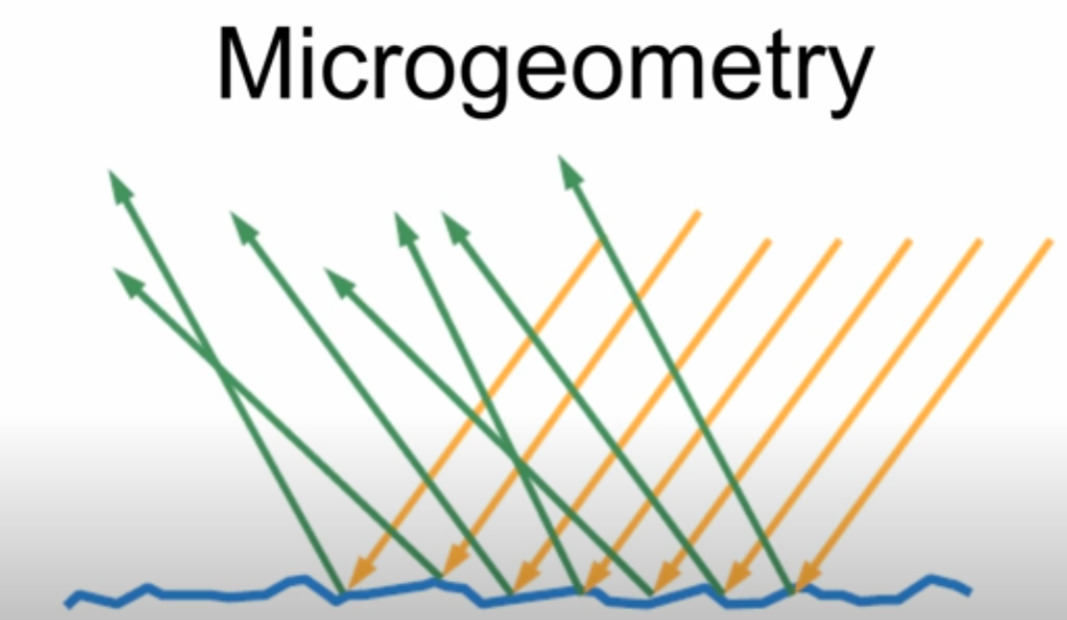
When light hits the surface, there are two parts, reflection & refraction. Depending on the surface normal, the direction for reflection can be varied as well as refraction. Such as shown below.
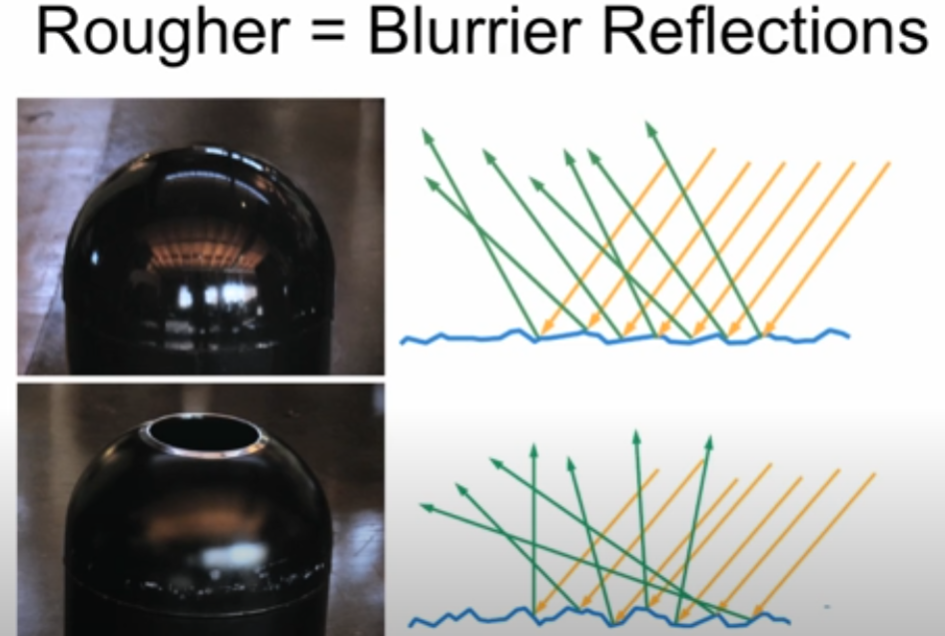
The great example would be the shown below. Even though we see and percieve the surface as “Similar” shape, but in microscopic level, these have different reflection and refraction. The one above seems to be very reflective, which means the roughness is relatively lower than below, and the other seeems to be relatively blurred.
The behavior of refracted light depends heavily on the type of material the medium is made of. Broadly, we can divide materials into two categories:
Metals (Conductors)
Dielectrics (Insulators)
Metals (Conductors) In metals, the refracted light doesn’t travel far into the material. Instead, it is quickly absorbed due to the presence of free electrons. These electrons interact with the incoming light, converting much of the refracted energy into heat or re-emitting it as reflected light. This is why metals are highly reflective and often appear shiny, but not transparent.
