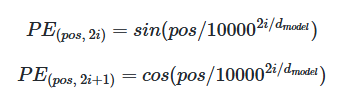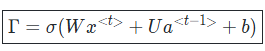I’m currently working on my own game engine, called Luna Game Engine. Sometimes, the workload can feel overwhelming, especially when balancing personal projects and portfolio building. I find that taking a break and reflecting helps me maintain focus and productivity.
While working on Luna, I often draw inspiration from existing game engines like Unreal Engine, Unity, and FrostBite. Each of these engines has a distinct philosophy and approach to game development. For example, Unity is particularly focused on multi-platform support, which makes it versatile for mobile, console, and desktop applications. There’s a great video on YouTube that outlines Unity’s roadmap and how they plan to evolve the engine.
One remarkable feature of Unreal Engine is its support for large-scale triangle meshes through Nanite. However, I am a bit concerned about the runtime performance when loading these heavy meshes. While the visuals are undeniably impressive, maintaining performance is always a critical consideration.
Unity’s collaboration with Zyva is also noteworthy, especially when it comes to realistic facial animations. The demo shows incredibly vivid muscle movements that mimic human expressions. This kind of technology could significantly impact the VR industry and even healthcare applications.
Personally, I have a soft spot for FrostBite, as I have enjoyed the Battlefield series for years. I also find it fascinating how the engine has evolved, especially for FIFA. In older versions, scoring from long-distance shots was quite easy, but recent iterations have introduced more nuanced physics and player attributes, making gameplay more realistic. Small details, like players sweating, might seem minor, but they reflect just how far game engines have come in terms of visual fidelity and realism.
As I continue developing Luna Game Engine, I aim to incorporate some of the strengths I admire in these established engines while maintaining my own vision. Taking time to study how industry leaders approach engine design helps me make more informed decisions about Luna’s features and structure.
The Vulkan is the graphical API made by Khronos providing the better abstraction on newer graphic cards. This API outperform? the Direct3D and OpenGL by explaining what it perform. The idea of the Vulkan is similar to the Direct3D12 and Metal, but Vulkan is cross-platform, and it can be used and developed in Linux or Window Environment.
However, the drawback of this could be is there will be many detailed procedure while using the Vulkan API, such as creating the buffer frame, managing the memory for buffer and texture image objects. That means we would have to set up properly on application. I realized that the Vulkan is not for everyone, it is only for people who’s passionate on Computer Graphics Area. The current trends for computer graphics in Game Dev, they are switching the DirectX or OpenGL to Vulkan : Lists of Game made by Vulkan. One of the easier approach could be is to learn and play the computer graphics inside of Unreal Engine and Unity.
By designing from scratch for the latest graphics architecture, Vulkan can benefit from improved performance by eliminating bottlenecks with multi-threading support from CPUs and providing programmers with more control for GPUs. Reducing driver overhead by allowing programmers to clearly specify intentions using more detailed APIs, and allow multiple threads to create and submit commands in parallel and Reducing shader compilation inconsistencies by switching to a standardized byte code format with a single compiler. Finally, it integrates graphics and computing into a single API to recognize the general-purpose processing capabilities of the latest graphics cards.
There are three preconditions to follow
Vulkan (NVIDA, AMD, Intel) compatible graphic cards and drivers
Expereince in C++ ( RAII, initializer_list, Modern C++11)
Compiler above C++17 (Visual Studio 2017, GCC 7+, Clang 5+)
While Vision Transformers (ViT) have shown strong performance in image classification. There are several limitations that arise when applying them to more and various computer vision tasks.
1. Fixed Patch Size & Lack of Local Content
ViT splits the image into fixed-size patches (e.g., 16x16), regardless of the underlying content
As a results:
The model may attent to meaningless or background regions (e.g white pixels) with no semantic values
If important visual elements are split across patch boundaries, local similarity between pixels is lost
Maybe the example I can think of is, a small object like a bird might get split between patches, causing the network to miss its continuity entirely.
2. Poor Handling of Scale Variations
ViT lacks mechanisms to handle scale variablity in visual tokens. In real-world images:
A bird could occupy 200x200 or just 20x20, but both should still be recognized as “a bird”
Without scale-awareness, the model struggles to generalize across different object sizes.
3. Quadratic Complexity
ViT’s self-attention has quadratic complexity with respect to the number of patches (i.e., ( O(n^2) )).
This becomes computationally expensive for high-resolution images commonly found in practice (e.g., 1920×1080).
4. Limited to Classification Tasks
ViT was initially designed for image classification, but many vision applications require more:
Object Detection: Unlike language tokens, visual elements vary widely in size and spatial distribution.
Semantic Segmentation: Image resolution is much higher than text sequences, requiring dense predictions across pixels.
A pyramid-like hierarchical structure, inspired by CNNs and U-Net
Shifted window-based local self-attention, which allows the model to:
Capture local context efficiently
Reduce computation to linear complexity with respect to image size
Scale well to high-resolution and dense prediction tasks
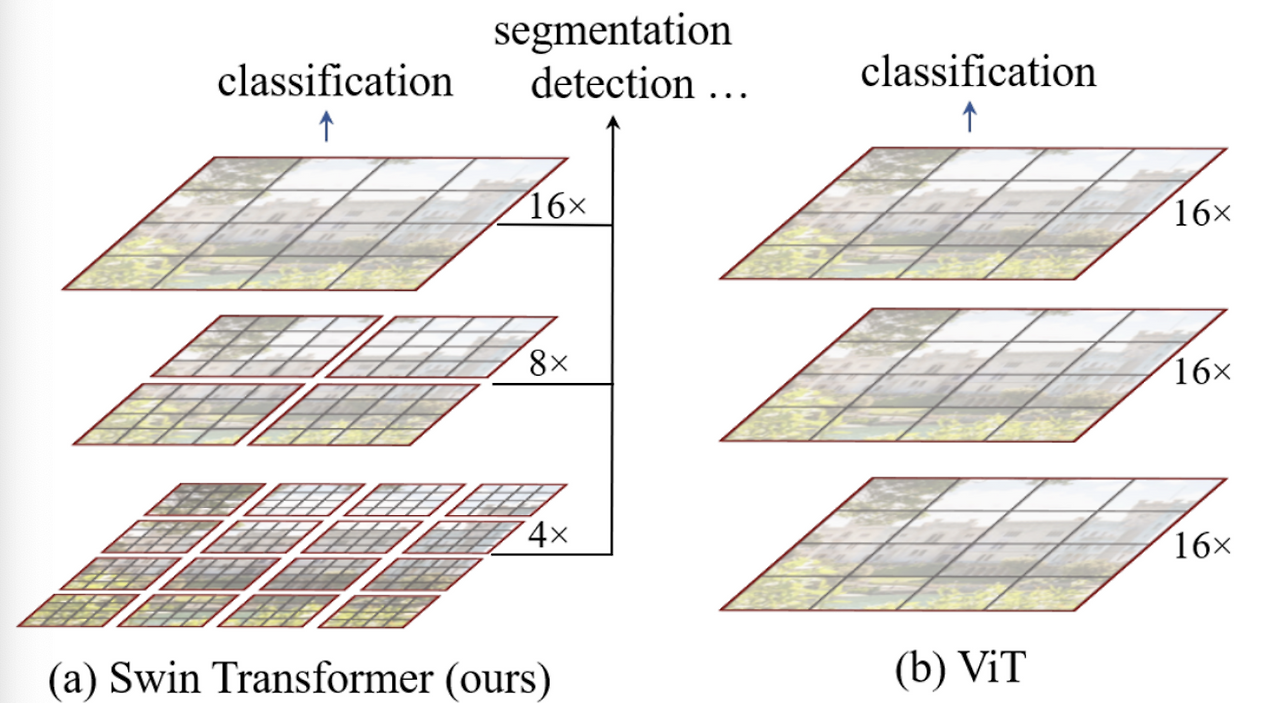
These architectural choices allow Transformers to be applied beyond classification—including detection and segmentation
A General Transformer Backbone for Vision
The diagram above illustrates the general structure of a Transformer-based vision backbone. The Swin Transformer begins by splitting the input image into small non-overlapping patches (gray outlines) and gradually builds up hierarchical representations by merging neighboring patches at deeper layers—similar to CNNs.
Local Self-Attention with Shifted Windows
To reduce computational complexity, Swin Transformer performs self-attention within non-overlapping windows (red outlines) rather than across the entire image.
These windows are fixed in size (e.g., 4×4 patches).
Attention is calculated only within each window, not globally.
As a result, computational complexity becomes linear with respect to image size, instead of quadratic.
This window-based local attention allows the model to efficiently process images of various sizes, since the number of windows scales with the image size.
Example: Window and Patch Hierarchy
Suppose the input image is divided into 16×16 windows, each window containing 4×4 patches.
Within each 4×4 window:
Self-attention is computed locally, without looking outside the window.
In deeper layers:
Neighboring patches are merged (e.g., combining 2×2 patches).
This reduces the total number of patches by a factor of 4, while increasing the spatial resolution of each patch (i.e., width × 2 and height × 2).
This hierarchical merging process enables the model to learn increasingly abstract and global features, while maintaining efficiency and scalability.
Multi-head Self-Attention in Swin Transformer
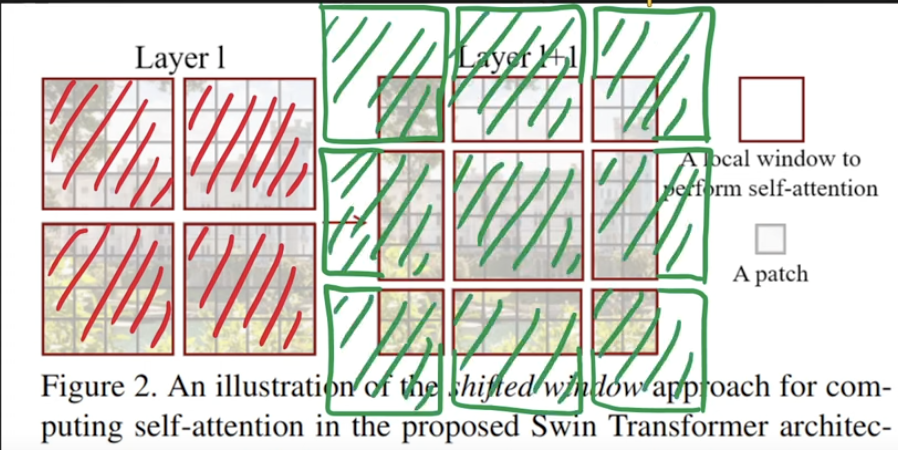
In Swin Transformer, attention is applied locally within windows. However, instead of applying the same partitioning across all layers, it introduces a clever mechanism: Shifted Windows, which allows the model to connect neighboring windows and capture richer context. Each patch in a window shares the same key set, which not only simplifies computation but also improves memory access efficiency—crucial for hardware acceleration as explain furthermore.
Notably, all windows in Swin are non-overlapping.
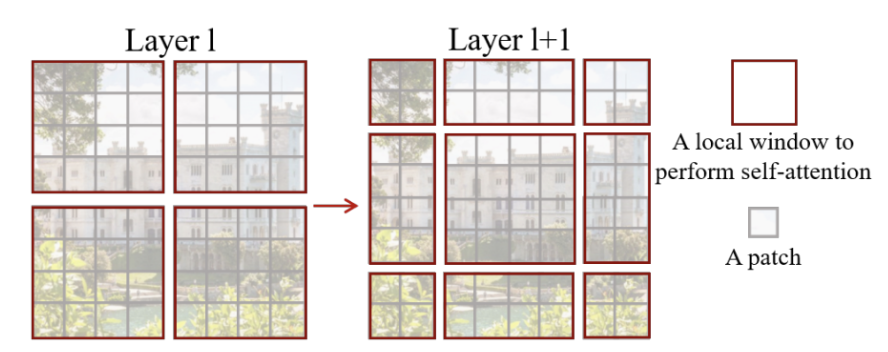
W-MSA (Window-based Multi-head Self-Attention)
In Layer 1 of the Swin Transformer block (left side of the original figure above), the image is divided into non-overlapping windows. Self-attention is applied within each window only, making it a local attention mechanism. This is referred to as W-MSA.
In Layer 2 (right side of the original figure), the windows are shifted relative to the previous layer. This allows self-attention to be computed across window boundaries, connecting adjacent regions. While traditional sliding windows can also cover neighboring areas, shifted windows maintain efficiency while introducing inter-window connections, enabling the model to capture global interactions gradually.
Traditional Multi-head Self-Attention (MSA) computes attention globally across all tokens in an image. While this enables long-range dependencies, it comes with a significant computational cost.
Before, the complexity of global self-attenion is:
MSA: Ω(MSA) = 4 * h * w * C^2 + 2 * (h * w)^2 * C
Where:
h, w = height and width of the feature map
C = number of channels
But there is a problem with this, if the input resolution increases, the quadratic term grows dramatically - making it inefficient for high-resolution images.
