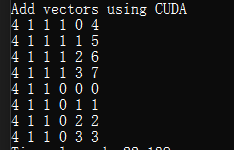
Previous Post 글에서 봤듯이, Addition 을 Block 하나를 여러개의 Threads 들을 사용해서, Vector Addition 을 할수있다. 만약에 그럼 여러개의 Block 을 쪼개서 총 8 개의 사이즈를 가지고 있는 Array 를 더하려면 어떻게 하냐? 라고 물어볼수 있다 생각보다 간단하다. Block 두개를 사용해서, Thread 4 개씩 할당할수 있다. 아래의 코드 Segments 를 봐보자. 아래처럼 Block 2 개, thread 개수 4 개 이런 방식으로 구현을 하면 된다. 우리가 궁금한거는 결국 이 덧셈이 어떻게 되는지가 궁금한 포인트이다. 그러기 때문에 아래처럼 속도가 느려지더라도, printf 를 통해서, 볼수 있다. int i = blockDim.x * blockIdx.x + threadIdx.x 라고 써져있다. blockIdx.x 하고 threadIdx 는 대충 이해가 갈것이다. 하지만 BlockDim 은 뭔가라고 한번쯤 고민이 필요하다.
일단 위의 코드를 Printf 한 결과값을 한번 봐보자. 아래의 결과값을 보자면, Thread Block 은 4 x 1 x 1 이다. 그말은 Thread 의 개수 하나의 Block 당 4 개의 Thread 를 의미한다. 그리고, Block Index 는 총 2 개의 Block 을 사용하니 0, 1 로 나오며, 이제 ThreadIdx 는 그대로 나온다. 하지만 여기서 중요한건 바로 1 부터 돌아갔다는 소리이다. Multithreading 을 하다 보면 순서에 상관없이 돌기 때문에 그 환경 때문에 먼저 실행되는건 일이 끝난 순서대로 되서 순서와 상관없이 Operation 만 끝내면 된다는 방식에서 온거이다. 그리고 i 의 계산의 결과 값들을 봐도 우리가 예상하지 못한 결과를 볼수 있다.
결국에는 그럼 우리가 어떻게 Debugging 하지? 라는 질문이 있다.. 어찌저찌 됬든간에, CUDA 안에 있는 Thread Block Index, Thread Index, Block Dimension 같은 경우를 봐야하지 않을까? 라는게 포인트이다. Nsight 를 쓰면 굉장히 잘나와있다. 아래의 그림을 보면, 굉장히 Visualization 이 생각보다 잘되어있다. 안에 있는 내부 구성요소는 거의 위와 구현한 부분을 매칭하면서 보면 좋을것 같다.
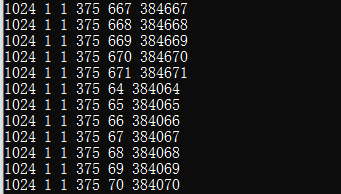
아래의 코드 같은 경우 대용량의 Data 처리를 위한 예제 코드라고 볼수 있다. 64 같은 경우는 내 컴퓨터 스펙중에 Maximum Threads Per Dimension 안에 있는 내용을 인용했다. 물론 이때는 Printf 를 쓰면 과부하가 걸릴수도 있으니 결과값만 확인하자. 물론 아래의 그림같이 Printf 를 한경우도 볼수 있다.
마침 Closure => Functor (Lambda Expression), Capture 이 부분이 생각보다 까다롭지 않을까? 싶었는데, 완전 C++ Syntax 가 똑같다. 단지 어떤 타입에 따라서 복사를 하는가에 따라서 다르다. (ex: C++ 에서 는 & (reference) 로 보낼지, 그냥 복사 Capture로 부를지를 [] or [&] 이런식으로 사용할수 있다, 하지만 swift 에서는 struct 는 value type 이므로 => 복사, class 처럼 reference type 이면, 주솟값을 넣어주는 형태)
Escaping Closure
이 부분을 이해하기위해서는 함수의 끝남! 을 잘 알아야한다. 예를 들어서 어떤 함수에서, closure() 가 바로 실행된다고 한다고 하자. 우리가 기대하고 있는거는 함수가 실행되고, closure 가 실행되는 방식으로 한다고 하자. 그러면 잘 작동이 될거다. 하지만 만약 비동기 처리가 이루어진다면 어떻게 되는걸까? 함수안에 내부 closure 는 실행이 될때까지 기다리고 있지만, 이미 그함수는 끝난 상태가 되버릴수있다. 그러면, 함수 내부에서 비동기 처리가 되는거가 아닌, 어떤곳에서 (ex: main) 에서 비동기 처리가 될거다. 그러면 빠져나가지도 못하는 상황이 되버린다. 이걸 방지할수 있는방법이 바로 @escaping 이라고 보면 된다. 기본적으로 closure 는 non-escaping 이다.
아래의 코드를 봐보자, 3 초 이후에 DispatchQueue 에서 비동기를 실시를 할건데, 이때 바로 들어가야하는게 @escaping keyword 이다. 즉 어떤 함수의 흐름에서, closure 가 stuc 한 부분을 풀어줘야 closure 의 끝맺음이 확실하다는것이다. (물론 함수 주기는 끝나게 된다.) 참고로 @Sendable Keyword 를 안쓴다면 Error 를 표출할것이다. 그 이유중에 하나는 일단 compleition (closure type) 은 referance type 이며, 이것을 비동기처리내에서 사용하려면, Thread Safe 라는걸 보장을 해야하는데, compiler 에서는 모른다. 그래서 명시적으로 Type 을 지정해줘야한다.