Dielectrics (Insulators) In contrast, dielectrics—like water, glass, or plastic—allow light to enter and travel through the medium. However, as light moves through a dielectric, part of its energy is absorbed or scattered inside the material. For example, if you shine a light above a cup of water, you’ll notice that:
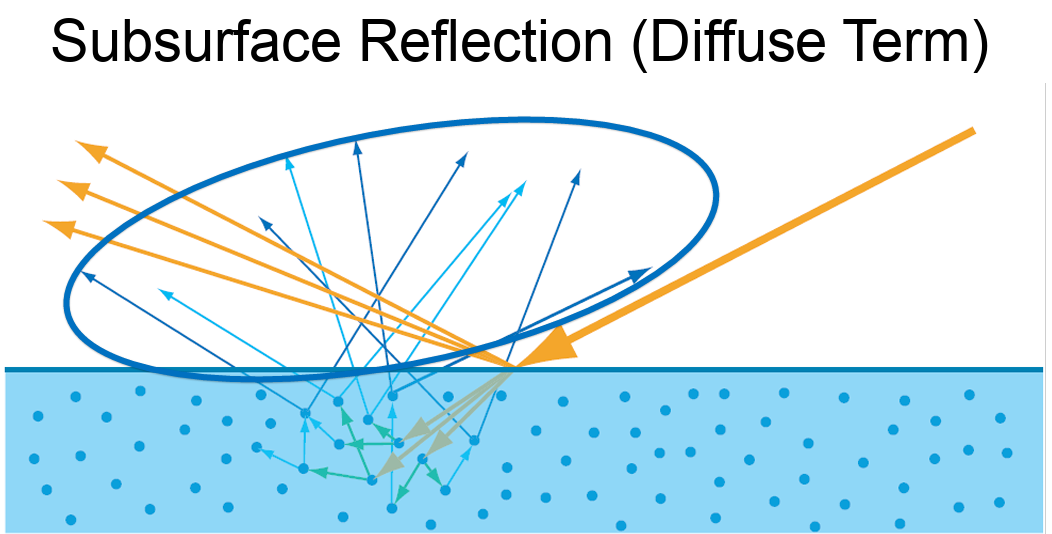
Some of the light reflects off the surface, creating visible highlights. The rest penetrates into the material, where it becomes attenuated due to absorption and scattering within the medium. This process is responsible for effects like subsurface scattering and volumetric absorption, which are essential for rendering realistic materials such as skin, wax, milk, or water.
A common real-world example is holding your finger up to sunlight. You’ll notice a glowing red edge around the silhouette of your finger—this is light scattering beneath the surface of the skin and exiting at different points. It demonstrates how light can enter a translucent material, bounce around internally, and emerge with a diffused, softened appearance. All these are called subsurface scattering.
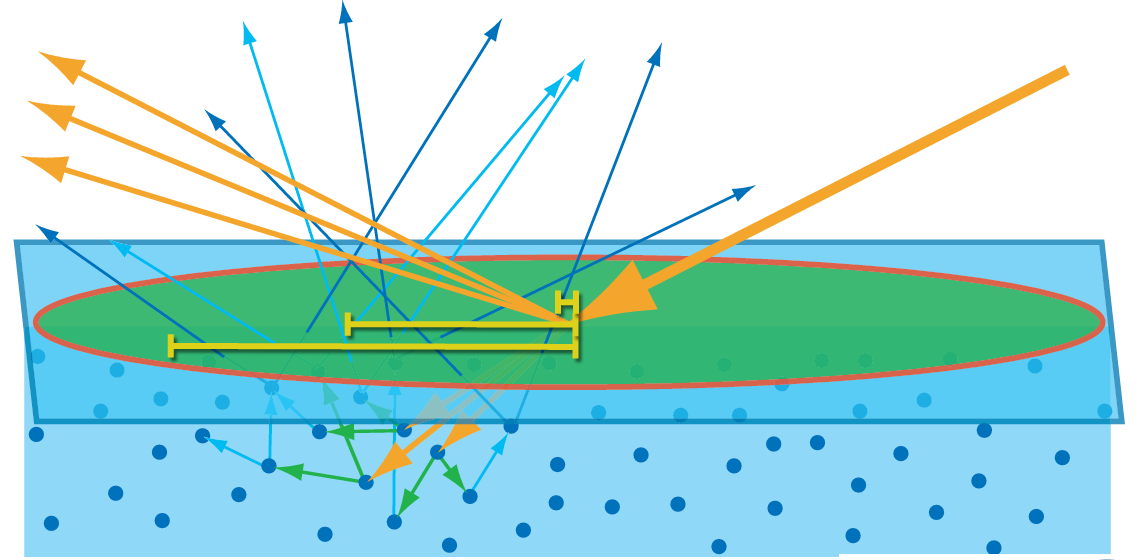
If the area below picture are smaller than one pixel, then we can treat them as a local point, treating like one particle as shown on next image.
Mathematics
Radiance is a physical quantity that measures the intensity of light traveling along a specific direction — essentially, how much light energy is flowing through a point in a specific direction. In rendering, this typically corresponds to the light that reaches the camera through a pixel along a ray.
Radiance is spectrally varying, meaning it can be described across different wavelengths (or as RGB in discrete form).
The unit of radiance is: W / (m²·sr)
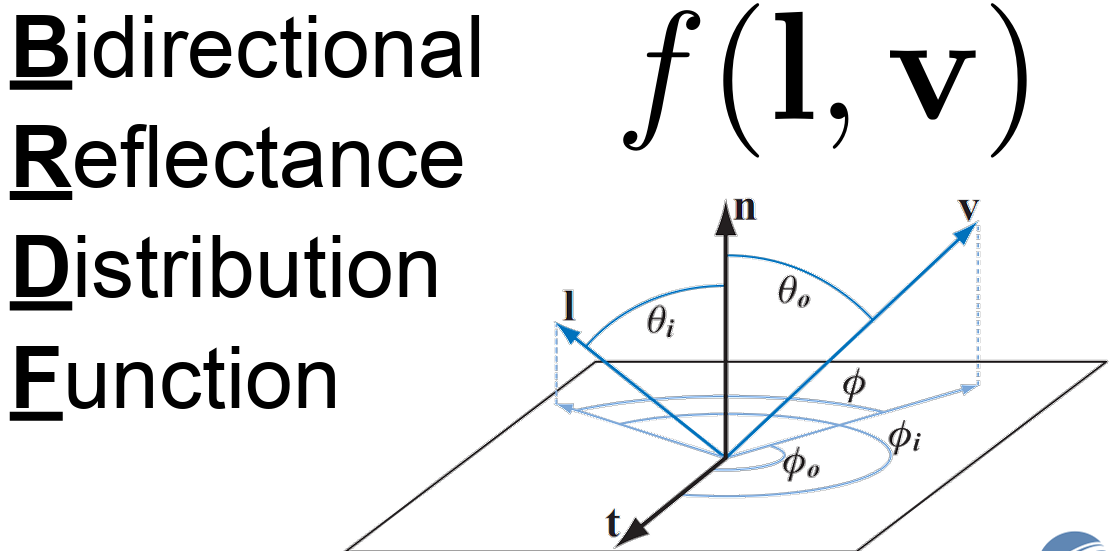
BRDF
The Bidirectional Reflectance Distribution Function (BRDF) defines how light is reflected at an opaque surface. The BRDF is defined as the ratio of the reflected radiance in a specific outgoing direction to the incident irradiance from a specific incoming direction, for given azimuth and zenith angles of both incidence and reflection.