To address this, Window-based Multi-head Self-Attention (W-MSA) restricts attention to local windows of size M × M. Its complexity is:
W-MSA: Ω(W-MSA) = 4 * h * w * C^2 + 2 * M^2 * h * w * C
Here, M is a fixed window size (e.g., 7), making this approach linear in terms of image size. This dramatically reduces computational cost while retaining performance in local contexts.
Method
Complexity
Scales with Image Size?
MSA
O((h·w)^2)
❌ Quadratic
W-MSA
O(h·w) (when M is fixed)
✅ Linear
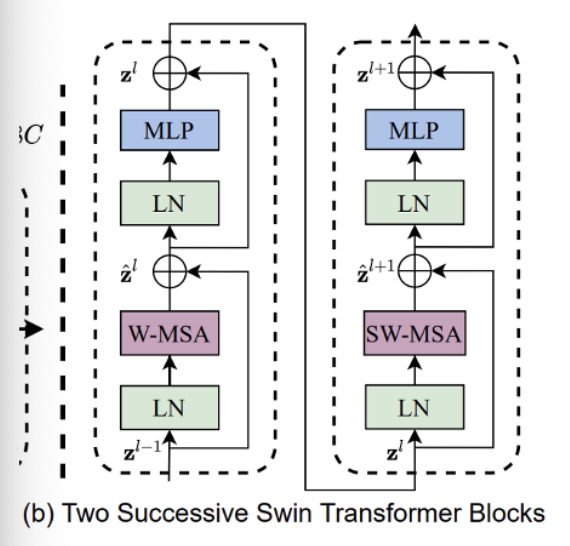
Also, the each swin transformer block consists of:
A W-MSA or SW-MSA module
A two-layer MLP with GELU activation
Layer Normalization before each sub-layer
A residual connection (skip connection) applied after each block
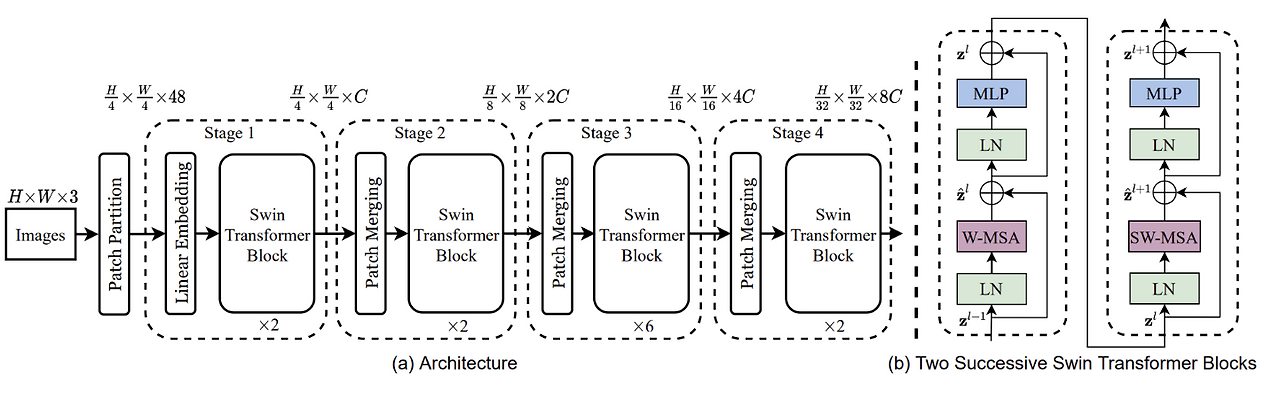
Model Architecture
The figure above illustrates the overall architecture of the Swin Transformer. Here’s how the input image is processed step-by-step:
Patch Partitioning The input image is first split into non-overlapping patches of size 4×4, resulting in patch tokens of shape 4×4×3. Each patch is then flattened and passed through a Linear Projection to form an embedding vector.
Linear Embedding These patch vectors are embedded into a fixed-dimensional space using a learnable linear layer. This prepares them for the Transformer blocks that follow.
Transformer Blocks (Stage 1) The embedded patches are fed into Transformer blocks, where self-attention is computed both within patches (local) and between patches (global). This stage captures fine-grained, low-level features.
Patch Merging (Stage 2) After Stage 1, a Patch Merging Layer is applied. This merges each group of 2×2 neighboring patches, concatenating their features into a single vector (dimension becomes 4C). A linear layer then reduces this to 2C, effectively reducing spatial resolution (by a factor of 2) and increasing the channel capacity.
Hierarchical Feature Learning (Stages 3 & 4) This patch merging process and Transformer block application are repeated multiple times, forming deeper stages. As a result, the feature maps get smaller in spatial dimensions but richer in representation—similar to how UNet or image pyramids work in traditional vision architectures.
Final MLP Head At the end of the final stage, a Multi-Layer Perceptron (MLP) head is applied to perform the final prediction task, such as classification or detection.
To explain furthermore on second layer, let’s look at the image below.
Shifted Windows in Swin Transformer
Let’s slowly wrap this, Swin Transformer, introduces a novel mechanism—Shifted Window Multi-head Self-Attention (SW-MSA)—to efficiently model long-range dependencies without incurring the high cost of global self-attention.
Why Shift Windows? The baseline attention mechanism, Window-based MSA (W-MSA), computes self-attention within non-overlapping windows. This is efficient, but it lacks cross-window communication.
To address this, shifted windows are applied in alternating Transformer blocks:
Each window is shifted by a fixed size (e.g., half the window dimension).
This causes adjacent windows to partially overlap.
As a result, tokens from different regions can now interact, enhancing the model’s representational power.
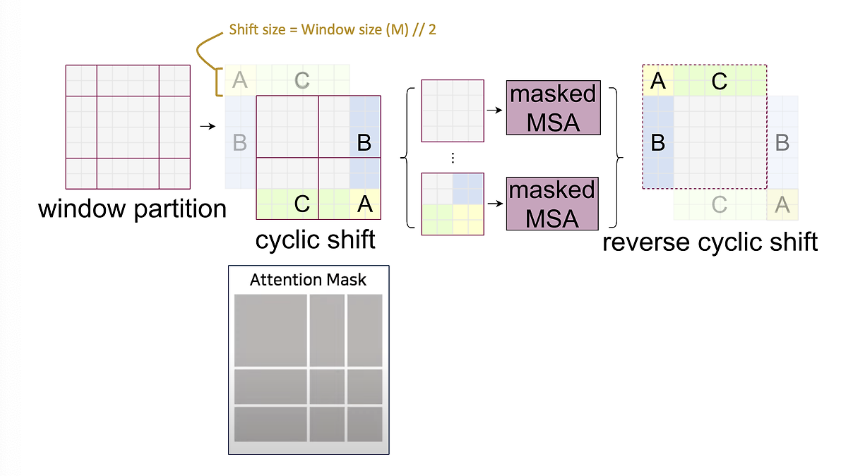
Cyclic Shift & Attention Masking
Shifting windows introduces new windows and disrupts alignment, potentially increasing computational complexity. Swin Transformer handles this elegantly using:
Cyclic Shift:
Instead of moving data in memory, patches are cyclically shifted (like a ring buffer), preserving the GPU’s memory alignment and restoring the original number of windows. (ex: a left-side window is shifted down and right, aligning back to the initial layout.)
Attention Masking:
After shifting, some patches may come from semantically unrelated areas.
Example: patches A, B, and C are visually close after the shift, but not contextually related.
A binary attention mask ensures that attention is only computed within valid, local regions.
After self-attention, the cyclic shift is reversed, restoring spatial structure.
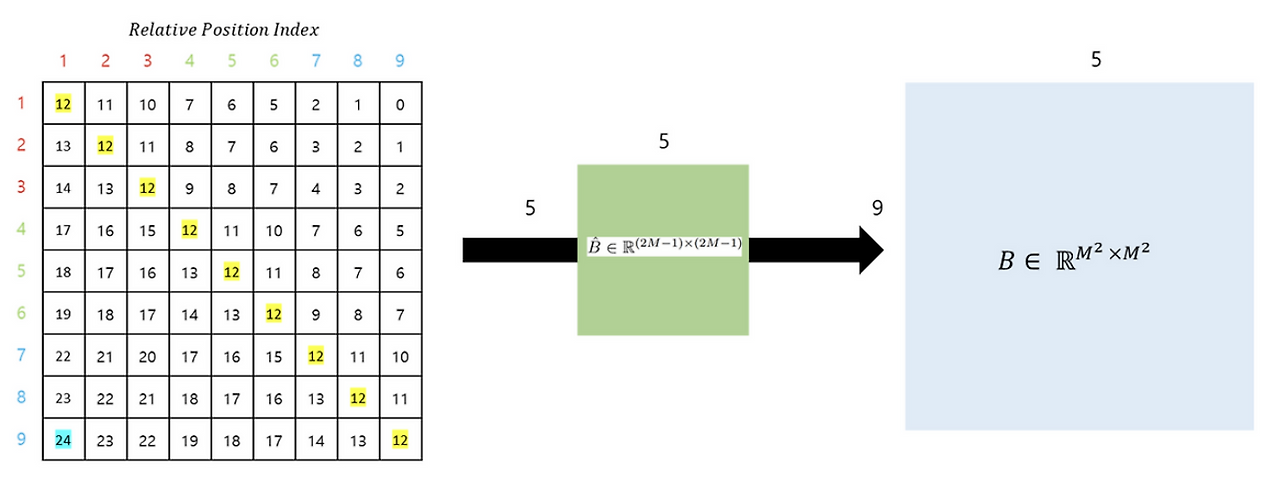
Relative Positional Encoding
Unlike traditional Vision Transformers (ViT), which use absolute positional embeddings, Swin Transformer applies:
No positional encoding at the input.
Instead, relative position bias is learned and added during attention computation.
This bias represents the relative distance between tokens inside each window.
It enables the model to maintain spatial structure without global positional references.
In conclusion, as shown in the figure above, the Relative Position Bias is generated using $\hat{B}$. Ultimately, for the matrices $Q$, $K$, and $V$, where $M^2$ represents the number of Window Patches, and the relative positions along each axis range from $[-M+1, M-1]$, it can be seen that a smaller-sized Bias matrix $\hat{B}$ is parameterized, and the values of $B$ are derived from $\hat{B}$.
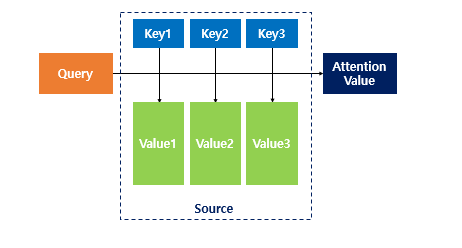
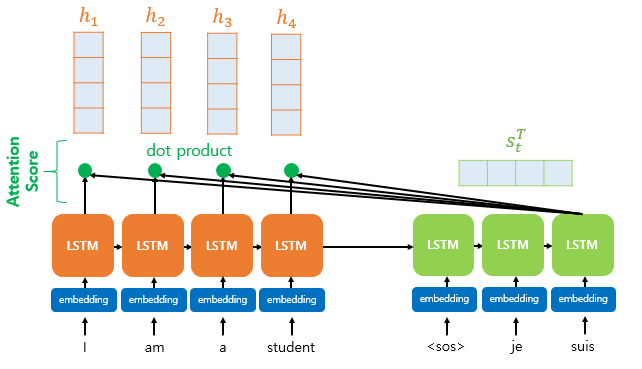
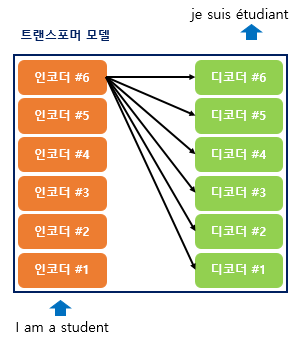
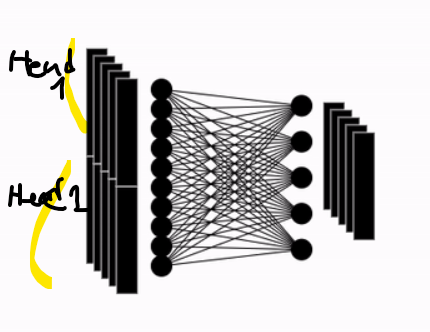
The basic idea of attention is that, at each time step during decoding, the decoder refers back to the entire input sentence encoded by the encoder. Instead of treating all parts of the input sentence equally, the model focuses more on the specific parts of the input that are most relevant to predicting the current output word.
Attention Function (HashMap Analogy)
The attention function can be thought of similarly to a Python dictionary. However, its role is to compute the similarity between a given query and all keys, then map each key to a value weighted by this similarity. The output is essentially a weighted sum of these values, where the weights reflect the relevance (similarity) to the query.
Q: Query — The hidden state of the decoder cell at time step 𝑡
K: Keys — The hidden states of all encoder cells at every time step
V: Values — The hidden states of all encoder cells at every time step
Attention Features
At each time step, the decoder refers back to all encoder hidden states, focusing more on the words that are most relevant. This approach helps address issues like vanishing gradients and the fixed-size output vector limitation of traditional RNNs.