그리고 closure 측면에서는, 파라미터로 받은 클로저는 변수나 상수에 대입할수 없다. (이건 알아야 하는 지식중에 하나다, 가끔씩 compiler error 가 안날수도 있다.) 중첩 함수 내부에서, 클로저를 사용할 경우, 중첩함수를 return 할수 없다. 즉 함수의 어떤 흐름이 있다고 하면, 종료되기 전에 무조건 실행 되어야 한다는것이다. 근데 또 특이 한점 하나가 있다. 아래의 코드를 잠깐 봐보자.
자 거시적으로 봤을때는 closure 에 return 값을 기대할수도 있고, 없을수도 있다. 그걸 Optional(?) type 을 사용했다. Optional 을 사용한다고 하면, optional type argument 이기때문에 이미 escaping 처리가 될것이다. 라고 말한다. 즉 closure type 이 더이상 아니다. 그래서 자동적으로 escaping 한다고 보면 될것 같다.
Capture Ref & Caputer Value
이게 해깔릴수 있으니 정리를 해보자 한다. 일단 바로 코드 부터 보는게 좋을것 같다. 일단 Value Type 인 Struct 를 사용해서 구현을 해본다고 하자. 일단 Struct 가 Type 이 Value Type 이니까? 당연히 Capture 을 하면, 당연히 복사가 이뤄지기때문에 값이 안바뀐다고 생각은 할수 있다. 하지만, closure capture 자체가 기본이 변수의 메모리값을 참조 하기 때문에, person.age 의 주솟값을 reference 로 받기때문에 closure capture 가 reference 형태로 되는것이다. 그 아래의 것은 copy 다. 이건 capture 할 list 를 넘겨주는데, 이건 closure 가 생성하는 시점의 값을 하나 강하게 들고 있다고 볼수 있다. (즉 capture 한 값을 가지고 있다는것) 그러기때문에 capture list 를 사용할때는, 값으로 들어가기때문에 변경되지 않는다. 참고로 weak 를 사용하게 된다면, compiler 에서는 class 또는 class-bound protocol-types 라고 말할것이다. 즉 reference 타입일 경우에만 사용 가능 하다.
만약 multi-core CPU’s 또는 Parallel Execution 을 한다고 가정을 하면 어떨까? 즉 코어가 2개라면, 짝수개씩 병렬로 처리가 가능하다.
at time 0: CPU = core#0 = executes add_kernel(0, ...)
at time 0: CPU = core#1 = executes add_kernel(1, ...)
at time 1: CPU = core#0 = executes add_kernel(2, ...)
at time 1: CPU = core#1 = executes add_kernel(3, ...)
...
at time(n-1)/2: CPU = core#1 = executes add_kernel(SIZE - 1, ...)
그렇다면 GPU 는 어떻게 될까? GPU 는 엄청 많은 Core 들을 가지고 있기 때문에, 엄청난 Parallelism 을 가지고 갈수 있다. 아래와 같이 Time 0: 에 ForLoop 을 처리를 병렬 처리로 할수 있다는거다.
at time 0: CPU = core#0 = executes add_kernel(0, ...)
at time 0: CPU = core#1 = executes add_kernel(1, ...)
at time 0: CPU = core#2 = executes add_kernel(2, ...)
at time 0: CPU = core#3 = executes add_kernel(3, ...)
...
at time 0: CPU = core(#n-1) = executes add_kernel(SIZE - 1, ...)
위의 내용을 정리 하자면 아래와 같다. 즉 시간 순서별로 처리를 하는쪽은 CPU, 코어별로 처리를 하는건 GPU 라고 볼수 있다.
CPU Kernels
GPU Kernels
with a single CPU Core, For loop
a set of GPU Cores
sequential execution
parallel execution
for-loop
kernel lanuch
CPU[0] for time 0
GPU[0] for core #0
CPU[1] for time 1
GPU[1] for core #1
CPU[n-1] for time n-1
GPU[n-1] for core #n-1
CUDA vector addition 같은 경우 여러가지 Step 이 있다고 한다.
host-side
make A, B with source data
prepare C for the result
data copy host -> device
cudaMemcpy from host to device
addition in CUDA
kernel launch for CUDA device
result will be stored in device (VRAM)
data copy device -> host
cudaMemcpy from device to host
host-side
cout
Function Call vs Kernel Launch
기본적으로 C/C++ CPU 에서는 Function 을 부를때, Function Call 이라고 한다, 이의 Syntax 는 아래와같다.
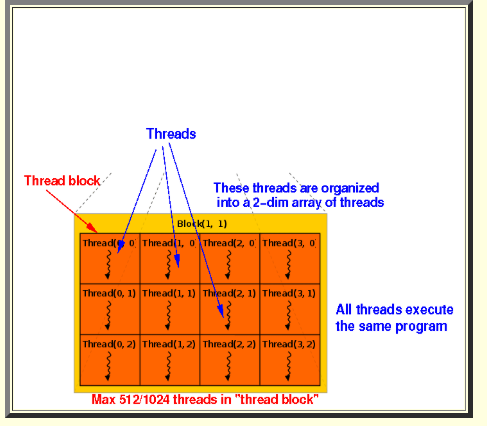
하지만 GPU 에서는 많이 다르다. c++ 에서 사용했을때와 다른 방식으로 Kernel(function) 을 사용한다. 이 Syntax 같 경우 Kernel launch Syntax 라고 한다. 의미적으로는 1 세트에 SIZE 만큼의 코어를 사용하겠다가 되는것이다. 또 다른 의미는 바로 1 이라는 인자 값은 Thread Block 몇개를 사용할건지와, 그 Thread Block 에 Thread 를 몇개 사용할지가 정의가된다. Thread Block 안에있는 Thread 는 코드 아래의 그림을 참조 하면 좋을것 같다.