Intuitively, the way a surface appears depends on two things:
The direction of incoming light (where the light is shining from)
The viewing direction (where the camera or eye is positioned)
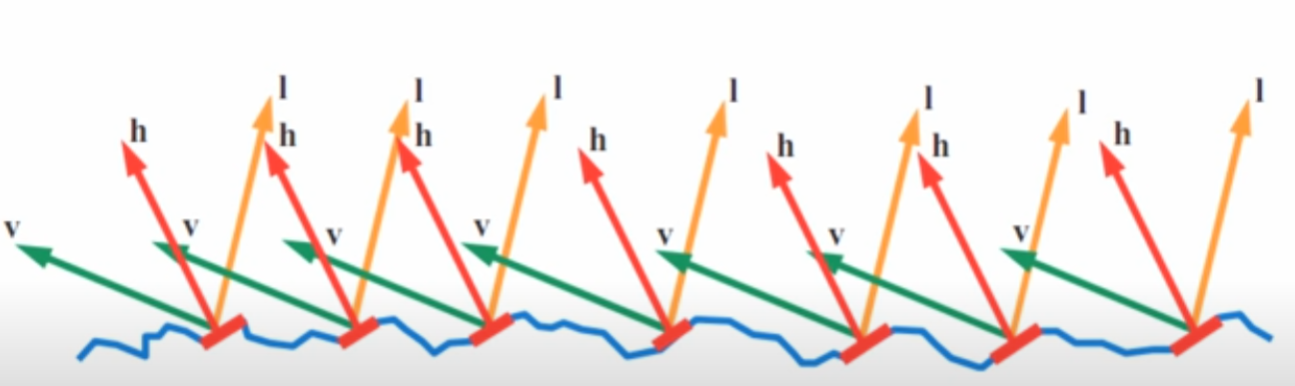
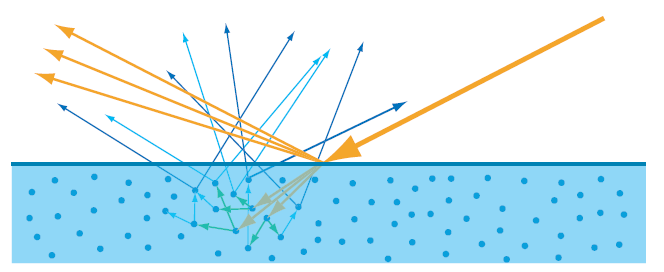
l represent the light direction, and v as a view direction. If you take a closer look on image below, we can actually calculate how much lights are coming through that patch into one points.
Now, we can truly define the what is really the definition of BRDF. Suppose we are given an incoming light direction ωᵢ (a unit vector pointing toward the surface), and an outgoing/viewing direction: ωₒ (a unit vector pointing away from the surface, typically toward the camera). BRDF can be defined as the ratio of the quantity of relfected light in direction ωₒ, to the amount of light that reaches the surface from direction ωᵢ. Which means, the quqntity of light reflected from the surface in direction ωₒ. Lo, and the amount of light arriving from direction ωᵢ, Ei.
The BRDF is the ratio of the differential outgoing radiance 𝑑𝐿𝑜(𝜔𝑜) in direction 𝜔𝑜 to the differential incoming irradiance 𝑑𝐸𝑖 from direction 𝜔𝑖.
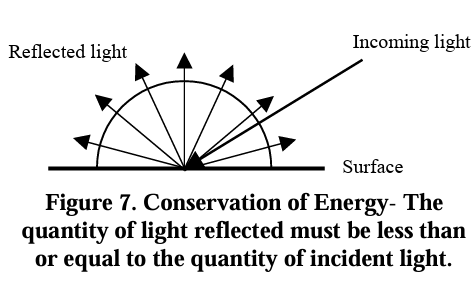
There are two classes of BRDFs and two important properties. BRDFs can be classified into two classes, isotropic BRDFs and anistorpics BRDFs. The two important properties of BRDFs are reciprocity and conservation of energy. Reciprocity states that the BRDF remains unchanged when the directions of incoming and outgoing light are swapped. In other words, the ratio of reflected radiance in one direction to the irradiance from another direction is the same, regardless of whether the directions are reversed:
Conservation of energy ensures that the total reflected energy from a surface cannot exceed the total incoming energy. That is, the BRDF must not allow more light to be reflected than is received, ensuring energy is preserved in the system as shown below
Reflectance Equation
All of the things we cover now reveal as one equation called reflectance equation. Outgoing Radiance from a point equals to the integral of incoming radiance times BRDF times the sign Factor over the hemisphere of incoming directions. Note that it is component-wise RGB multiplication. In detail, Lo is basically what we want to calculate in the pixel shader. Li(l) is the amount of incoming light (RGB). ndotl is the factor that increase and decrease the light power. f(l,v) is the BRDF term, then we integral all that terms. Unit-wise, Lo(V) is RGB, f(l,v) is RGB, Li(l) is also RGB with scalar. So output must be RGB.