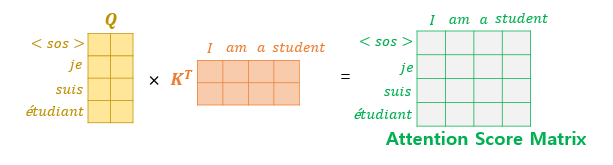
The attention mechanism computes similarity scores based on dot products. Specifically, to calculate the attention scores, the decoder’s hidden state at time step 𝑡, denoted as 𝑠𝑡, is multiplied by each encoder hidden state ℎ1, ℎ2, …,ℎ𝑁 For example, in the third decoding stage where the model predicts the next word after “je” and “suis,” it re-examines all encoder inputs to determine relevant information.
Formally, assuming the encoder and decoder hidden states share the same dimensionality, the attention scores 𝑒𝑡 can be calculated as: `et = [st⊤h1, st⊤h2, … ,st⊤hN] Here, 𝑒𝑡 is the vector of attention scores representing the relevance of each encoder hidden state to the current decoder state.
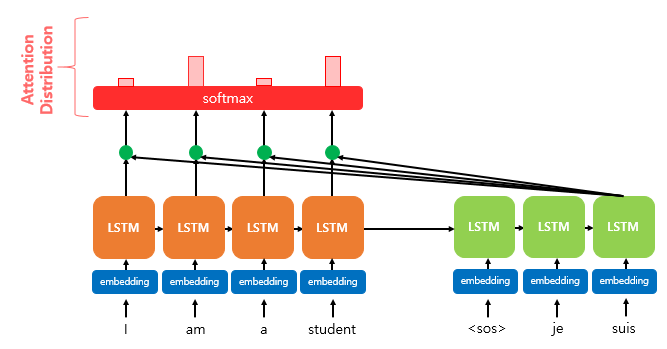
After computing the attention scores, we apply the softmax function to obtain the attention distribution, also known as the attention weights. By applying softmax to the attention scores 𝑒𝑡, we get a probability distribution 𝑎𝑡, where all values sum to 1. Each value in 𝑎𝑡 represents the weight (or importance) assigned to the corresponding encoder hidden state.
Formally: 𝑎𝑡 = softmax(𝑒𝑡) These attention weights determine how much each encoder hidden state should contribute to the current decoding step. In the diagram, the red rectangles represent the magnitude of attention weights applied to the encoder hidden states.
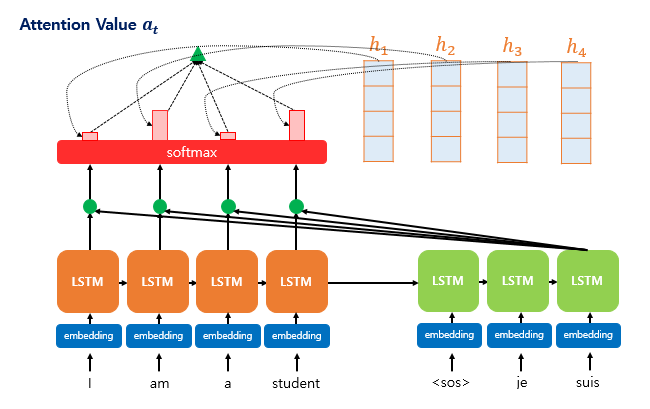
Once the attention weights 𝑎𝑡 are computed, we calculate the weighted sum of the encoder hidden states. This weighted sum is called the attention value, and it’s also commonly referred to as the context vector.
The higher the attention weight assigned to a particular hidden state, the more strongly it contributes to the final context vector—indicating a higher relevance to the current decoding step.
Formally, the context vector context 𝑡 (or attention value) is computed as: \[\text{context}_t = \sum_{i=1}^{N} a_i^t \cdot h_i\]
This vector summarizes the relevant parts of the input sequence, tailored for the current decoding time step 𝑡.
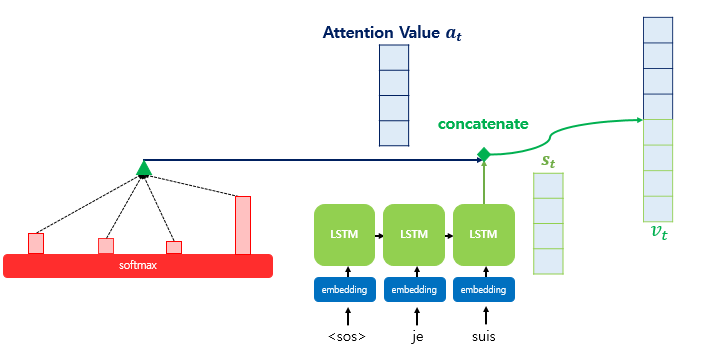
After computing the attention value (context vector), it is concatenated with the decoder’s hidden state at time step 𝑡, denoted as 𝑠𝑡.
This concatenated vector, often written as 𝑣𝑡 = [context𝑡;𝑠𝑡], combines both the information from the encoder (via attention) and the current state of the decoder. This merged vector 𝑣𝑡 is then used as input for predicting the output 𝑦𝑡, helping the model make more accurate predictions by leveraging both current decoding context and relevant encoder features.
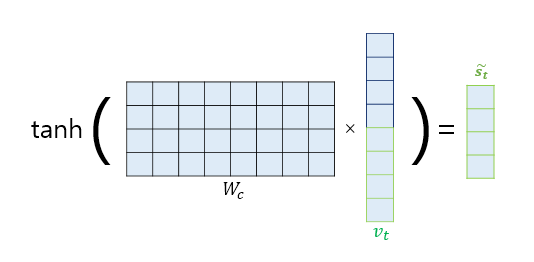
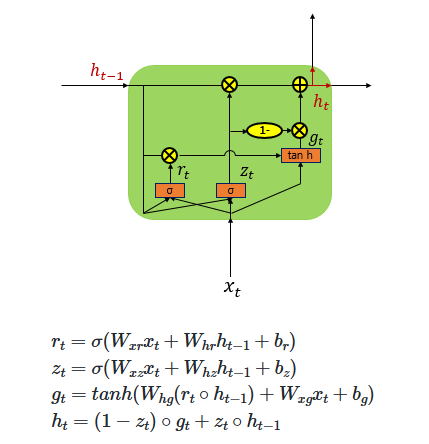
Computing ( \tilde{s}_t ), the Input to the Output Layer
Before sending ( v_t ) (the concatenation of the context vector and the decoder hidden state) directly to the output layer, it is passed through an additional neural layer for transformation.
Specifically, ( v_t ) is multiplied by a weight matrix and then passed through a hyperbolic tangent (tanh) activation function. This results in a new vector ( \tilde{s}_t ), which serves as the final input to the output layer: \[\tilde{s}_t = \tanh(W_o \cdot v_t)\]
This transformation allows the model to learn a richer representation before making the final prediction for the output word ( y_t ).
( \alpha_t = \text{softmax}(W_a s_t) ) // Only uses ( s_t ) when computing ( \alpha_t )
Luong et al. (2015)
RNN + Attention (seq2seq) Limitation
The Encoder-Decoder structure consists of two main components: the encoder, which compresses the input sequence into a fixed-length vector (often called the context vector), and the decoder, which generates the output sequence based on this vector.
However, this approach has several limitations:
Information loss during compression into a single vector
Lack of parallelism, since RNN-based encoders/decoders process sequences sequentially
High computational complexity
To address these issues, the Transformer architecture was introduced.
Transformer
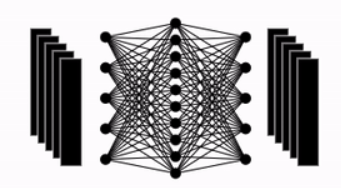
The Transformer replaces recurrence with attention mechanisms, specifically self-attention and cross-attention, to model dependencies in sequences. Just as CNNs use convolution to extract feature maps, attention computes similarity scores using dot products, followed by a weighted sum of values. This allows the model to focus on the most relevant parts of the input when processing each token.
Key features include:
The ability to differentiate between individual tokens using attention weights
The use of self-attention within both the input (encoder) and output (decoder) sequences
Support for parallel computation, greatly improving training efficiency
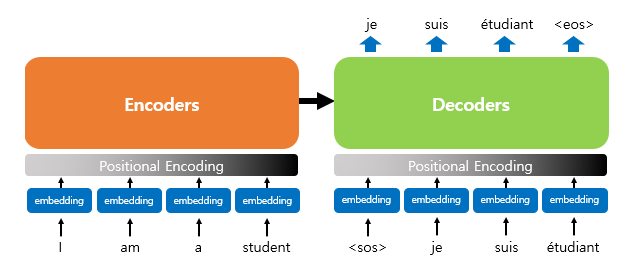
Although the Transformer does not use RNNs, it still follows the Encoder-Decoder architecture, where it takes an input sequence and generates an output sequence. The overall structure is similar to that of traditional RNN-based models.
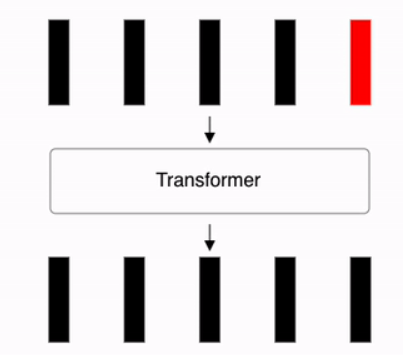
However, there is a key difference: In RNNs, the model processes the sequence step by step over time — each unit corresponds to a specific time step 𝑡. In Transformers, the model processes the entire sequence in parallel. Instead of time steps, it consists of 𝑁 repeated encoder and decoder blocks, each operating on the entire sequence simultaneously. This structural shift allows Transformers to overcome the sequential bottleneck of RNNs and achieve much better performance in terms of parallelization and long-range dependency modeling.
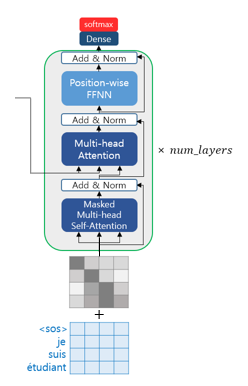
The end of the computation is as shown in the image below. The process continues from the input <sos> until <eos> is produced. Especially, since it is not divided by time steps like an RNN, positional encoding is necessary. In other words, a word’s one-hot encoding technique can be considered to be included.
Transformer Components
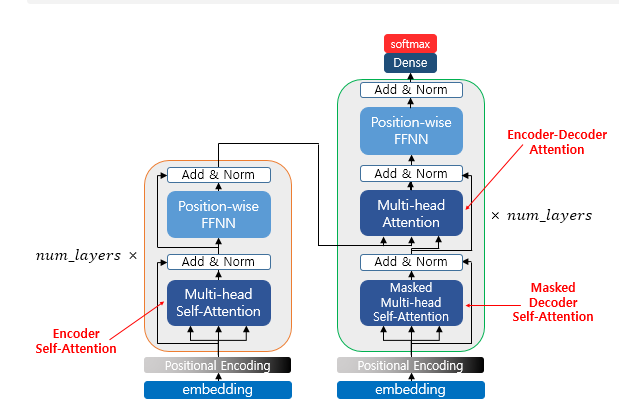
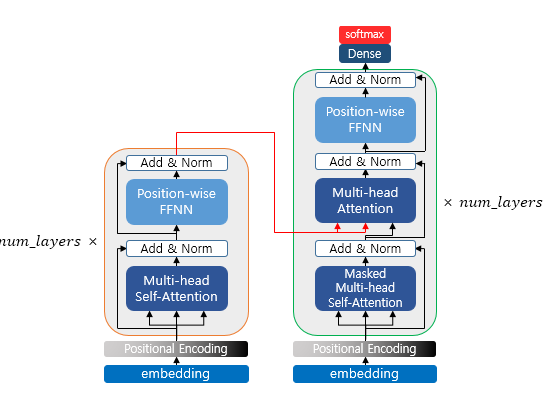
I will first define the following steps. The diagram below can be considered the overall architecture.
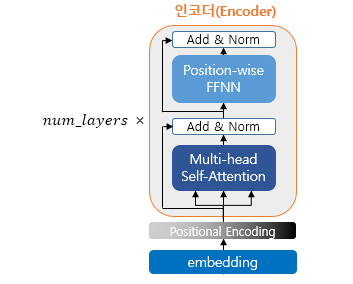
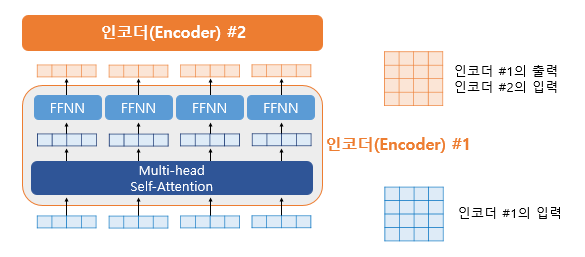
Encoder (self.attention)
The encoder is built using num_layers (6). Inside, there can be layers such as multi-head self-attention and position-wise FFNN.
In Sequence-to-Sequence models, the meaning of Q, K, and V was that Q represented the decoder hidden state at time step t.
However, in self-attention, Q, K, and V are the same. This means they represent the vectors of all words in the input sentence.
Note that instead of using the words themselves directly, their dimensionality is reduced. For example, if there are 4 words, each has a position vector, and these position vectors’ dimensions are reduced to form the dimensions of Q, K, and V.