실제로 예제 파일은 아래와같다. addKernel 이 실제로는 GPU 안에서의 FunctionCall 형태가 될거고, Index 를 넘기지 않기 때문에, 내부안에서 내 함수 Call 의 Index 를 찾을수 있다.
#include"cuda_runtime.h"
#include"device_launch_parameters.h"#include<stdio.h>__global__voidaddKernel(int*c,constint*a,constint*b){inti=threadIdx.x;printf("%d\n",i)c[i]=a[i]+b[i];}intmain(){constintarraySize=5;constinta[arraySize]={1,2,3,4,5};constintb[arraySize]={10,20,30,40,50};intc[arraySize]={0};// Add vectors in parallel.cudaError_tcudaStatus=addWithCuda(c,a,b,arraySize);if(cudaStatus!=cudaSuccess){fprintf(stderr,"addWithCuda failed!");return1;}printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",c[0],c[1],c[2],c[3],c[4]);// cudaDeviceReset must be called before exiting in order for profiling and// tracing tools such as Nsight and Visual Profiler to show complete traces.cudaStatus=cudaDeviceReset();if(cudaStatus!=cudaSuccess){fprintf(stderr,"cudaDeviceReset failed!");return1;}return0;}cudaError_taddWithCuda(int*c,constint*a,constint*b,unsignedintsize){// ...int*dev_a=0;int*dev_b=0;int*dev_c=0;cudaError_tcudaStatus;// Launch a kernel on the GPU with one thread for each element.addKernel<<<1,size>>>(dev_c,dev_a,dev_b);//...// cudaDeviceSynchronize waits for the kernel to finish, and returnscudaError_tcudaStatus=cudaDeviceSynchronize();cudaStatus=cudaMemcpy(c,dev_c,size*sizeof(int),cudaMemcpyDeviceToHost);if(cudaStatus!=cudaSuccess){fprintf(stderr,"cudaMemcpy failed!");gotoError;}Error:cudaFree(dev_c)cudaFree(dev_a);cudaFree(dev_b);returncudaStatus;}
아래와 같이, cudaDeviceSynchronize() 는 kernel 이 끝날때까지 기다렸다가 Error_t 를 Return 을 하게 된다. 성공을 하면, cudaSuccess 를 받는다. 그리고 마지막으로는 CPU 쪽으로 복사를 해준는 구문 cudaMemcpy(...) 가 존재하고, Error 를 내뱉는곳으로 가게된다면, CudaFree 를 해준다.
물론, Host 쪽에서 계속 쭉 Status 를 사용해서, 기다리지만 Kernel 안에서, Kernel launch 중에도 에러가 발생할수 있다. 그 부분은 아래와 같이 받을수 있다. 원래는 cudaError_t err = cudaPeekAtLastError() 그리고 cudaError_t err = cudaGetLastError() 가 있다 둘의 하는 역활은 동일하다! 하지만 내부안에서 있는 Error Flag 를 Reset 을 해주는게 cudaGetLastError() 이며, cudaPeekAtLastError() 는 Reset 을 하지 않는다. 그말은 Reset 을 last error only 가 아니라 모든 Error 에 대해서 저장을 한다고 생각을 하면된다. 그리고 아래처럼 Macro 를 설정을 해주어도 좋다.
// Check for any errors launching the kernelcudaError_tcudaStatus=cudaGetLastError();if(cudaStatus!=cudaSuccess){fprintf(stderr,"addKernel launch failed: %s\n",cudaGetErrorString(cudaStatus));gotoError;}cudaError_terr=cudaPeekAtLastError();// CAUTION: we check CUDA error even in release mode// #if defined(NDEBUG)// #define CUDA_CHECK_ERROR() 0// #else#define CUDA_CHECK_ERROR() do { \
cudaError_t e = cudaGetLastError(); \
if (cudaSuccess != e) { \
printf("cuda failure \"%s\" at %s:%d\n", \
cudaGetErrorString(e), \
__FILE__, __LINE__); \
exit(1); \
} \
} while (0)
// #endif
근데 여기서 궁금증이 있을수 있다. 예를 들어서, c++ 에서는 Return 의 반환값을 지정할수 있었지만, Kernel 은 그렇지 못하다. 무조건 void 로 return 하게끔해야한다. 이건 병렬처리를 하기 때문에, 100 만개의 병렬처리를 한다면 100 만개의 return 값을 가지게 되는데 이건 error code 에 더 가깝다. 그러면 계산이 끝났다라는걸 명시적으로 어떻게 확인하느냐가 포인트일 일것 같다. 바로 Memory 를 던져줬을떄, 그 배열을 update 해서 GPU 에서 CPU 로 데이터가 Memcopy 가 됬을때만 확인이 가능하다.
예제 파일로 Vector 안에 모든 Element 에 +1 씩 붙이는 프로그램을 실행한다고 하면 아래와 같이 정의할수 있다.