Microfacet Theory
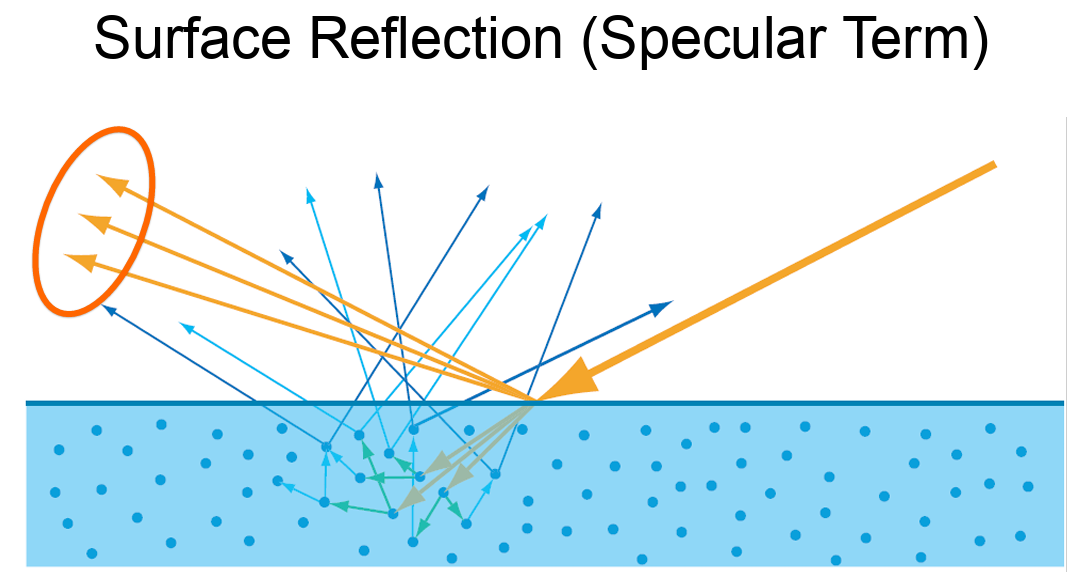
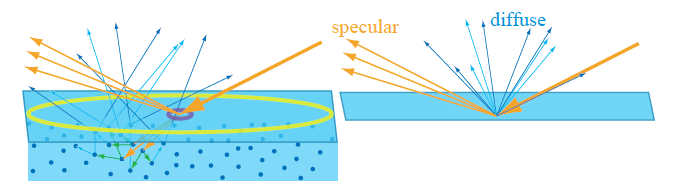
To achieve a visually immersive experience, both the diffuse and specular components of light reflection are important. Let’s begin by examining the specular term.
Microfacet Theory provides a framework for modeling surface reflection on rough or non-optically-flat surfaces. Rather than treating a surface as perfectly smooth, it assumes the surface is composed of many tiny, flat facets—each acting like a perfect mirror. Depending on the surfaces, BRDFs output term can be varied.
By zooming in on a small surface region, we approximate it as a collection of microscopic facets, each with its own orientation. At any given point, light may be reflected or refracted depending on the orientation of the microfacets. This interpretation allows us to derive realistic BRDFs that account for the surface roughness and the distribution of microfacet normals.
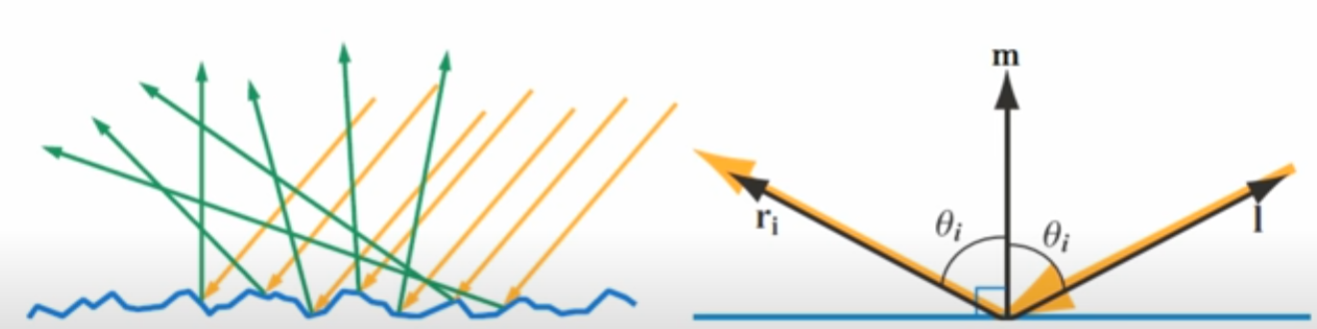
The half vector is simply the direction that the microfacets must be aligned with in order to reflect light from the light direction L into the view direction V.
In other words, the proportion of light that is reflected from L to V depends on how many microfacets have their surface normals aligned with this half vector. These microfacets act like tiny mirrors that perfectly reflect light when their normals match the half vector. The more microfacets oriented in the direction of H, the stronger the specular reflection in the view direction V. This is basically halfway vector calculation in phong model.