After that, scaled dot-product attention is applied. Overall, this is performed as matrix operations (not just vector operations).
Multi-Head Attention
Among the parameters, there is a “number of heads,” which corresponds to parallel processing heads. Each head performs the following steps with Q and K: matrix multiplication → scaling → optional masking → softmax → matrix multiplication with V. Each head extracts different values, and by processing them in parallel, the values from each head are obtained.
Padding Mask
Here, the mask refers to the padding mask. Padding tokens have no actual meaning. Therefore, in the transformer, if a key corresponds to a padding token, similarity is not computed—in other words, it is excluded (which might be compared to a skip connection, but they are not the same). In this case, the padding mask has small values (close to zero) in the attention score.
Position-wise FFNN
The point-wise FFNN can be considered a sublayer that both the encoder and decoder have. Therefore, it can be viewed as performing the computations shown in the diagram below.
Another notable aspect is the use of skip connections and layer normalization (similar to the residual blocks in ResNet).
Encoder to Decoder
That is, the encoded information is passed to the decoder. This is done by feeding the values into the multi-head attention. We will take a closer look at this part on the decoder side. If you want, I can help expand or clarify further!
Decoder (Self-Attention / Look-Ahead Mask)
Like the encoder, the decoder also receives a sequence of words as input. However, to prevent the model from looking at future words beyond the current time step, an optional mask is applied during training. This masking prevents the decoder from attending to subsequent words and is called the look-ahead mask. Similar to the encoder, self-attention is performed.
In summary, the decoder can only attend to itself and the previous words, but not to future words.
The second case is when the values received from the encoder and the decoder are used together. In this layer, it is not self-attention. This means the definitions of Q, K, and V are different.
Q corresponds to the decoder matrix, while K and V correspond to the encoder matrix. Mapping this to the example above, it looks like the following.
After that, the output probabilities are generated, and during inference, the token with the highest probability is produced.
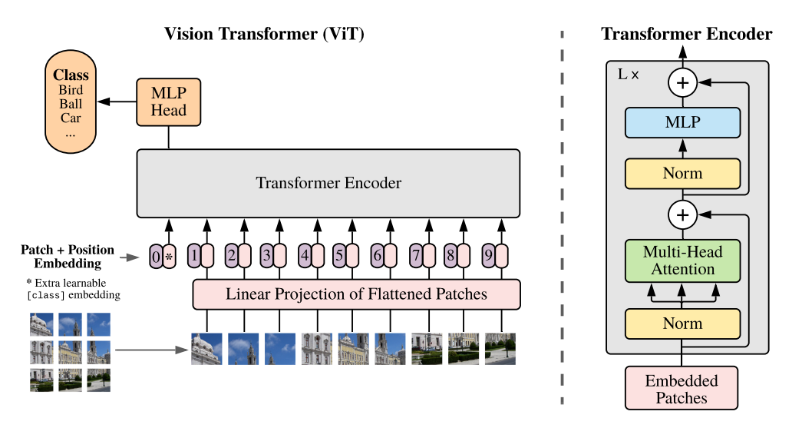
You might have seen this in previous posts. Essentially, a Transformer is a self-attention model that operates in the following way: Normalization → Multi-head Attention → Normalization → MLP.
Let’s take a look at the overall architecture diagram below.
Input Data
Since it is a Vision Transformer, image data and the corresponding label data are used for training.
수식은 아래와 같다. \[x \in \mathbb{R}^{C \times H \times W}\]
Image Patch in Vision Transformers
In the context of Vision Transformers, an Image Patch refers to the process of dividing an input image into smaller, fixed-size segments called patches. These patches are typically of size $ p \times p $ pixels and are used as input to the Transformer model, effectively treating the image as a sequence of patches, similar to how words are treated in natural language processing.
For example:
Given a 224 x 224 pixel image, if the patch size is set to 16 x 16 pixels, the image is divided into a grid of 14 x 14 patches (since $ 224 \div 16 = 14 $). Each patch is then flattened and processed as part of a sequence, which is fed into the Transformer architecture for vision tasks.
This approach allows the Transformer to leverage its sequence-processing capabilities for vision tasks, treating the grid of patches as a sequence of “tokens” akin to words in text processing.
Below is a direct translation of your input into English, formatted in Markdown, keeping the technical details and structure intact as requested.
CNNs and Vision Transformers: Image Patch Flattening CNNs have traditionally excelled in image processing through convolution operations. One of their drawbacks is the explosive increase in parameters, leading to issues like overfitting and gradient vanishing, which are addressed using regularization or dropout. In contrast, Transformers appear to rely on a specific exploitation method. In traditional Transformers, word embedding sequences are used as input. For vision tasks, this is adapted by inputting image patch sequences, enabling tasks like image label prediction. This represents a distinctly different architectural pattern. Flattening of Image Patches With patched images, a flattening process is applied to convert each patch into a vector of size $p^2 \times c$, where:
Flatten Operation: The image is divided into patches, and each patch is flattened into a vector. Patch and Input Size: For an image of size $H \times W$ pixels divided into $N$ patches (where $N = \frac{HW}{p^2}$), each patch is processed.
Flattened Vector: Each patch $z_p$ is represented as a vector in $\mathbb{R}^{N \times (p^2 \cdot c)}$, where:
$p$: Size of one side of the patch.
$c$: Number of color channels (e.g., 3 for RGB).
$N = \frac{HW}{p^2}$: Total number of patches, derived from the image dimensions $H$ (height) and $W$ (width) divided by the patch area $ p^2 $.
This reflects the process of converting image patches into a sequence of flattened vectors suitable for input into a Transformer model.
Patch Embeddings
After dividing the image into patches, embeddings are created from each patch. The split image patches undergo a linear transformation to initiate the encoding process. The resulting vectors are referred to as Patch Embedding Vectors, and they are characterized by a fixed length $ d $.
Each patch of size $ n \times n $ is reshaped into a single column vector of size $n^2 \times 1$.
Example: A patch of $16 \times 16$ pixels is flattened into a $256 \times 1$ vector.
Linear Projection
Each patch, after flattening, concatenates all pixel channels. It then undergoes a linear projection to the desired input dimension. This might seem confusing, but the key idea is:
After flattening, each patch becomes a single column vector (e.g., $256 \times 1$). The linear projection aims to reduce or transform the dimensions, typically for compatibility with the model’s input requirements. Example: If a $256 \times 1$ flattened patch is input into a linear layer with 512 nodes, a linear computation (multiplication by weights plus addition of bias) transforms it into a $512 \times 1$ output vector.
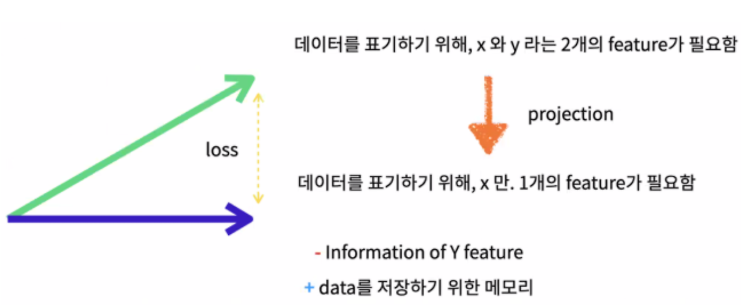
Projection of Two Features into One
By projecting two features into a single feature through linear projection, the process allows the use of only one feature. Ultimately, this maps pixel values into a format the model can understand. This involves transforming high-dimensional pixel data into a vector (or point), enabling a more concise representation that captures essential information.
Latent Vector Definition
The latent vector represents the encoded representation of the image patches after processing. It is defined as:
A sequence of $N$ patch embeddings, where each embedding is scaled by a factor $\alpha$. The resulting vector is denoted as $[\alpha^1 E_1, \alpha^2 E_2, \dots, \alpha^N E_N]$.
$E \in \mathbb{R}^{(p^2 \cdot c) \times D}$: The embedding matrix, with $p^2 \cdot c$ representing the flattened patch size (where $p$ is the patch dimension and $c$ is the number of channels) and $D$ is the desired embedding dimension.
Through this process, all patches can be embedded into vectors. The result is an $ N \times D $ array, where:
$N$: The number of patches.
$D$: The embedding size for each patch.
This $N \times D$ array represents the embedded patch sequence ready for input into the Transformer model.
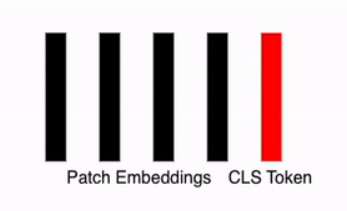
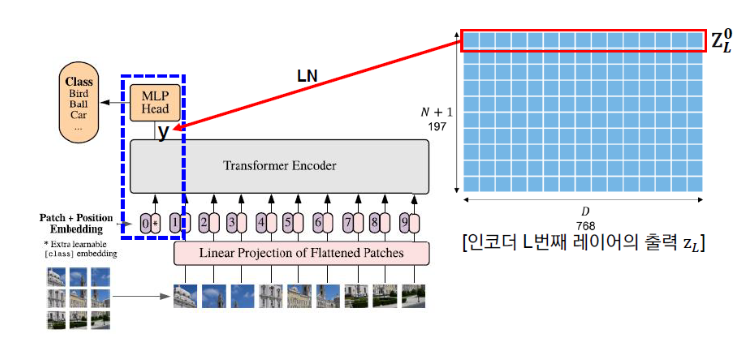
Appending a Class (Classification) Token
To effectively train the model, a vector called the CLS Token (Classification Token) is added to the patch embeddings. This vector: Acts as a learnable parameter within the neural network.
Is randomly initialized.
Is a single token added uniformly to all data instances.
After this step, the total number of embeddings becomes $n + 1$ (where $n$ is the number of patch embeddings plus the CLS token). Combined with the embedding size $D$, this results in a $(n+1) \times D$ array, which serves as the representation vector for further processing.
Initial Embedding with CLS Token
The initial embedding $ z_0 $ is formed by appending the CLS Token to the patch embeddings. It is defined as:
$\alpha_{cls} $: The CLS Token, a learnable vector.
$\alpha^1_p E_1, \alpha^2_p E_2, \dots, \alpha^N_p E_N$: The scaled embeddings of $N$ patches.
$(N+1) \times D$: The resulting dimension, where $N$ is the number of patches and $D$ is the embedding size.
This $z_0$ serves as the input representation vector for the Transformer model.
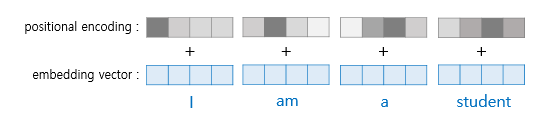
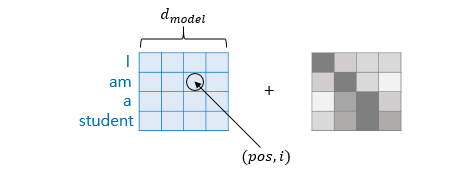
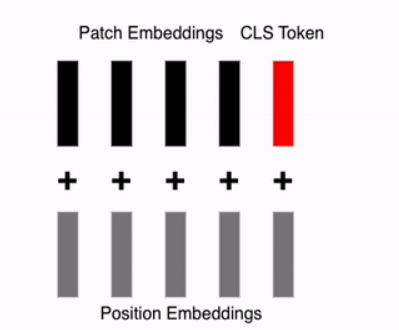
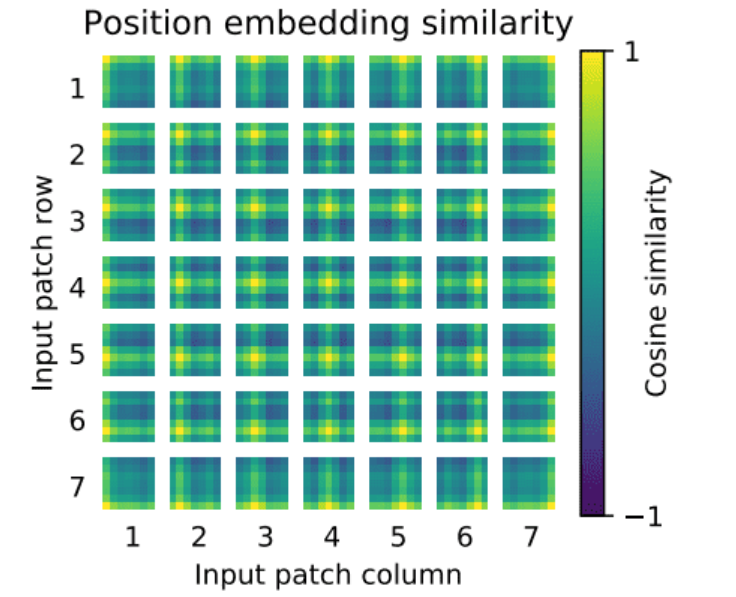
Adding Positional Embedding Vectors
In the original Transformer, positional information for words was added to create 2D data. For images, where “which position?” becomes relevant, a process is added to encode positional information for each patch, reflecting its spatial location. This positional encoding is directly added to each embedding vector, including the CLS Token.