#include"cuda_runtime.h"
#include"device_launch_parameters.h"#include<stdio.h>__global__voidadd_kernel(float*b,constfloat*a){inti=threadIdx.x;b[i]=a[i]+1.0f;}intmain(){constintarrSize=8;constfloata[arrSize]={0.,1.,2.,3.,4.,5.,6.,7.};floatb[arrSize]={0.,0.,0.,0.,0.,0.,0.,0.,};printf("a = {%f,%f,%f,%f,%f,%f,%f,%f\n",a[0],a[1],a[2],a[3],a[4],a[5],a[6],a[7]);float*dev_a=nullptr;float*dev_b=nullptr;cudaError_tcudaStatus;cudaMalloc((void**)&dev_a,arrSize*sizeof(float));cudaMalloc((void**)&dev_b,arrSize*sizeof(float));cudaMemcpy(dev_a,a,arrSize*sizeof(float),cudaMemcpyHostToDevice);add_kernel<<<1,arrSize>>>(dev_b,dev_a);cudaStatus=cudaPeekAtLastError();if(cudaStatus!=cudaSuccess){fprintf(stderr,"addKernel launch failed: %s\n",cudaGetErrorString(cudaStatus));}cudaStatus=cudaDeviceSynchronize();if(cudaStatus!=cudaSuccess){fprintf(stderr,"cudaDeviceSynchronize r eturned error code %d after launching addKernel!\n",cudaStatus);}// ResultcudaStatus=cudaMemcpy(b,dev_b,arrSize*sizeof(float),cudaMemcpyDeviceToHost);if(cudaStatus!=cudaSuccess){fprintf(stderr,"cudaMemcpy failed!");}printf("b = {%f,%f,%f,%f,%f,%f,%f,%f\n",b[0],b[1],b[2],b[3],b[4],b[5],b[6],b[7]);cudaFree(dev_a);cudaFree(dev_b);return0;}
그리고 참고적으로 꿀팁중에 하나는 const char* cudaGetErrorName( cudaError_t err) 이 함수가 있다.cudaError_t 를 넣어서 확인이 가능하며, Return 이 Enum Type 의 String 을 char arr 배열로 받을수 있으니 굉장히 좋은 debugging 꿀팁일수 있겠다. 또 다른건 const char* cudaGetErrorString(cudaError_t err) err code 에 대한 explanation string 값으로 return 을 하게끔 되어있다. 둘다 cout << <<endl; 사용 가능하다.
cudaGetLastError() -> Thread 단위 처리
여러가지의 Cuda Process 가 돌릴때, 내가 사용하고 있는 프로세스에서 여러가지의 Thread 가 갈라져서, 이들 thread 가 Cuda system 을 동시에 사용한다고 한다라면, CUDA Error 를 어떻게 처리하는지에 대한 고찰이 생길수도 있다. 그래서 각 Cpu Thread 가 Cuda 의 커널을 독자적으로 사용한다고 가정을 하면 Cuda eror 는 Cpu thread 기준으로 err 의 상태 관리를 하는게 좋다.
Given an array of non-negative integers numbers, and a target number target, write a function solution that returns the number of ways to add or subtract these numbers without changing their order to reach the target number.
For example, using the numbers ``, you can make the target number 3 in the following five ways:
Intially, when I try to solve this problem, I was thinking that this is typcial dp problem in such that if you select one number in the array, then you can choose either - number or positive number. Then, I was thinking you don’t really have to approach this problem with dp, just simple bfs or dfs can be possible
If we want to solve this by the recursive way, we need a constraint, constraint would be the vector’s size. Let’s say that we’ve started the +1 by adding the first number in the vector, then index has been already incremented by 1. So, by having the index, we can track what index we’ve used to get the target value.
Top-down Approach: This it pretty special one, one thing we need to notice is the way to save the totalsum with current sum. This is efficient way to store all possible sum. For example, if the total sum is 5, then -5 + 5 = 0 which is index at 0, -4 + 5 = 1(index), -3 + 5 = 2(index), and so on. This ensures the O(n * totalSum);
WOW, People are very ge, see if I understand correctly. The point here is to treat this problem as subset sum. I know the main goal is to find all possible solution to get to the target, but i think it’s good to break things up.
For example, if we have the list [1 -2, 3, 4], we set this as two sets one for +, the other for -. Then we can separate this s1 = [1, 3, 4] and s2 = [2]. Then, we can conclude that the totalSum = s1 + s2, but to find the target would be target = s1 - s2 (because we need to think all possible occurence of sum to be target). Then, we can write the equation like 2s1 = totalSum + target, then s1 = totalSum + target / 2. We call this as diff if this diff is not an integer, then we don’t have to compute.