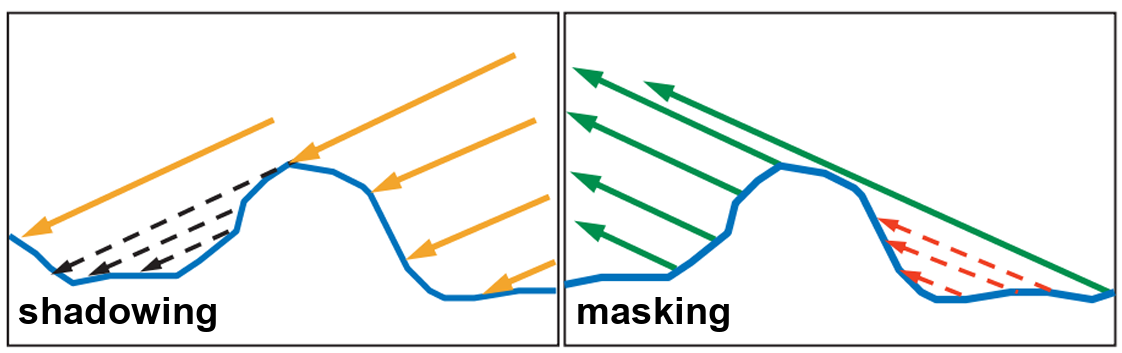
Depending on the surface geometry, not all microfacets aligned with the half vector can contribute to reflection. For example, if a nearby facet is taller and blocks the incoming light from reaching a microfacet, this is known as shadowing. On the other hand, if the reflected light from a microfacet is blocked in the direction of the viewer, this is referred to as masking. In reality, the some light can reach into shadow area, but Micro BRDFs ignore all that.
Microfacet Specular BRDF
This is the general form of Microfacet Specular BRDF.
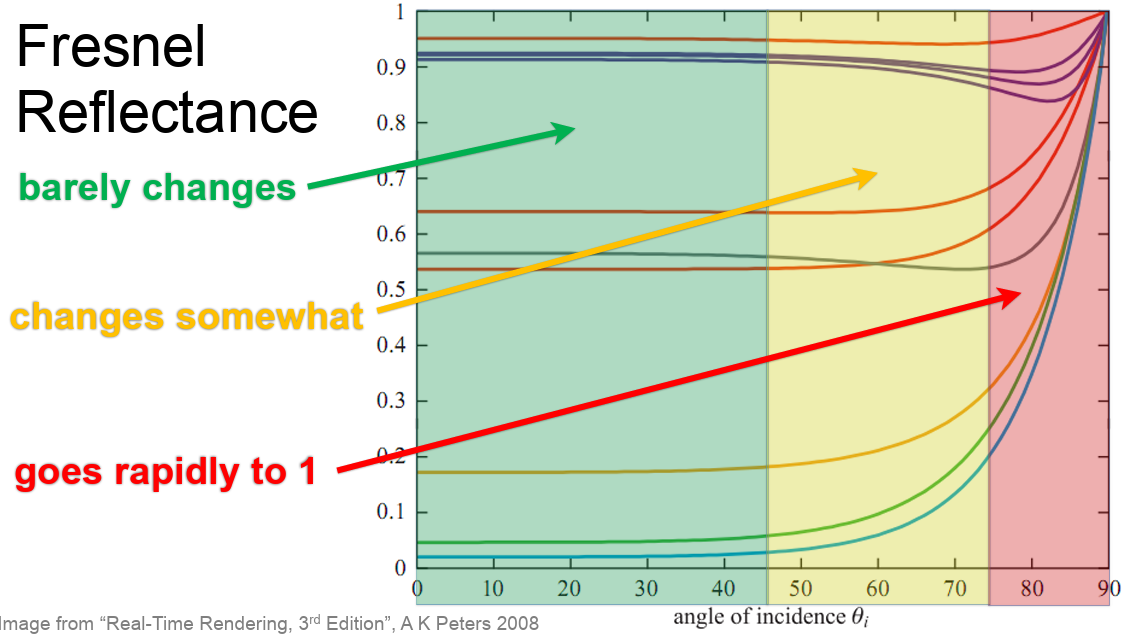
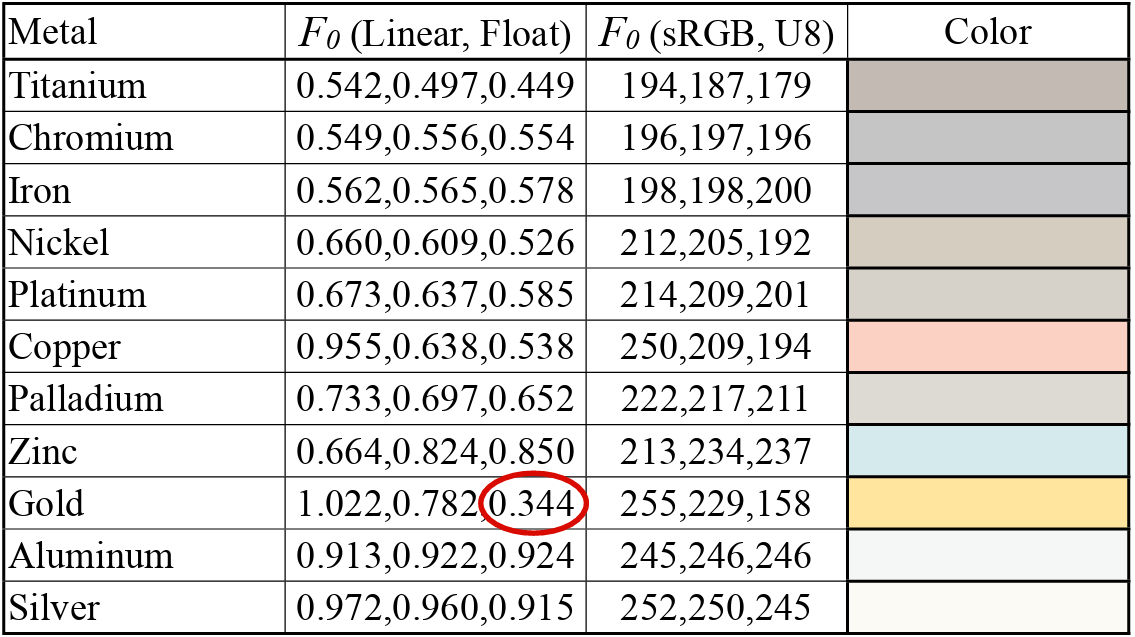
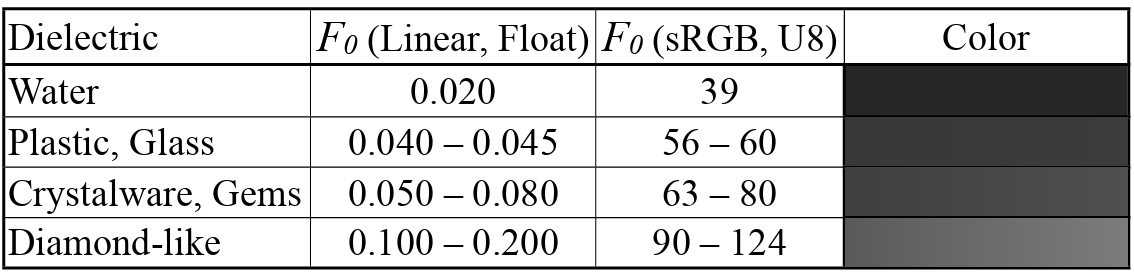
F(l,h) is Fresenel Reflectance. This basically show depending on the view direction(incident angle) and surface normal, and the RoI. The vale of frasnel can be varied as shown below.