Process
Patch Embeddings: Represent the content of each patch.
Positional Embeddings: Encode the spatial order or position of each patch.
Combination: The positional embeddings are added to the patch embeddings and the CLS token to form the final input.
$E_{pos} \in \mathbb{R}^{(N+1) \times D}$: The positional embedding matrix, with the same shape as the patch and CLS token sequence. This $z_0$ represents the final input to the Transformer, incorporating both the content (via patch embeddings and CLS token) and positional information.
Similar to the previous discussion, the positional encoding method used here involves sin and cos functions, as seen in prior posts. This approach encodes the positional information of each patch, allowing the model to understand the spatial arrangement of the image patches.
The positional encoding $ PE(pos, 2i) $ and $ PE(pos, 2i+1) $ are defined using sine and cosine functions to encode the position of each patch. The formulas are: Mathematical Formulation \(PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right)\) \(PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right)\)
$pos$: The position of the patch.
$i$: The dimension index.
$d_{model}$: The dimensionality of the model.
Encoder
Encoder Input
After the previous steps, you now have an array of size $(n + 1) \times d$, where $n$ is the number of patches and $ d $ is the embedding dimension. The next step is to apply self-attention, which allows the model to weigh the importance of different patches (including the CLS token) in relation to each other.
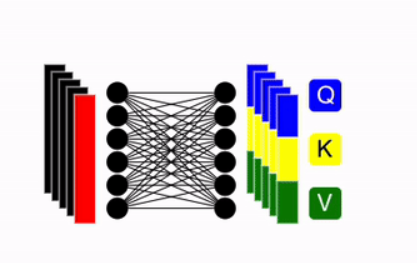
Multi-Head Self Attention
Create QKV (Query, Key Value)
The embedding vector generated from the previous steps is linearly transformed into multiple large vectors, which are subdivided into three components: Q (Query), K (Key), and V (Value). These vectors are derived from the $(n + 1) \times d$ array, where $n + 1$ represents the number of patches plus the CLS token, and each component retains the same $n + 1$ length.
The equations are following: \[q = z \cdot w_q,\quad k = z \cdot w_k,\quad v = z \cdot w_v \quad \text{where} \quad w_q, w_k, w_v \in \mathbb{R}^{D \times D_h}\]
usually, $D_h$ set to $D/k$, (k is the number of attention heads — enabling parallel processing.)
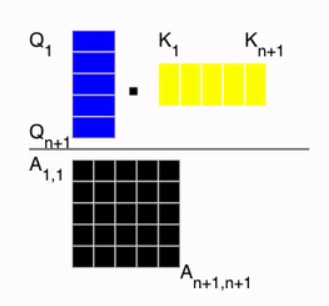
Self.Attention
Now, we need to compute the attention score. As shown in the image below, the similarity is calculated by taking the dot product between the query and the key. Then, softmax is applied so that the sum of each row in matrix ( A ) becomes 1.
The equations are following: \[SA(z) = A \cdot v \in \mathbb{R}^{N \times D_h}, \quad \text{where} \quad A = \text{softmax} \left( \frac{q \cdot k^T}{\sqrt{D_h}} \right) \in \mathbb{R}^{N \times N}\]
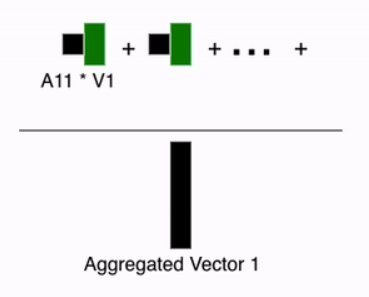
After that, a weighted sum is computed over ( v ) using the attention weights.
Here’s the process: to obtain the aggregated contextual information for each element, we perform the computation using the first row of the attention matrix. At this point, we use the weights applied to ( V ) to generate the aggregated vector for the first image embedding. This operation is then applied to all patches.
Multi-Head Attention
The above process is ultimately repeated multiple times. \[MSA(z) = [SA_1(z); SA_2(z); \cdots; SA_k(z)] U_{\text{msa}} \quad \text{where} \quad U_{\text{msa}} \in \mathbb{R}^{(k \cdot D_h) \times D}\]
MLP (Additional Details)
Pretraining: Uses one hidden layer.
Finetuning: Uses a single linear layer.
In total, two linear layers are used, along with the GELU (Gaussian Error Linear Unit) activation function.
Last Attention Layer Setup
After stacking multiple attention heads, the result is mapped to a vector of dimension ( D ), which matches the patch embedding size.
Attention Layer Result
Residual Connection
Simply adds the input from the previous layer to the current layer.
Feed Forward Network
The output from the previous steps is passed into a feed-forward network.
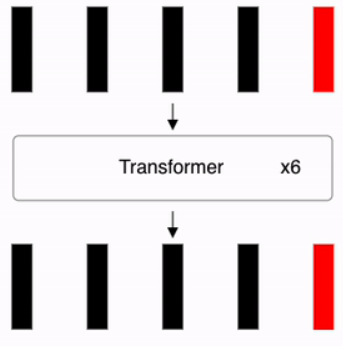
Repeating Process
Repeat the above process L times. As shown in the second figure below, after L repetitions, the final classification is performed by passing the first vector y of the Encoder’s final output through an MLP Head consisting of a single hidden layer (dimension D × C).
Transformer Layer Processing
The output $z_l$ at layer $l$ is computed by applying a Multi-Layer Perceptron (MLP) and Layer Normalization (LN) to the input $z_l’$, combined with the residual connection $z_l$. The process is defined as:
$\gamma, \beta$: Learnable scaling and shift parameters.
$\mu_i$: Mean of the input.
$\sigma_i^2$: Variance of the input.
$\epsilon$: Small constant for numerical stability.
This iterative process refines the embeddings across $L$ layers.
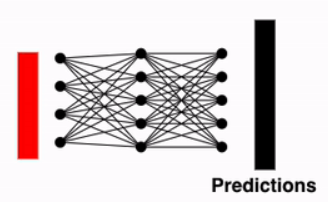
Identifying Classification Token Output and Predicting Classification Probabilities
The final step involves examining the output of the CLS Token (Classification Token). This vector serves as the last step in the Vision Transformer. In the final stage, it is passed through a Fully Connected Layer to compute Classification Probabilities, enabling the prediction of the image class.
Inductive Bias
The term Inductive Bias frequently appears in this context. For CNNs, the use of Convolution Operations, which are specific to images, introduces an inductive bias. This bias includes:
Locality: Focusing on local regions of the image.
Two-Dimensional Neighborhood Structure: Capturing spatial relationships in a 2D grid.
Translation Equivariance: Ensuring the model responds consistently to translated inputs.
In contrast, Vision Transformers (ViTs) rely on MLP Layers to implicitly address Locality and Translation Equivariance. ViTs learn these properties through the Input Image Patches and refine them via Positional Embeddings (e.g., through fine-tuning).
사실상 Game Engine 을 만들고 싶은건 아니다. Game Engine 을 사용한 어떠한 Product 를 만들고 싶었고, 그 Platform 이 Unreal Engine 이 됬든, Unity 가 됬든 사용하면 된다. 하지만 이미 상용화? 된 엔진들의 확실한 장점은 있지만, 그렇다고 해도, 너무 많은 방대한 정보를 이해하기에는 쉽지 않다. 예를 들어서, DirectX11 에서는 확실히 Low Level API 라고 하지만, 거의 High Level API 이다. 특히나 드라이버(인력사무소)가 거의 많은 작업들을 처리 해주었다. 그에 반대 되서, DirectX12 는 대부분의 작업을 따로 처리해줘야한다 (RootSignature, PipelineState, etc) 그리고 병렬 지원에 대해서도 충분히 이야기할수 있다. CommandList 를 병렬 처리가 가능하다고 한다. (이부분은 실제로 해보진 않았다.)
특히나, Commit 을 하기전에 Stream 방식인지, CommandList 에 일할것과, 일의 양을 명시해서 CommandQueue 에다가 넣어준다. 그리고 OMSetRenderTargets, IASetVertexBuffers 등으로 DX11 에서는 알아서 자동 상태 전이가 되지만, DX12 에서는 D3D12_RESOURCE_BARRIER 를 통해서 상태를 명시적으로 지정해주어야 할 필요가 있다. 이것 말고 등등 오늘은 DX12 의 어려움 또는 DX11 와 비교를 말을 할려는 목적은 아니다. 오늘은 나의 개발 로그를 공유하려고한다.
Motivation
예전부터 내가 직접 만들어보고 싶고, 표현해보고 싶었던게 있었고, 그걸 표현하기위해서, Game Engine 관련되서 Youtube 를 찾아보게 되다가 우연치 않게, Cherno 라는 Youtuber 를 보았다. 이 분은 EA 에서 일을 하다가 이제는 직접적으로 Game Engine Hazel 을 만들고 있다. 꼭 그리고 다른 Contents 도 상대적으로 퀄리티가 있다. 그리고 Walnut 에 보면 아주 좋은 Vulkan 과 Imgui 를 묶어놓은 Template Engine 이 있다. 꼭 추천한다. 그리고 개발하면서 다른 Resource 도 올려놓겠다.
Abstraction Layer
일단 나는 Multiplatform 을 Target 으로 Desktop Application 으로 정했다. 즉 Rendering 부분을 DX12 Backend 와 Vulkan Backend 로 나누어서, 추상화 단계를 거쳤다.
지금의 Project 의 구조를 설명하겠다. (전체적으로 HAL=Hardware Abstraction Layer 를 구상중)이며, 게임 엔진 내부에서 Platform 에 구애 받지 않게 설계 기준을 잡았다. 물론 추상화 계층은 삼각형 그리기 기준으로 일단 추상화를 작업을 진행하였다. 전체적으로 Resource 는 한번 추상화 작업을하고, IRenderBackend 로 부터 DirectX12 으로 할건지, Vulkan 으로 할건지 정의 하였다. 아직 작업할 일은 많지만, 한번에 하지 않으려고 진행중이다.
첫번째로, ImGUI 를 같이 사용하려면, ImGUI 용 descriptor heap 을 따로 만들어줘야한다. Example-DX12 Hook 여기에 보면, 아래 처럼 descriptor 를 만드는걸 확인 할수 있다. 그리고 내 DX12Backend 쪽에서도 이러한 방식으로 진행하고 있다.
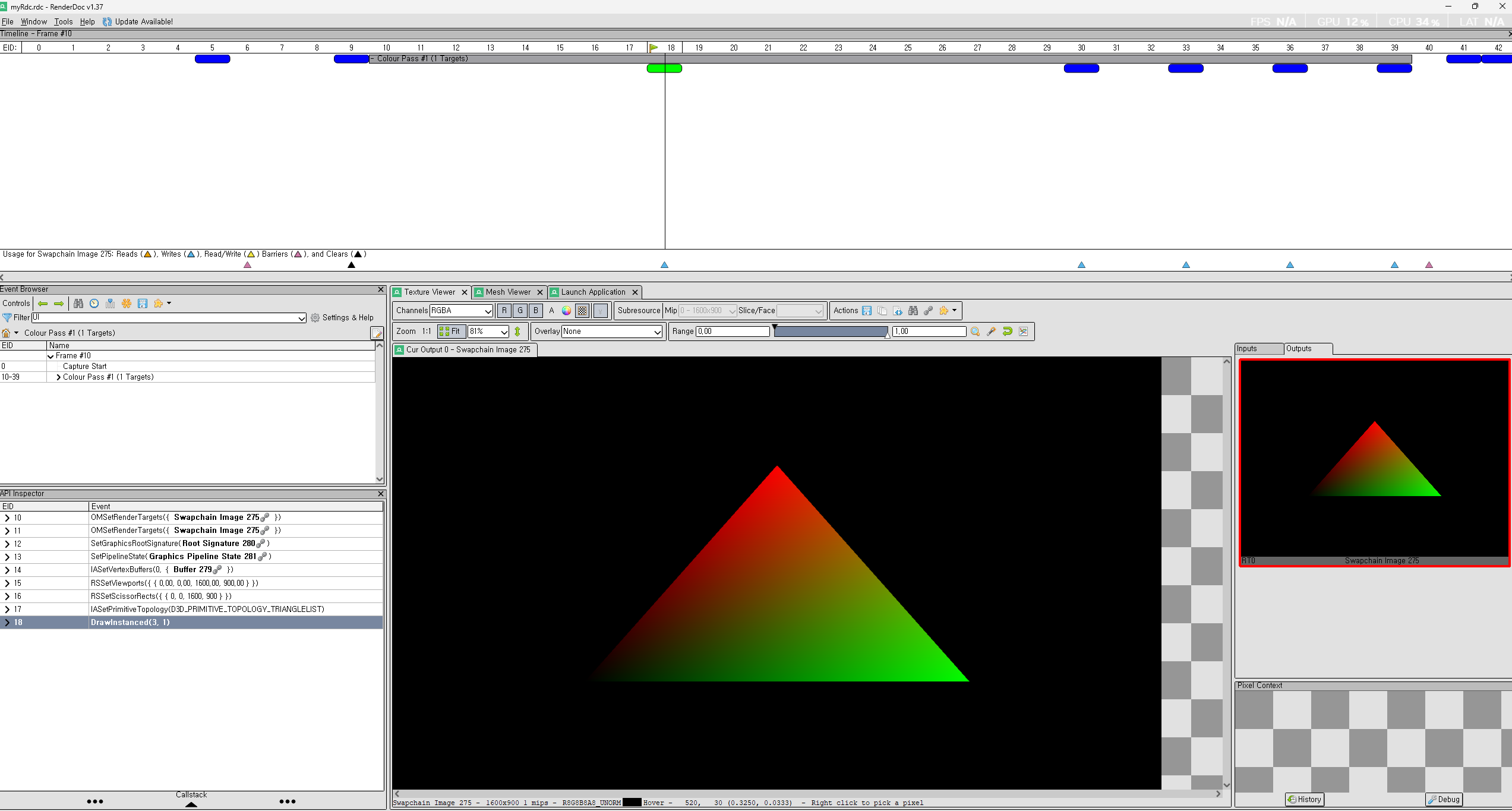
삼각형을 그리기만하는데, 삼각형이 그려지질 않는다. 그래서 이걸 RenderDoc 으로 체크를 해보겠다.