Then, we can implement this idea. But this code doesn’t consider the sign changes, it’s either select one or not, which treat this as subset sum. (you should check any dp problem if you are curious because filling dp table is very similar to LCS or matrix multiplication)
intcache(intj,intsum,vector<int>&nums){if(j==0)returnsum==0?1:0;// doneif(dp[j][sum]!=-1)returndp[j][sum];intx=nums[j-1];intans=cache(j-1,sum,nums);if(sum>=x)ans+=cache(j-1,sum-x,nums);returndp[j][sum]=ans;}intfindTargetSumWays(vector<int>&nums,inttarget){constintn=nums.size();intsum=accumulate(nums.begin(),nums.end(),0);intdiff=sum-target;// Check if it's possible to achieve the targetif(diff<0||diff%2!=0)return0;diff/=2;vector<vector<int>>dp(n+1,vector<int>(diff+1,-1))returncache(n,diff,nums);}
classSolution{public:vector<int>findOrder(intnumCourses,vector<vector<int>>&prerequisites){intn=prerequisites.size();// same as numCoursesvector<int>inDegree(numCourses,0);vector<int>result;unordered_map<int,vector<int>>adj;for(inti=0;i<n;i++){adj[prerequisites[i][0]].push_back(prerequisites[i][1]);}// fill inDegreefor(autoit:adj){for(intnode:adj[it.first])inDegree[node]++;}queue<int>q;for(inti=0;i<numCourses;i++){if(inDegree[i]==0)q.push(i);}while(!q.empty()){intnode=q.front();q.pop();result.push_back(node);for(inte:adj[node]){inDegree[e]--;if(inDegree[e]==0)q.push(e);}}reverse(result.begin(),result.end());if(result.size()==numCourses){returnresult;}return{};}};
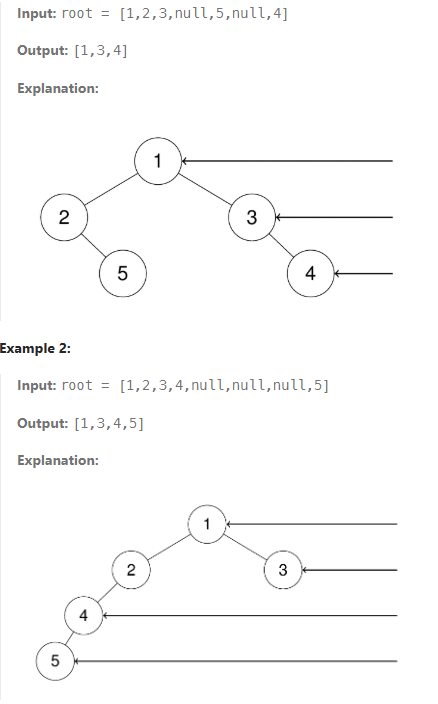
Given the root of a binary tree, imagine yourself standing on the right side of it, return the values of the nodes you can see ordered from top to bottom. The detail images are below:
Implementation
This is basically, we’re looking at the binary tree from right side. In the first example, the output would be [1,3,4]. In here, we can think that we can just traverse right side, but the next example shows that we can’t just look at the right traversal. nodes that are hide, show in the left root tree. So how do we approach to this problem. Since binary tree is part of complete binary tree, we can do level-order traversal.
The level traversal is basically below in c++.
vector<vector<int>>levelOrder(Node*root){if(root==nullptr)return{};// Create an empty queue for level order traversalqueue<Node*>q;vector<vector<int>>res;// Enqueue Rootq.push(root);intcurrLevel=0;while(!q.empty()){intlen=q.size();res.push_back({});for(inti=0;i<len;i++){// Add front of queue and remove it from queueNode*node=q.front();q.pop();res[currLevel].push_back(node->data);// Enqueue left childif(node->left!=nullptr)q.push(node->left);// Enqueue right childif(node->right!=nullptr)q.push(node->right);}currLevel++;}returnres;}
Then let’s solve it. let’s use deque instead because it’s efficient! What we want is we are going to use levelLength which it comes from the idea of complete tree. If the size is not equal to q.size() - 1, it’s the left view, and if it’s same it’s going to be right view.
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/vector<int>rightSideView(TreeNode*root){vector<int>result;if(root==nullptr)returnresult;deque<TreeNode*>q;q.push_back(root);while(!q.empty()){intlvlLength=q.size();for(inti=0;i<lvlLength;i++){TreeNode*node=q.front();q.pop_front();// forces to get the right value if(i==lvlLength-1){result.push_back(node->val);}if(node->left!=nullptr){q.push_back(node->left);}if(node->right!=nullptr){q.push_back(node->right);}}}returnresult;}
There are a total of numCourses courses you have to take, labeled from 0 to numCourses - 1. You are given an array prerequisites where prerequisites[i] = [ai, bi] indicates that you must take course bi first if you want to take course ai. For example, the pair [0, 1], indicates that to take course 0 you have to first take course 1. Return true if you can finish all courses. Otherwise, return false.
Implementation
This problem resembles a typical graph problem, where detecting cycles is crucial. While DFS can be used with states like visited, not visited, and visiting, we’ll employ topological sorting via Khan’s algorithm instead. This choice is suitable for our needs because it efficiently orders nodes in a directed acyclic graph (DAG), which is relevant if we assume the graph doesn’t contain cycles.
Topological sorting relies on the indegree of nodes. Nodes with an indegree of 0, meaning they have no incoming edges, are always placed at the front of the queue. This is because they have no dependencies and can be processed immediately.
edges are pointed to 0 -> 1 (in order to take 0, we need to take 1)
what we need to prepare is the result vector, and the inDegree vector adjacent link list (link list can be just vector).
Then, we would have to everything we need. From prerequsites vector, we would need to push the course we need to take, then directed to prerequsite node(class). Then we increment inDegree vector. why are we increasing the inDegree vector, because we need to tell that there is edge points to 1 (in above example)
Then, we need to prepare for the queue, and check if the indegree is 0, which means it’s gonna be first to check. Then, we’re gonna check the outgoing edge from each node, and we are going to get rid of that edge (-=). Then, there is no incoming edge, then we push to the queue. Then we just have to check whether the size is equal or not to number of courses.
Reviewing what I studied, how this work will be explained as well.
Network Flow & Flow Graph
A flow graph (flow network) is a directed graph where each edge (also called an arc) has a certain capacity which can receive a certain amount of flow. The flow running through an edge must be less than or equal to the capacity. Think of this way, we have a path from Chicago to Boston, and Boston to New York. From Chicago to Boston (6 cars allowed per min) & Boston to New York (3 cars allowed per min). Then after 1 min, the state would be 3 cars are still waiting to go to Boston, and 3 cars are already in New York. So, how do we solve it? We just send 3 cars in the beginning. In this case, we are going to define some terms ‘flow’ / ‘capacity’.
Ford Fulkerson Method & Edmonds-Karp
Problem Statement:
One of the special things about Ford Fulkerson Methods is that there are sink node and source node (think of source node as faucet, and the sink as drainer). To find the maximum flow (and min-cut as a byproduct), the Ford-Fulkerson method repeatedly findsaugmenting paths through the residual graph and augments the flow until no more augmenting paths can be found. Then what the heck is an augmenting path? The definition of an augmenting path is a path of edges in the residual graph with unused capacity greater than zero from the source to sink.