Since the barely change parts is kind of like a starting point (parameter), so that we can tweak them from there. The image below shows each fresnel value for each metal and dielectric.
The speaker mentioned that Schlick Approximiation is good enough to implement.
The normal distribution D(h), describes how densely microfacet normals are aligned with a given half-vector direction h. In simple terms, it tells us how many microfacets are oriented in a way that would reflect light from the incoming direction L toward the outgoing view direction V. Since perfect specular reflection happens only when the microfacet normal matches the half-vector (the vector halfway between light direction L and view direction V), D(h) essentially controls the shape and sharpness of the specular highlight. You can actually see all those functions in Cook-Torrance
Finally, the geometry function, often denoted as G(l, v, h), accounts for shadowing and masking effects caused by the microgeometry of a surface. Shadowing occurs when incoming light (from direction l) is blocked by parts of the surface before it can reach a microfacet. Masking happens when the reflected light (toward the view direction v) is blocked by other parts of the surface, preventing it from escaping.
So, G(l, v, h) tells us how much of the microfacet reflection is actually visible, based on how the surface self-occludes due to its roughness.
The image below is commonly used, smith function, to illustrate the concept of the geometry function, as it has been both mathematically and physically validated:
Putting It All Together
D(h) (Normal Distribution Function): Describes how many microfacets are oriented in the direction of the half-vector h, which is the direction needed to reflect light from L to V. It essentially tells us how aligned the surface microfacets are with the ideal reflection direction.
F (Fresnel Term): Tells us how reflective each of those microfacets are, depending on the viewing angle and material properties.
G(l, v, h) (Geometry Function): Tells us how many of those microfacets are visible and not occluded, meaning they can actually participate in reflecting light from the light direction L to the view direction
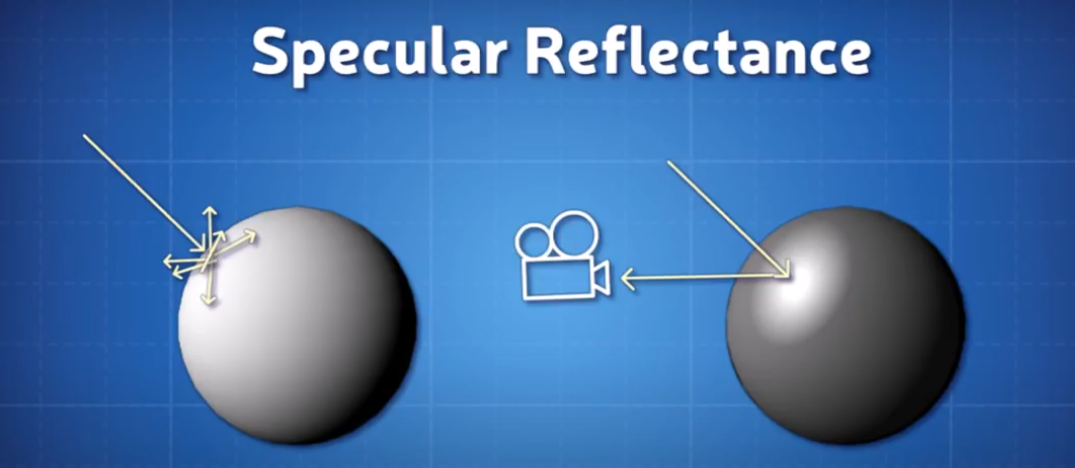
In physically based rendering (PBR), we often split surface reflection into diffuse and specular components. The diffuse term accounts for the light that enters a surface, scatters beneath it, and then exits in a different direction.
Lambertian Diffuse Model assumes light is scattered equally in all directions, and the surface looks the same from all viewing angles. Fairly simple and works well for matte surfaces like a paper.
Diffuse BRDF (Lambert): 𝑓𝑑 = C𝑑 / 𝜋, where the C𝑑 is the diffuse color. In real world, the rougher surfaces doen’t scatter light perfectly evenly. For example, skin, cloth have subsurface scattering and edge darkening. A specular reflection becomes sharper, the diffuse should became broader (vice versa). Thus Lambertian diffuse isn’t always phsycially accurate when the rough microfacet is applied.