삼각형은 완벽하게 그려지고 있다. 하지만 그 다음 Pass 에 보면 없어진다.
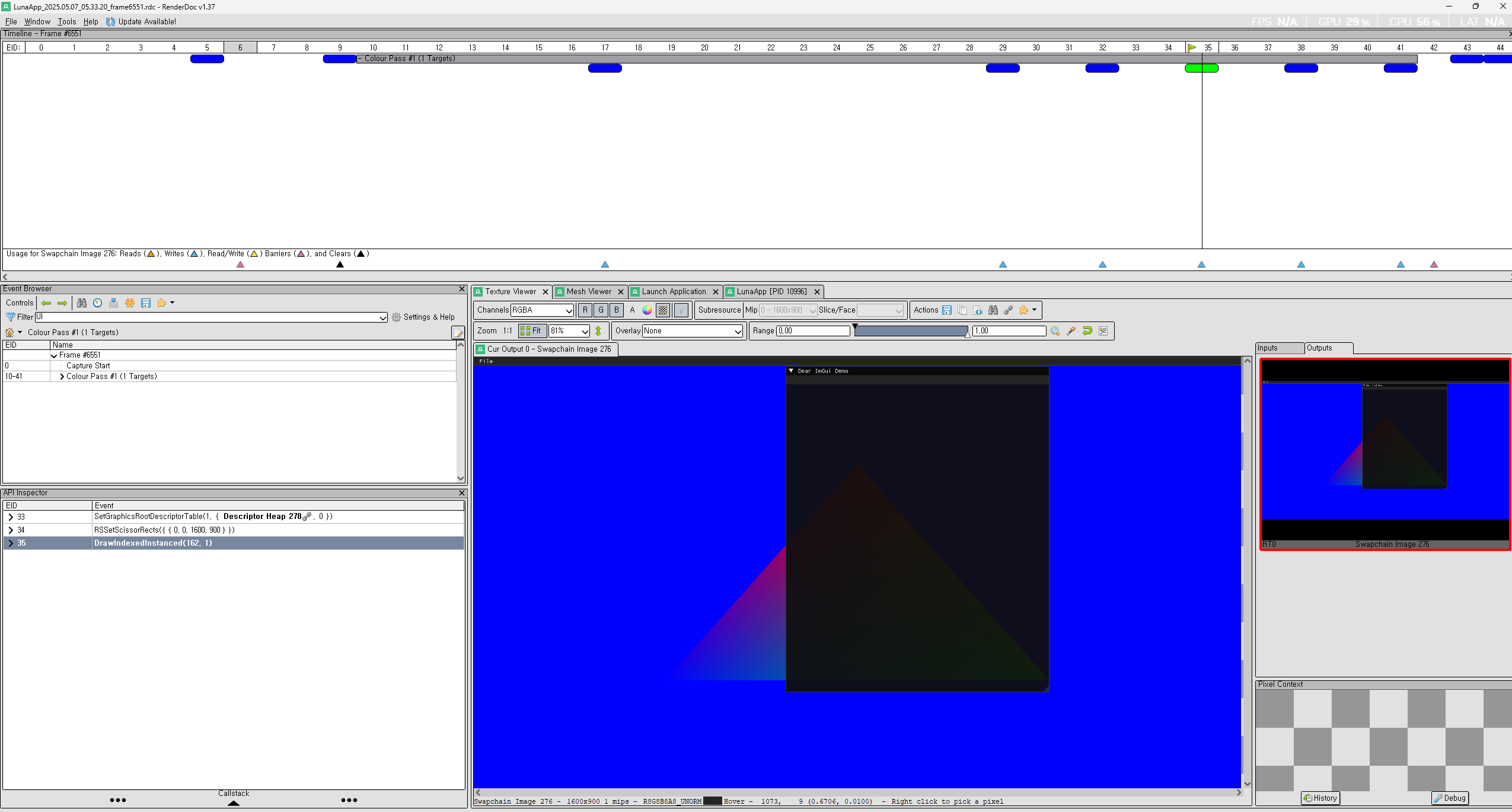
이거에 대해서 찾아보다가, RenderTarget 에 둘다 그릴려구 해서 그렇고, 마지막에 Update 하는 부분이 ImGUI 에서 Docking 또는 Viewports Enable 을 했을시에 문제가 있다고 한다. 이럴떄, 기본적으로, ImGUI 에서는 GPU Rendering 상으로 기능을 독릭접인 자원을 활용하기 위해서 따로 만든다고 말을 하였다. 기본적으로 Viewports 를 Enable 했을시에, 새로운 Viewport 의 배경색은 Gray 색깔이라고 한다. 그래서 마지막에 Rendering 을 했을시에, Gray 로 덮어버린다. 즉 ImGUI 는 Texture 기반의 UI 요소를 그린다. (즉, ImGUI 의 내부 관리가 아닌 OS 창으로 Rendering 이 된다.)
둘다 방법론은 같다. 그래서 아래와 같이 결과가 나왔다. 결국에는 해야하는 일은 하나의 RenderTarget 에 병합? (Aggregation) 이 맞는것 같다. 그리고 중요한건 RenderTarget 이 정확하게 ImGUI 와 삼각형 그리는게 맞는지 확인이 필요하다. 아래는 Aggregation 한 결과 이다.
Dependencies
모든 Dependency 는 PCH 에서 참조하고 있다. 참고로 vcpkg 는 premake 에서 아직 disable 하는걸 찾지 못했다. src/vendor 안에 모든 dependency 가 있다.
Rendering API Related
d3d12ma -> Direct3D Memory Allocation Library
dxheaders -> DirectX related headers
dxc -> HLSL compiler
volk -> Vulkan Loader
vulkan -> you need to download sdk from vulkan webpage
Series data refers to data where the state at one point in time is dependent on the states before (or after) it. Examples include input data for sentiment analysis, music analysis, or even large language models (LLMs). These tasks all rely on sequences of information—also known as time series data.
What is RNN
RNN, or Recurrent Neural Network, refers to a type of neural network where data is processed sequentially, one step at a time. This sequential nature allows RNNs to handle inputs such as words in a sentence, musical notes, or time-series sensor data.
The core building block of an RNN is the cell—a unit inside the hidden layer that performs activation and maintains memory. These are often referred to as memory cells, because they try to “remember” previous information in the sequence.
At each time step, the memory cell receives two inputs:
The current input (e.g., the current word or note)
The hidden state from the previous time step
This structure enables recursive reuse of hidden states across time, making the network capable of learning temporal dependencies.
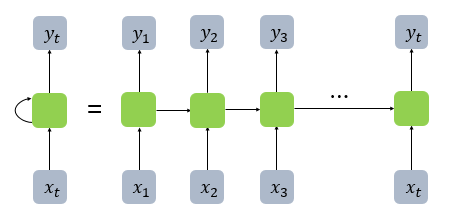
One of the key components of RNNs is the hidden state. Each memory cell carries a hidden state, and at every time step, this hidden state is updated using both the current input and the previous hidden state. This allows the network to “remember” past context as it processes the sequence step-by-step.
When the RNN is unrolled in time, it forms a chain-like structure, where each cell is connected to the next, passing along the hidden state as shown in the diagram.
In RNNs, each hidden state at time t depends on the hidden state from the previous time step (t-1). This recursive structure allows the network to “recall” past information over time.
However, this also leads to a major issue:
As information is passed along through many time steps, older data tends to be lost. The longer the sequence, the harder it becomes for the model to retain information from earlier time steps.
In addition, as the depth of the unrolled RNN increases, the model suffers from the vanishing gradient problem during backpropagation—where gradients become too small to update earlier layers effectively.
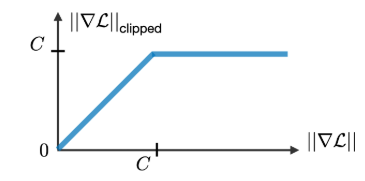
This makes it extremely difficult to learn long-term dependencies. One Common Solution to this problem is gradient clipping As shown in the diagram, a constant C is defined as a threshold. If the gradient exceeds this value, it is scaled back to prevent it from exploding or vanishing entirely.
This technique helps stabilize training, especially in deep RNNs or long sequence tasks.
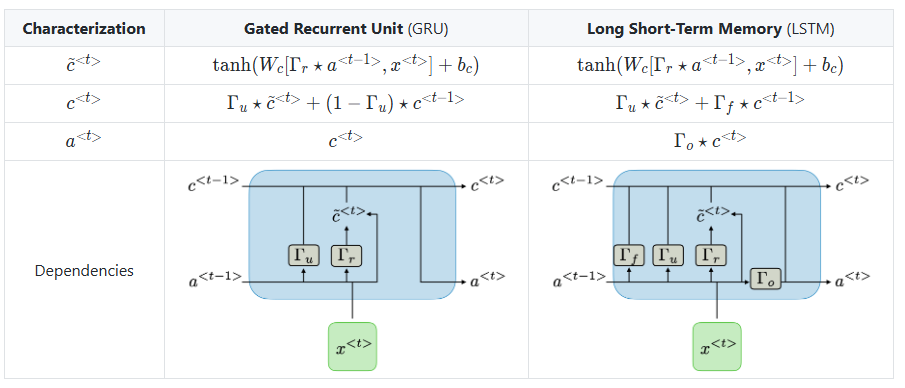
LSTM & GRU
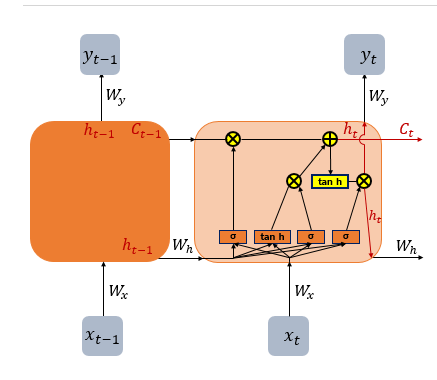
To address the issue of losing information from earlier time steps, a specialized architecture was introduced: LSTM (Long Short-Term Memory).
LSTM is designed to capture both short-term and long-term dependencies in sequential data, allowing the model to selectively retain or forget information over time.
Although the above equations may look quite complex, they essentially involve multiple gates, each performing a specific role. Mathematically, the representation of these gates can be expressed as shown in the image below.
If we break down these equations further and represent them in a simplified diagram, the image below might help make the concept easier to understand.
As mentioned earlier, each gate has a specific role. Let’s examine them one by one from left to right:
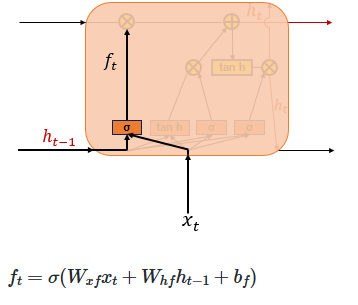
1. Forget Gate (Decides Whether to Erase the Cell State or Not)
The Forget Gate is responsible for deleting unnecessary information. At the current time step 𝑡, the input 𝑥𝑡 and the previous hidden state ℎ𝑡 −1 are passed through a sigmoid function, producing values between 0 and 1. Values closer to 0 indicate that much of the information is discarded, while values closer to 1 mean the information is retained. This gating mechanism controls how the cell state is updated accordingly.
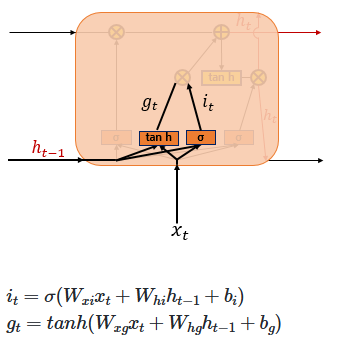
2. Input Gate
The Input Gate is used to process the new information to be added to the cell state. As shown on the right, the current input 𝑥𝑡 is multiplied by the weight matrix 𝑊𝑥𝑖, and the previous hidden state ℎ𝑡−1 is multiplied by 𝑊ℎ𝑖. Their sum is then passed through a sigmoid function. At the same time, the current input 𝑥𝑡 multiplied by 𝑊𝑥𝑔 and the previous hidden state ℎ𝑡−1 multiplied by 𝑊ℎ𝑔 are summed and passed through a hyperbolic tangent (tanh) function. The result of this operation is denoted as 𝑔𝑡
In other words, the combination of the sigmoid output (ranging from 0 to 1) and the tanh output (ranging from -1 to 1) determines how much new information is selected to update the cell state.