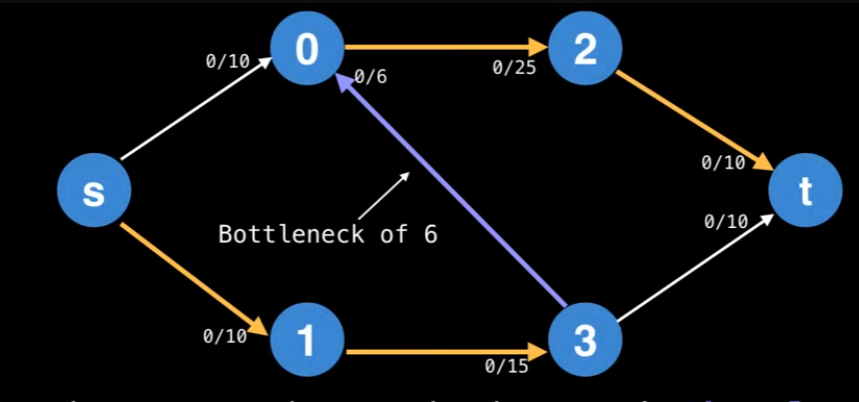
The reason why it’s stated as a method, not an algorithm is because of flexibility in selecting augmenting paths (unspecified by Ford Fulkerson Method). If the DFS algorithm is chosen to get the augmenting path, every augmenting path has a bottleneck. The Bottleneck is the “smallest” edge on the path. We can use the bottleneck value to augment the flow along the paths. You can actually look at the image below, and the operation is min(10-0, 15-0, 6-0, 25-0, 10-0) = 6. (bottleneck value shown below)
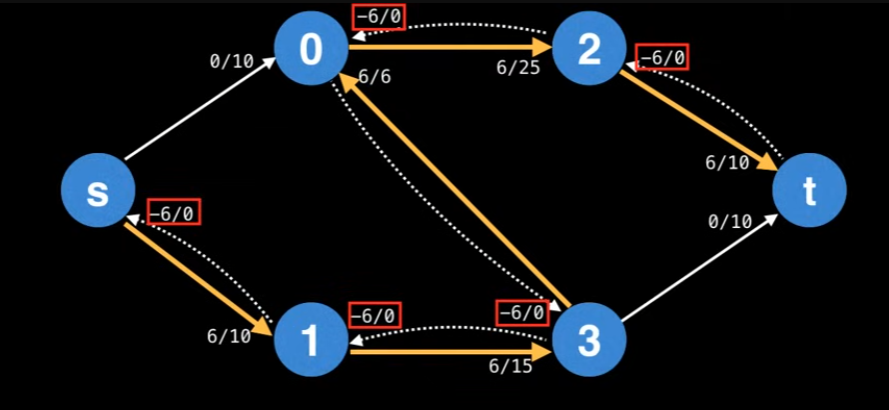
we mean updating the flow values of the edges along the augmenting path. For the forward edges, this means increasing the flow by the bottleneck value. Also, when augmenting the flow along the augmenting path, you also need to decrease the flow along each residual edge by the bottleneck value. Then why are we decreasing the flow? Because what we want to achieve is to get the max flow, which requires considering all cases to fill the flows. By using the decrease, residual edges exist to “undo” bad augmenting paths which do not lead to a maximum flow.
we can define the residual graph. The residual graph is the graph which contains residual edges, as shown below:
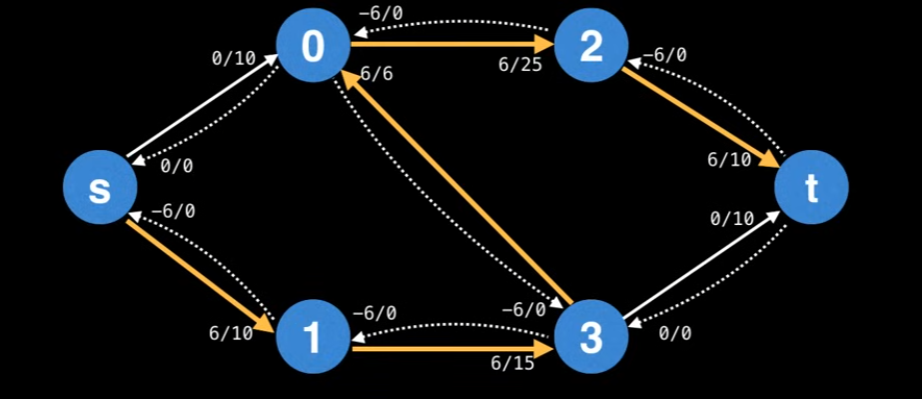
Then, we could ask ourselves is “Residual edges have a capacity of 0? Isn’t that forbidden? How does that work?”. You might be able to think of the remaining capacity of an edge e (residual or not) as: e.capacity - e.flow. This ensures that the remaining capacity of an edge is always non-negative.
So, let’s wrap it up: the Ford-Fulkerson method continues finding augmenting paths and augments the flow until no more augmenting paths from s->t exist. The sum of the bottlenecks found in each augmenting path is equal to the max-flow. (So it doesn’t really matter how you find the augmenting path). The basic steps are:
Find an augmenting path
Compute the bottleneck capacity
Augment each edge and the total flow
Edmonds-Karp Algorithm
The Edmonds-Karp algorithm is a specific implementation of the Ford-Fulkerson method. The key difference is that Edmonds-Karp uses Breadth-First Search (BFS) to find augmenting paths, whereas the general Ford-Fulkerson method doesn’t specify how to find these paths.