The speaker also mentioned that Diffuse Roughness = Specular Roughness. It’s because of the assumption. “If the surface is rough for specular, it must also be rough for diffuse” but the assumption is wrong because specular roughness comes from surface microgeometry, and diffuse roughness is caused by the subsurface scattering, material properties, and light diffuion inside the medium..
Results
Of course, this is a summary based on content from SIGGRAPH and various other sources, so it might not be perfect or comprehensive. However, I thought it would be helpful for the understanding stage, so I put together a blog post to organize the information.
이미지 기반 Lighting 도 결국엔 Physically Based Rendering 과 비슷한 Technique 이다. Unreal Engine 에서도 사용이 된다고 한다. 결국에는 “Lighting Based on Data Stored in An Image” 라고 생각을 하면 된다.
Physically Based on Shading 안에서 일단, Lighting 에는 두개의 정보가 있다. Direct Diffuse, Direct Specular, Indirect Diffuse, Indirect Specular Term 이 있다. 일단 Diffuse 자체는 얼마나 빛이 Scatter 되는지를 나타낸다. (그래서 Labertian Reflectance) 하지만 아래의 그림 처럼 Material Definition 을 정확하게는 알지못한다. (하지만 Roughness 과 matte 는 판단 가능하지만, Glossy 는 모른다.)
이걸 판단하기 위해서는, Specular Reflectance 가 필요하다. 아래처럼 matte 같은 경우에는 대부분 Bounce 되지만, Glossy 인 물체에는 Camera Align 되면서 Single Direction 인 빛을 반사한다. 이말은 결국에는 카메라 시점에 따라서 빛이 물체에 어디에 빛을 비추는지가 Tracking 이 된다는 소리이다.
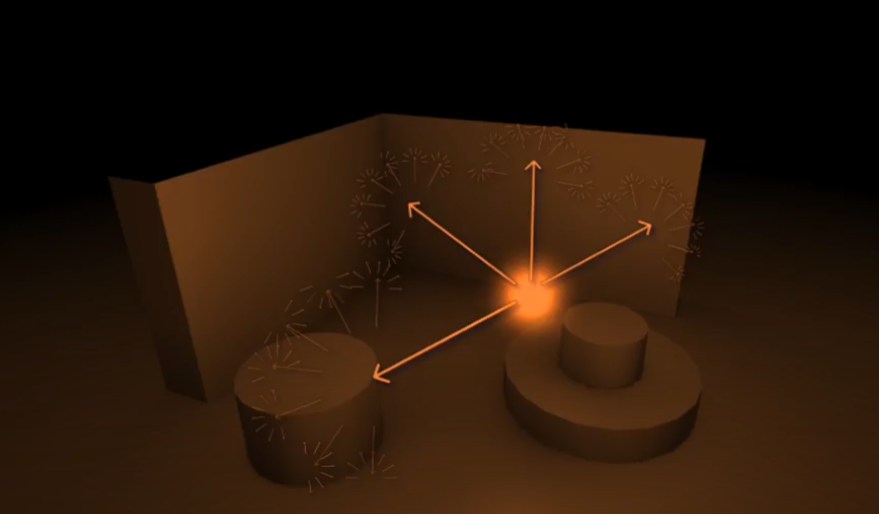
Direct 와 Indirect 의 차이를 보자면, 결국엔 DirectLight 과 PointLight 이 대표적인 Source 인것 같다. Indirect 같은 경우에는 DirectLight Source 가 어떠한 물체에 부딫혔을때, 반사광들이 Indirect Light Source 라고 말할수 있다. 아래의 그림을 보자면, Point Light 은 결국엔 Diffuse Direct Light 이며, 물체에 부딫혔을때 반사되는 빛들이 Indirect Light 이라고 할수 있다. 그 다음 이미지가 Indirect Diffuse Lighting 에 의해서 주변이 밝아지는 현상을 뜻한다. (즉 이말은 Directional Light 보다 더 밝게 주변이 빛춰진다.)
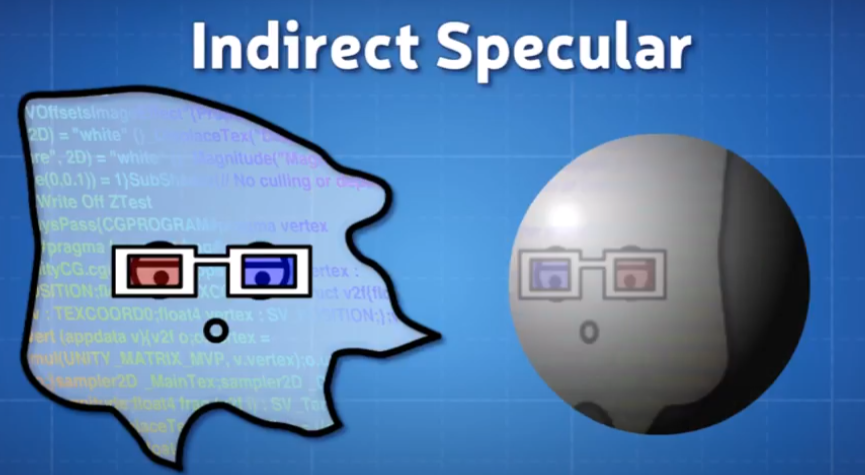
Indirect Specular 같은 경우는 High Glossy 에서 나타내는 현상중에 하나이다. 아래 처럼 glossiness 가 높으면 높을수록 반사되는게 보인다? 반사되는게 보인다는건, Model Mesh 주변(Enviornment) 를 볼수있다 라고 말할수 있다.