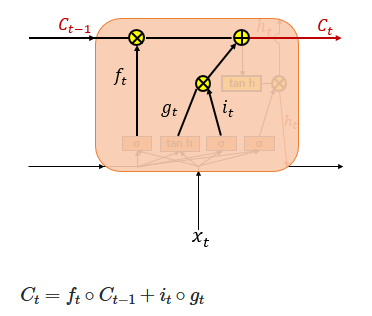
3. Cell Gate ***
In a standard RNN, only the hidden state is passed along to the next time step. However, in an LSTM, both the hidden state and the cell state are passed forward. The Forget Gate selectively removes some information from the cell state, while the element-wise product of the input gate activation 𝑖𝑡 and the candidate values 𝑔𝑡 determines how much new information is added.
These two components—the retained memory and the newly selected information—are then combined (summed) to update the current cell state 𝐶𝑡 This updated cell state is passed on to the next time step 𝑡+1. If the forget gate output 𝑓𝑡 is zero, the previous cell state 𝐶𝑡−1 is effectively reset to zero, meaning the cell only retains the newly selected information.
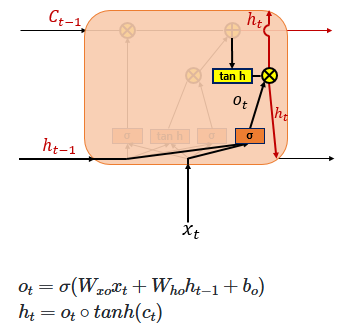
4. Output Gate & Hidden State
Finally, the Output Gate computes the output at the current time step 𝑡. It takes the current input 𝑥𝑡 and the hidden state, passes them through a sigmoid function to produce the output gate activation 𝑜𝑡. Meanwhile, the current cell state 𝐶𝑡 is passed through a hyperbolic tangent (tanh) function, producing values between −1 and 1. The element-wise product of these two values filters the cell state output, resulting in the new hidden state, which is then passed on to the next time step.
As shown in the diagram, the LSTM architecture divides these operations into multiple gates. In contrast, the GRU (Gated Recurrent Unit) simplifies this by combining some of these functions into just two gates: the Update Gate and the Reset Gate. This reduction results in a simpler structure while still effectively updating the hidden state over time, making the GRU a streamlined variant of the LSTM.
From Deep Learning Aspirations to Systems Development: My Unexpected Path into AI
During grad school, I studied Deep Learning, thinking it was a promising field worth diving into. I was genuinely excited about neural networks and how they were changing the landscape of tech.
But after graduation, I found myself doing something completely different—systems development. It felt disconnected from AI at first, and honestly, a bit frustrating. Still, I took it as a good opportunity and kept going. Surprisingly, that path led me back to AI—just from a different angle. I ended up working on systems that supported Computer Vision features. I wasn’t building models, but I was helping them run efficiently in real environments.
Why CNN?
At first, I tried training image data using a simple Multi-Layer Perceptron (MLP). To do that, I had to flatten the 2D image into a 1D vector. While this made it technically possible to train, it came at a cost—the model lost all the local and topological information in the image. It couldn’t understand where features were located, only what values existed. This made learning abstract concepts in images inefficient and slow.
To solve this, I turned to Convolutional Neural Networks (CNNs), which preserve spatial information using the concept of a receptive field—like how a lifeguard watches over a specific area of a pool, each convolutional filter focuses on a local region of the image.
Preliminary
In CNNs, we use small filters (or kernels) that slide over the image. Each kernel has weights (e.g., a 3×3 filter) and performs convolution operations followed by a bias addition and an activation function (like ReLU or Sigmoid). This produces a feature map that captures localized patterns in the image.
For example, filters like the Sobel operator are hand-designed to detect edges, but in CNNs, these filters are learned automatically during training. As a result, CNNs can effectively capture local features and build up abstract representations layer by layer.
By using convolutional layers instead of fully connected layers, the model not only gains efficiency but also becomes much better at recognizing patterns in images.
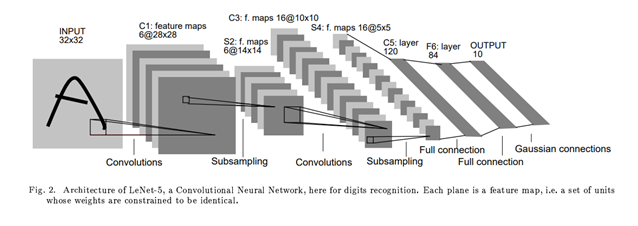
1. LeNet - Gradient Based Learning Applied to Document Recognition
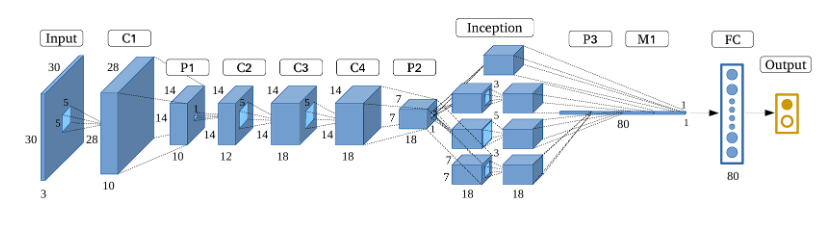
One of the earliest and most influential CNN-based architectures was LeNet, developed by Yann LeCun. It was originally designed for handwritten digit recognition (e.g., MNIST) and laid the groundwork for modern convolutional networks.
The input to LeNet is a 32×32×1 grayscale image. The first convolutional layer applies 6 filters of size n×n (typically 5×5), resulting in a feature map of size 28×28×6. This means each of the 6 filters scans the input image and extracts different local features.
After convolution, a subsampling (or downsampling) layer is applied—usually a type of average pooling—which reduces the spatial resolution. This pattern of Convolution → Subsampling repeats, gradually extracting higher-level features while reducing dimensionality.
Finally, the network flattens the feature maps and passes them through one or more fully connected layers, similar to an MLP, to perform classification.
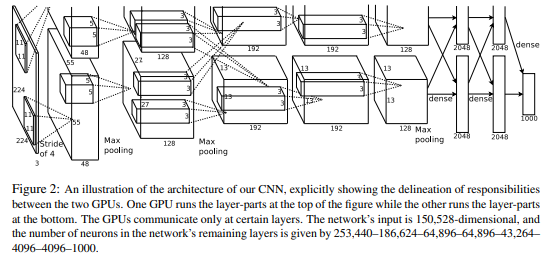
2. AlexNet - ImageNet Classification with Deep Convolutional Neural Network
While traditional face detection algorithms like Haar Cascades could recognize faces fairly well—especially with properly preprocessed input—AlexNet took things to a whole new level. Designed to handle 224×224 RGB images, AlexNet leveraged the power of GPUs for parallel computation, which allowed it to scale deeper and wider than previous models.
One interesting feature of AlexNet was its split architecture: the network was divided into two parallel streams to take advantage of multi-GPU setups.
AlexNet also introduced several key innovations that became standard in deep learning:
ReLU Activation: Instead of using sigmoid or tanh, AlexNet used the ReLU function f(x) = max(0, x) for faster convergence and to mitigate the vanishing gradient problem.
Dropout: To combat overfitting, AlexNet randomly dropped units during training, forcing the network to learn redundant representations.
Overlapping Pooling: Unlike previous networks that used non-overlapping pooling (e.g., pooling window size = stride), AlexNet used 3×3 pooling windows with stride 2, allowing windows to overlap. This reduced the output size and helped capture more spatial detail, improving translational invariance.
Local Response Normalization (LRN): Since ReLU can produce very large activations, LRN was introduced to normalize the responses across adjacent neurons at the same spatial location. This helped prevent a few highly activated neurons from dominating.
Softmax: At the output, a softmax layer was used to convert logits into probabilities, amplifying confident predictions and suppressing weaker ones.
AlexNet’s success in the 2012 ImageNet competition marked a turning point for deep learning, showing that with enough data, compute, and smart design choices, neural networks could outperform traditional hand-engineered features by a large margin.
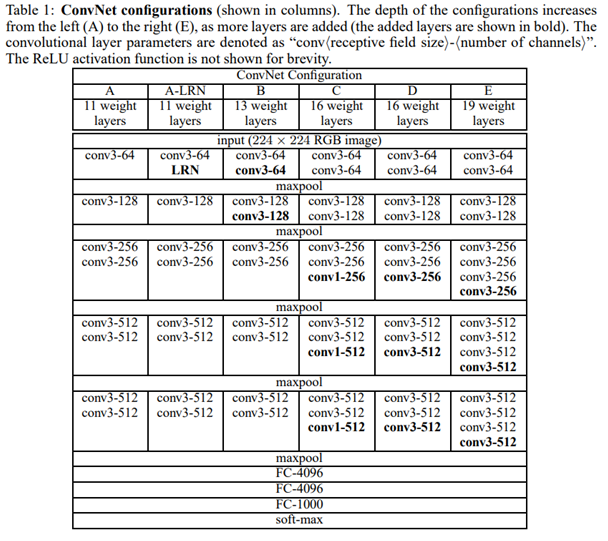
3. VGGNet - Very Deep Convolutional Networks for Large-Scale Image Recognition
VGGNet built on the success of AlexNet, using similar input dimensions (e.g., 224×224×3), but introduced a key design shift: replacing larger filters (like 5×5) with multiple 3×3 convolutions stacked in sequence.
This approach brought several advantages:
Deeper architectures (16 or 19 layers) could be created without excessively increasing the number of parameters.
Multiple 3×3 filters in a row have the same receptive field as a larger filter (e.g., two 3×3 filters ≈ one 5×5), but with fewer parameters and lower computational cost.
As a result, VGGNet significantly improved performance while maintaining a clean, uniform architecture. Because of its regular structure and strong performance, VGGNet became a popular backbone network for tasks like semantic segmentation and object detection.
However, deeper networks introduced a new problem: during backpropagation, gradients could vanish as they moved backward through many layers, especially toward the input. This vanishing gradient problem made training very deep models difficult, eventually motivating the development of architectures like ResNet, which addressed this with residual connections.
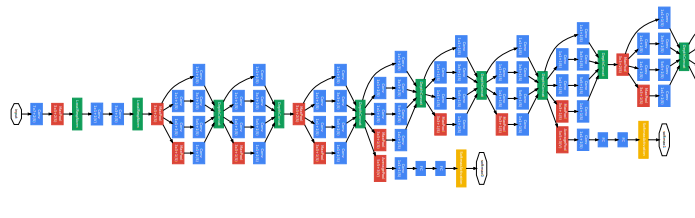
4. GooLeNet - Going Deeper with Convolution
If VGGNet made networks deeper by stacking layers vertically, GoogLeNet (a.k.a. Inception v1) took a different approach—it went deeper in both width and depth (it goes deeper both vertically and horizontally).
GoogLeNet introduced the concept of the Inception Module, which allowed the network to process spatial information at multiple scales simultaneously. As the name suggests, this architecture digs deeper and deeper into the network structure.
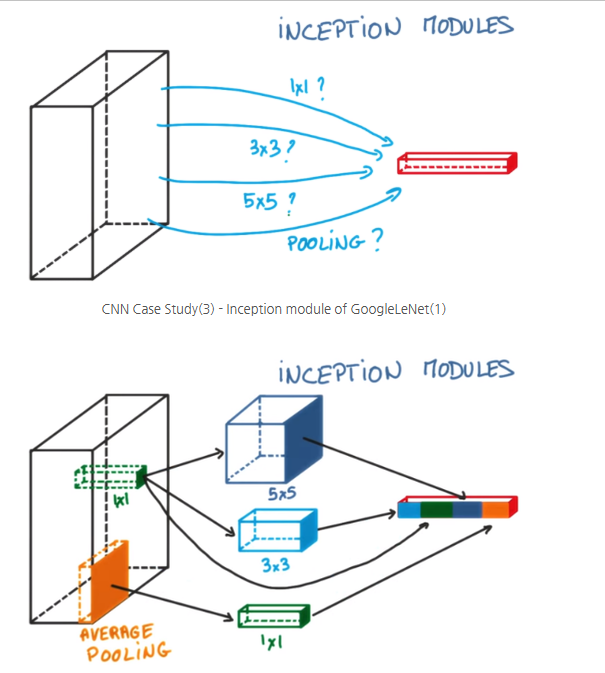
The unique part of GoogLeNet is the Inception Module. Take a look at the diagram below to understand it better.