By using BFS, Edmonds-Karp guarantees finding the shortest augmenting path (in terms of number of edges) at each step. This leads to a better time complexity than using arbitrary path-finding methods.
The time complexity of Edmonds-Karp is O(V × E²), where V is the number of vertices and E is the number of edges in the graph. This is a significant improvement over the general Ford-Fulkerson method, which has a time complexity of O(E × f), where f is the maximum flow value (which could be very large if edge capacities are large).
Implementation
classFordFulkerson{public:vector<bool>marked;vector<FlowEdge*>prev;doublevalue;FordFulkerson(FlowNetwork&g,ints,intt):marked(g.V),prev(g.V),value(0.0){while(HasAugmentingPath(g,s,t)){// Find the minimum Flow from the pathdoublebottlNeck=numeric_limits<double>::max();for(intv=t;v!=s;v=prev[v]->Other(v)){bottlNeck=min(bottlNeck,prev[v]->ResidualCapacityTo(v));}for(intv=t;v!=s;v=prev[v]->Other(v)){prev[v]->AddResidualFlowTo(v,bottlNeck);}value+=bottlNeck;Print(g);}}boolHasAugmentingPath(FlowNetwork&g,ints,intt){fill(marked.begin(),marked.end(),false);queue<int>q;// BFSmarked[s]=true;q.push(s);while(!q.empty()){intv=q.front();q.pop();for(FlowEdge*e:g.Adj(v)){intw=e->Other(v);if(!marked[w]&&e->ResidualCapacityTo(w)>0)// <- TODO: BFS와의 차이 확인{prev[w]=e;marked[w]=true;q.push(w);}}}returnmarked[t];}};
Min-Cut Theorem
One of the most important results in network flow theory is the Max-Flow Min-Cut Theorem. This theorem states that the maximum flow in a network equals the capacity of the minimum cut.
A cut in a flow network is a partition of the vertices into two disjoint sets S and T, where the source s is in S and the sink t is in T. The capacity of a cut is the sum of the capacities of the edges going from S to T.
After the Ford-Fulkerson algorithm terminates, the min-cut can be found by:
Running a DFS or BFS from the source in the residual graph
Vertices reachable from the source form set S, the rest form set T
The edges going from S to T in the original graph form the min-cut
This min-cut represents the bottleneck in the network - the set of edges that, if removed, would disconnect the source from the sink.
swift 에서의 struct 또는 class 에서는 member variable 을 property 라고 한다. 이 Property 들은 상태를 체크 할수 있는 기능을 가지고 있다. 천천히 알아보자.
Store Property: member variable 결국, 상수 또는 변수를 저장한다고 보면된다. 이부분은 init() 에 instantiate 할때 설정을 해줘야한다.
Type Property: static variable 이다. 객채가 가지고 있는 변수라고 생각하면 된다. 여러가지의 Instantiate 을 해도 공유 되는 값이다.
Compute Property: 동적으로 계산하기 때문에, var 만 가능하며, getter / setter 를 만들어줄수있다. getter 는 필수 이며, setter 는 구현 필요없다. (즉 setter 가 없다면, 굳이 getter 를 사용할 필요 없다.)
Property Observer: 이건 Property 들의 상태들을 체크를 할 수 있다. 상속받은 저장/연산 Proprty 체크가 가능하며, willSet 과 didSet 으로 이루어져있다. willSet 같은 경우, 값이 변경되기 전에 호출이되고, didSet 은 값이 변경 이후에 호출한다. 접근은 newValue 와 oldValue 로 체크할수 있다.
Lazy Stored Property: 이 부분은 lazy 라는 Keyword 로 작성이되며, 값이 사용된 이후에 저장이 되므로, 어느정도의 메모리 효율을 높일수 있다.
importFoundationstructAppleDevice{varmodelName:StringletreleaseYear:Intlazyvarcare:String="AppleCare+"/// Property Observervarowner:String{willSet{print("New Owner will be changed to \(newValue)")}didSet{print("Changed to \(oldValue) -> \(owner)")}}/// Type PropertystaticletcompanyName="Apple"/// Compute PropertyvarisNew:Bool{releaseYear>=2020?true:false}}varappDevice=AppleDevice(modelName:"AppleDevice",releaseYear:2019,owner:"John")print(appDevice.care)appDevice.owner="Park"
Instance Method 도 마찬가지이다. 위의 코드에 method 를 넣어보자. struct 일 경우에는 저장 property 를 method 에서 변경하려면, mutating keyword 가 필요하다. 그리고 다른건 static 함수이다. 이 부분에 대해서는 따로 설명하지 않겠다.
importFoundationstructAppleDevice{varmodelName:StringletreleaseYear:Intlazyvarcare:String="AppleCare+"varprice:Int/// Property Observervarowner:String{willSet{print("New Owner will be changed to \(newValue)")}didSet{print("Changed to \(oldValue) -> \(owner)")}}/// Type PropertystaticletcompanyName="Apple"/// Compute PropertyvarisNew:Bool{releaseYear>=2020?true:false}mutatingfuncsellDevice(_newOwner:String,_price:Int)->Void{self.owner=newOwnerself.price=price}staticfuncprintCompanyName(){print(companyName)}}varappDevice=AppleDevice(modelName:"AppleDevice",releaseYear:2019,price:500,owner:"John")print(appDevice.care)appDevice.owner="Park"AppleDevice.printCompanyName()
Let’s review the @State keyword. In order for View to notice, that the value of @State change, the View is re-rendered & update the view. This is the reason why we can see the change of the value in the View.