이제 IBL 하고 연관되게 설명을 하자면, 이렇게 Indirect 를 모두 계산을 할수는 있지만 아무래도 한계점이 있다. 그래서 하나의 Light Source 가 있다고 가정하고, 모든 면에서 사진을 찍어서, Lookup Texture 로 만들면 좋지 않을까? 라는 형태가 Cubemap 형태 인것이다.
그리고 Unreal 에서 사용되는 Image-Based Lighting 의 공식은 아래와 같다. 그리고 이 공식에 대한 HLSL 에 대한 설명은 여길 찾아보면 좋을것 같다.
위 처럼 결국에는 Cubemap 이 어떻게 생성이됬고, 어떤게 IBL 을 어떻게 계산하는지는 Environmental Mapping 에서 보았다. 그럼 구현 단계를 생각을 해보자.
일단 IBL Texture 같은 경우, 위에서 이야기한것처럼 specular / diffuse IBL DDS Files 예제 들이 존재 할것 이다.
그리고 코드로서는, CubeMapping Shader 에서는 Specular (빛이 잘 표현되는) Texture 만 올리고, Model 을 나타내는 Pixel Shader 에서는 Specular 와 diffuse texture 을 둘다 올리면 된다. (CPU 쪽 Code 는 생략)
그래서 HLSL 에서는, Cube Texture 를 받아서, Sampling 을 하고, 평균을 내서 Specular 는 표현을 하고, Texture 를 사용한다고 했을시에는 아래 처럼 분기처리해서 Diffuse 값에다가 은은하게 표현이 가능하다.
“Fresnel Reflection describe the behavior of light when moving between media of differing refractive indices”. 결국 말을 하는건 빛이 다른 굴절률(Refractive Index) 가지고 있는 물질(Media) 에 어떻게 표현하는지를 나타낸다고 한다. 아래의 그림처럼, 다른 n1, n2 물질이 있다고 하면, 빛은 일부는 반사하고, 일부는 굴절한다. 그걸 표현한게 아래의 그림이다. 그리고 Snell’s law 를 통하면, 각 Incident Angle 과 Refractive Angle 의 관계를 표현을 하면 sin(theta(i)) / sin(theta(t)) = n2/n1 표현을 할수 있다.
그렇다면, 이 식을 어떻게 이제껏 사용했던걸로 사용하자면, Specular(반사광) 에다가 곱해주면 된다. 일단 물질의 고유의 값을 표현할 NameSpace 로 묶어 준다. 그리고 결국엔 이 값들을 Material 값들을 ConstantBuffer 안에다가 같이 넣어주면 된다.
그이후에 CPU 에서 어떻게 Resource 가 Binding 되는건 생략을 하도록 하자.
HLSL 쪽을 한번 보자. SchlicFresnel 의 공식은 아래와 같다.
그리고 HLSL 에서 표현을 하면, 아래와 같이 표현이 가능하다. 여기에서 1 - cosTheta 가 결국에는 내가 바라보는 각도에따라서 Normal 과 90 도라고 한다면, 0 이 되므로, 가장자리쪽이고, 0 에 가까우면 가장자리가 아니라는것이다, 즉 가장자리라고 함은 빛을 더많이 받고, 그렇지 않는 경우에는 값이 작은 값들이 들어오고, Cubemap 에 있는걸 그대로 빛출것이다.














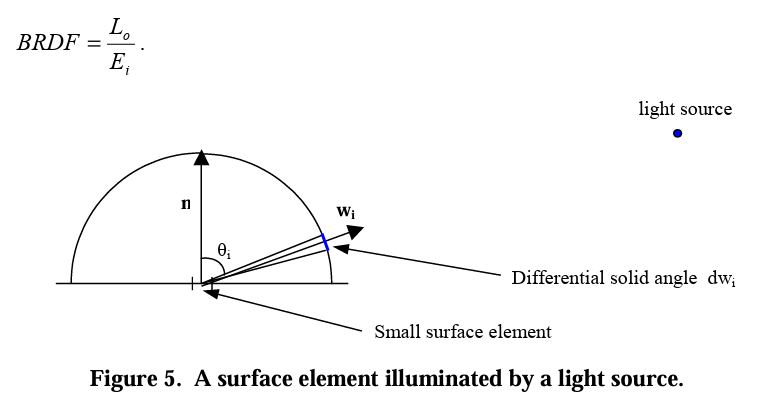 \[f_r(\omega_i, \omega_o) = \frac{dL_o(\omega_o)}{dE_i(\omega_i)}\]
\[f_r(\omega_i, \omega_o) = \frac{dL_o(\omega_o)}{dE_i(\omega_i)}\]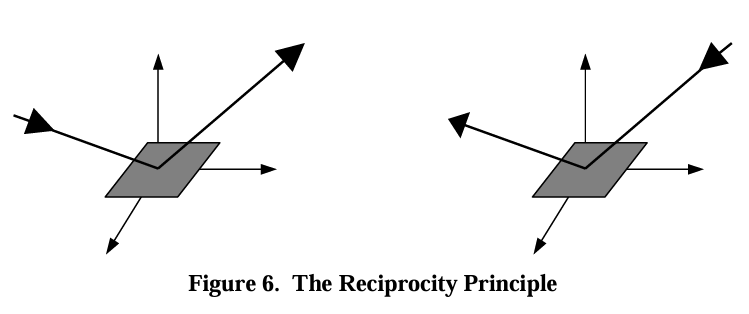 \[\text{BRDF}_{\lambda}(\theta_i, \phi_i, \theta_o, \phi_o) = \text{BRDF}_{\lambda}(\theta_o, \phi_o, \theta_i, \phi_i)\]
\[\text{BRDF}_{\lambda}(\theta_i, \phi_i, \theta_o, \phi_o) = \text{BRDF}_{\lambda}(\theta_o, \phi_o, \theta_i, \phi_i)\]