StateObject & ObservableObject
Now, let’s talk about StateObject & ObservableObject. If we have a ViewModel, called FruitViewModel, as below. Let’s review the code. FruitViewModel is a class that conforms to ObservableObject protocol. It has two @Published properties: fruitArray & isLoading. This viewmodel will be instantiated in the ViewModel struct. This FruitViewModel also controls the data flow between the View and the ViewModel. Then we have navigation link to the SecondScreen struct. Then, we pass the FruitViewModel to the SecondScreen struct. In the SecondScreen struct, we have a button to go back to the ViewModel struct. In the SecondScreen, this can access the FruitViewModel’s properties (which in this case, fruitArray mainly).
There are two ways to instantiate the FruitViewModel. One is using @StateObject and the other is using @ObservedObject. For @StateObject, it’s used for the object that is created by the View. For @ObservedObject, it’s used for the object that is shared across the app. This means you can still use @ObservedObject for the object that is created by the View, but if it’s observableobject, it’s not going to be persisted. meaning the data will be changed when the view is changed. So, it will change everytime the view is changed where this wouldn’t be our case. So, that’s why we use @StateObject to keep the data persistence.
classFruitViewModel:ObservableObject{@PublishedvarfruitArray:[FruitModel]=[]// state in class (alert to ViewModel)@PublishedvarisLoading:Bool=falseinit(){getFruits()}funcgetFruits(){letfruit1=FruitModel(name:"Banana",count:2)letfruit2=FruitModel(name:"Watermelon",count:9)isLoading=trueDispatchQueue.main.asyncAfter(deadline:.now()+3.0){self.fruitArray.append(fruit1)self.fruitArray.append(fruit2)self.isLoading=false}}funcdeleteFruit(index:IndexSet){fruitArray.remove(atOffsets:index)}structViewModel:View{@StateObjectvarfruitViewModel:FruitViewModel=FruitViewModel()varbody:someView{NavigationView{List{iffruitViewModel.isLoading{ProgressView()}else{ForEach(fruitViewModel.fruitArray){fruitinHStack{Text("\(fruit.count)").foregroundColor(.red)Text(fruit.name).font(.headline).bold()}}.onDelete(perform:fruitViewModel.deleteFruit)}}.listStyle(.grouped).navigationTitle("Fruit List").navigationBarItems(trailing:NavigationLink(destination:SecondScreen(fruitViewModel:fruitViewModel),label:{Image(systemName:"arrow.right").font(.title)}))}}}}structSecondScreen:View{@Environment(\.presentationMode)varpresentationMode@ObservedObjectvarfruitViewModel:FruitViewModelvarbody:someView{ZStack{Color.green.ignoresSafeArea()VStack{Button(action:{presentationMode.wrappedValue.dismiss()},label:{Text("Go Back").foregroundColor(.white).font(.largeTitle).fontWeight(.semibold)})VStack{ForEach(fruitViewModel.fruitArray){fruitinText(fruit.name).foregroundColor(.white).font(.headline)}}}}}}
EnvironmentObject
EnvironmentObject is a bit same as @ObservedObject. The difference is that it’s used for the object that is shared across the app. This means you can still use @ObservedObject for the object that is created by the View, but if it’s observableobject, only the subview can access the data. But if you use EnvironmentObject, the data will be shared across the app. Obviously there is downside to this, which means it’s slower than @ObservedObject. So if we have a hierchical structure, we can use EnvironmentObject to share the data across the app. (if only needed). So that the child view can access the data from the parent view. Otherwise, you can easily use @ObservedObject and pass this to child view.
The example code is as below
//// EnvironmentObject.swift// SwiftfulThinking//// Created by Seungho Jang on 2/25/25.//importSwiftUI// What if all child view want to access the Parent View Model.// Then use EnvironmentObject.// You can certainly do pass StateObject / ObservedObject, but what// if you have a hierchy views want to access the parent views.// but might be slowclassEnvironmentViewModel:ObservableObject{@PublishedvardataArray:[String]=[]init(){getData()}funcgetData(){self.dataArray.append(contentsOf:["iPhone","AppleWatch","iMAC","iPad"])}}structEnvironmentBootCampObject:View{@StateObjectvarviewModel:EnvironmentViewModel=EnvironmentViewModel()varbody:someView{NavigationView{List{ForEach(viewModel.dataArray,id:\.self){iteminNavigationLink(destination:DetailView(selectedItem:item),label:{Text(item)})}}.navigationTitle("iOS Devices")}.environmentObject(viewModel)}}structDetailView:View{letselectedItem:Stringvarbody:someView{ZStack{Color.orange.ignoresSafeArea()NavigationLink(destination:FinalView(),label:{Text(selectedItem).font(.headline).foregroundColor(.orange).padding().padding(.horizontal).background(Color.white).cornerRadius(30)})}}}structFinalView:View{@EnvironmentObjectvarviewModel:EnvironmentViewModelvarbody:someView{ZStack{LinearGradient(gradient:Gradient(colors:[.blue,.red]),startPoint:.topLeading,endPoint:.bottomTrailing).ignoresSafeArea()ScrollView{VStack(spacing:20){ForEach(viewModel.dataArray,id:\.self){iteminText(item)}}}.foregroundColor(.white).font(.largeTitle)}}}
At the end…
Why do we use StateObject & EnvironmentObject? It’s matter of the lifecycle of the object as well as the MVVM Architecture. The MVVM Architecture is a design pattern that separates the UI, the data, and the logic. The StateObject is used for the object that is created by the View. The EnvironmentObject is used for the object that is shared across the app.