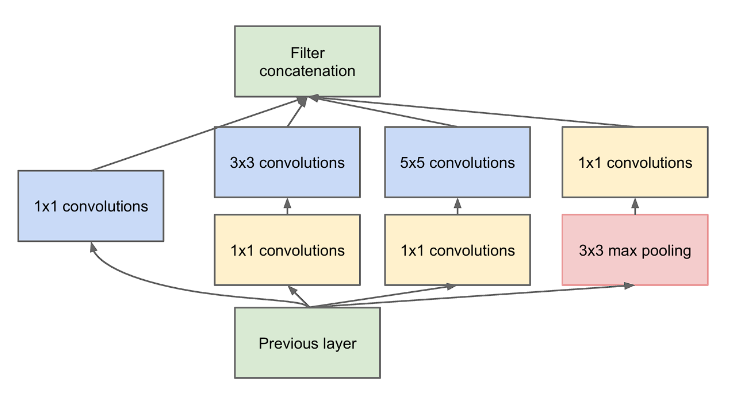
As shown in the diagram above, one way to increase the depth of the network is by extracting feature maps using different kernels, then applying average pooling or max pooling, and finally concatenating the results.
However, GoogLeNet went further and proposed a more efficient structure by combining multiple operations—like pooling and convolutions with different kernel sizes—in parallel. One of the key innovations was the use of 1×1 convolutions, either before or after other operations, forming what’s known as a bottleneck structure.
Using 1×1 convolutions significantly reduced the number of parameters and computation. For example, performing the same operation with 1×1 filters required only around 67,584 parameters (12,288 + 55,296)—a much smaller number compared to what would be needed without them.
Another interesting feature of GoogLeNet is the use of auxiliary classifiers. Instead of having a single softmax classifier at the end, it includes two additional softmax branches in the middle of the network. These auxiliary classifiers help mitigate the vanishing gradient problem by providing additional gradient signals during training.
Lastly, GoogLeNet replaces traditional fully connected layers with Global Average Pooling (GAP) near the end of the network. While the exact mechanism may seem abstract at first, the core idea is that GAP reduces each feature map to a single number by averaging spatial values, effectively summarizing global information without introducing additional parameters—unlike fully connected layers.
5. ResNet
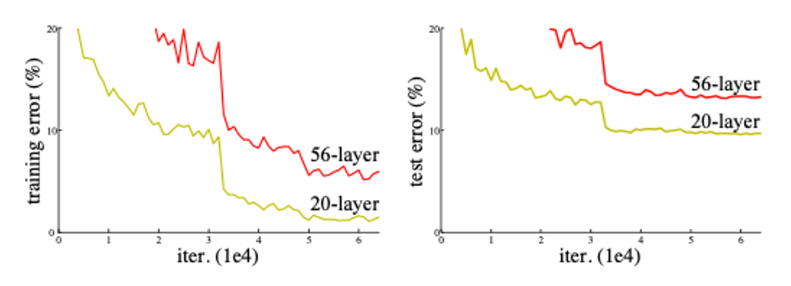
Residual Learning: Tackling the Vanishing Gradient Problem. As mentioned in the previous post, one of the biggest issues with deep neural networks is the vanishing gradient problem. As networks get deeper, gradients calculated during backpropagation tend to shrink. The more layers you have, the more the gradients approach zero, which means the weight updates—especially in early layers—become negligible. In other words, the network struggles to learn because the influence of the output on earlier layers diminishes.
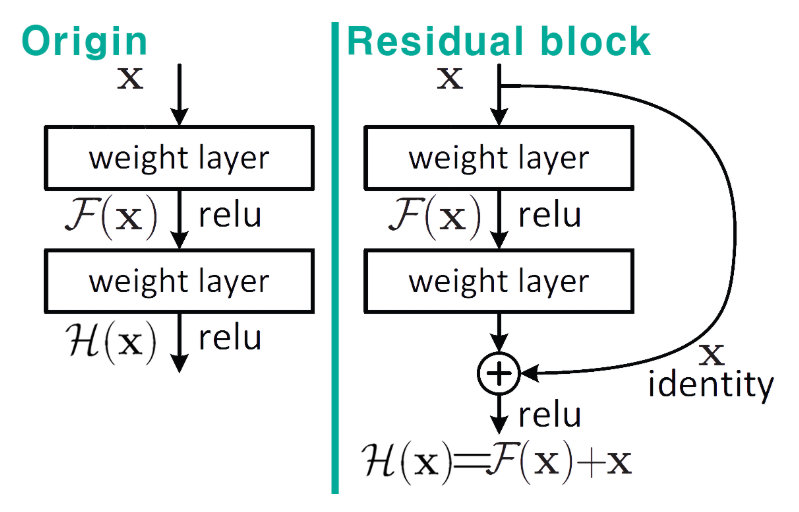
To address this, the concept of the Residual Block was introduced. It uses a mechanism called a skip connection, which forms the basis of residual learning. This allows the gradient to flow directly through the network, helping to mitigate the vanishing gradient issue even in very deep architectures.
Traditionally, the goal was to learn a function H(x) that maps the input x to the desired output y—in other words, to minimize H(x) – y. However, residual learning takes a different approach: instead of learning H(x) directly, the network learns the residual function, which is H(x) – x. The idea is that if the desired mapping is similar to the input, it’s easier to learn the difference between the input and output than the output itself.
By reformulating the learning objective this way, the model becomes easier to optimize and performs better in very deep configurations.
Why F(x) + x Helps: Stabilizing Gradients with Residual Blocks: The diagram above shows what we’ve been building toward: by using Residual Blocks, we compute F(x) + x, where F(x) is the output of a few convolutional layers and x is the original input. The key idea here is that when you differentiate this structure during backpropagation, the gradient always retains a value of 1 through the skip connection, ensuring that at least some portion of the signal survives as it flows backward.
Of course, this doesn’t completely eliminate the vanishing gradient problem, but according to the original paper, the issue was significantly mitigated by using Batch Normalization. Whether BatchNorm fully solves the vanishing gradient issue or just partially helps is still up for debate. One could argue it’s a major breakthrough—or just a minor contributor. Either way, it plays an important role in training very deep networks. BatchNorm’s role is to normalize the output of each layer, helping stabilize the gradient flow and speed up convergence.
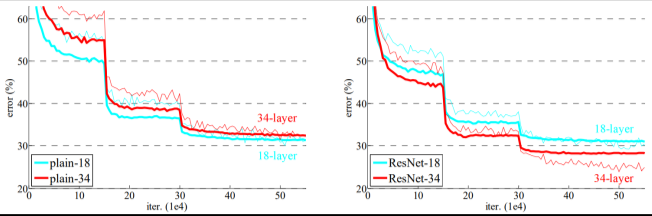
As a result of stacking multiple residual blocks—50 to 152 layers deep—ResNet was able to achieve a depth 8× greater than VGGNet, while still being trainable.
This is how deeply layered networks with Residual Learning end up looking, as illustrated in the diagram below.
According to the paper, as the network depth increases, there is a noticeable trend in performance—but this trend is not necessarily due to overfitting.
Performance Analysis
Cause
Explanation
Resolution
Vanishing Gradient
Weakened gradients in upper layers during backpropagation
Skip Connection
Weight Attenuation
Imbalanced parameter updates in deeper layers
Residual Learning Architecture
Optimization Issues
Non-convex functions increase local minima
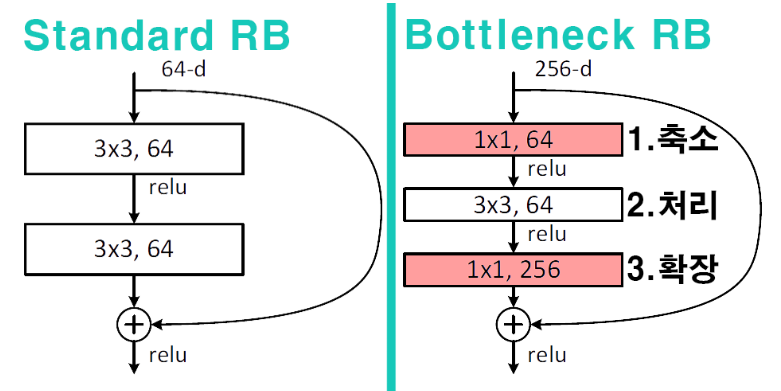
Bottleneck Architecture
The following diagram shows how these challenges have been addressed in the improved architecture.
Reduction stage: Reduce the number of parameters
Processing stage: Extract local features
Input/Output alignment: Match channel dimensions for 𝐻(𝑥) − 𝑥
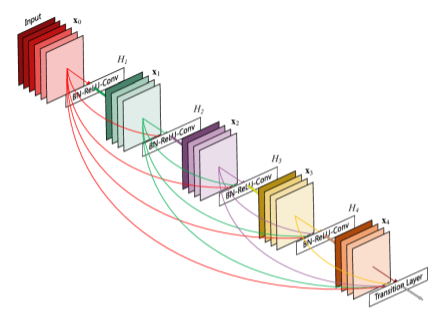
6. DenseNet
As shown above, the layers are densely connected, meaning each layer is connected to every other layer in a feed-forward fashion. This dense connectivity is the key point, and can be seen as an extension of residual learning.
Key characteristics include:
Feature reuse: Each layer receives the outputs of all preceding layers as its input.
Parameter efficiency: The number of feature maps is controlled by a growth rate (k), which limits how much the output grows per layer.
Implicit multi-scale learning: Low-level and high-level features are naturally fused through dense connections, enabling the network to learn across multiple scales automatically.
Component
Role
Mathematical Expression
Dense Block
Preserve feature map connections
xₗ = Hₗ([x₀, x₁, …, xₗ₋₁])
Transition Layer
Reduce dimensions and prevent redundancy
T(x) = Conv₁×₁(BN(ReLU(x)))
Bottleneck Layer
Improve computational efficiency
Hₗ = Conv₃×₃(Conv₁×₁(x))
From the equations above, we can clearly see the difference from ResNet. In ResNet, the residual connection is defined as: 𝑥𝑙 = 𝐻𝑙(𝑥𝑙 −1) + 𝑥𝑙 −1
This means each layer receives input only from the previous layer, and the outputs are summed. In contrast, DenseNet connects all preceding feature maps to the current layer as input, which increases the diversity of learned representations.
One drawback of ResNet is that if the two feature maps being summed come from different distributions, the addition operation may become less effective or even harmful.
In short:
ResNet uses sum
DenseNet uses concat
7. EfficientNet
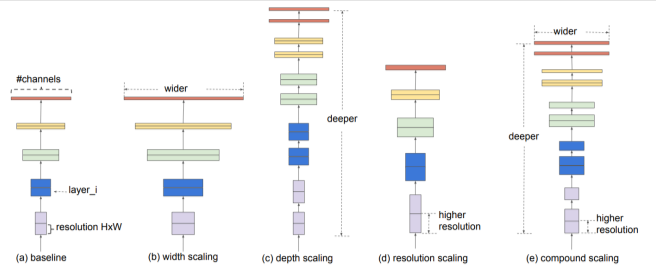
Traditional models typically scale along a single dimension—either depth, width, or resolution. What sets this approach apart is the idea of scaling all three dimensions in a balanced way. This is the core of what’s called Compound Scaling.
So the key point of this architecture lies in how to find the optimal balance between depth, width, and resolution.
Let’s briefly look at what each dimension represents:
Depth: Increasing the number of layers → allows the model to capture more complex patterns
Width: Increasing the number of channels → improves the model’s ability to learn fine-grained features
Resolution: Increasing the input image size → enables the use of higher-resolution spatial information
Based on these definitions, the architecture introduces a compound coefficient, denoted as ϕ (phi), to uniformly scale all three dimensions.
This coefficient is found using a greedy search, which led to the discovery of the following scaling constants: α=1.2 (depth) β=1.1 (width) 𝛾 =1.15 (resolution).
These constants are then used to guide the compound scaling process in EfficientNet | Component | Technique | Mathematical Expression | |——————-|———————————-|———————————————————————-| | MBConv | Inverted residual block | F̂(x) = T_proj(T_expand(x)) ⊙ SE(T_dw(x)) | | SE Block | Channel-wise attention modulation| w_c = σ(W₂ δ(W₁ · GAP(x))) | | Swish Activation | Smooth activation function | swish(x) = x · σ(βx)
6. MobileNet
Just from the name alone, it’s clear where this model is meant to be used—on mobile devices. It’s a deep learning model designed specifically for mobile and resource-constrained environments.At its core, the key challenge was: “How can we reduce the amount of computation?” and that’s exactly what this architecture set out to solve.
In MobileNet, the goal is to balance latency and accuracy. Ultimately, the model achieves successful lightweight optimization, making it suitable for mobile and embedded devices.
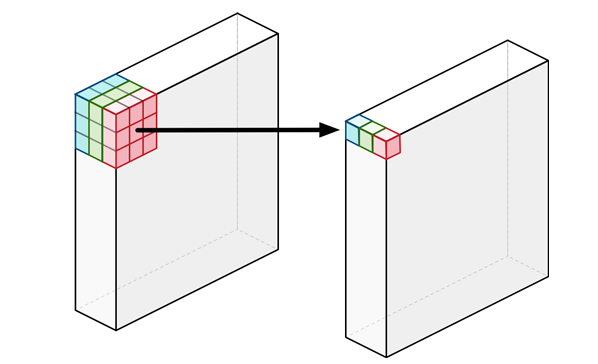
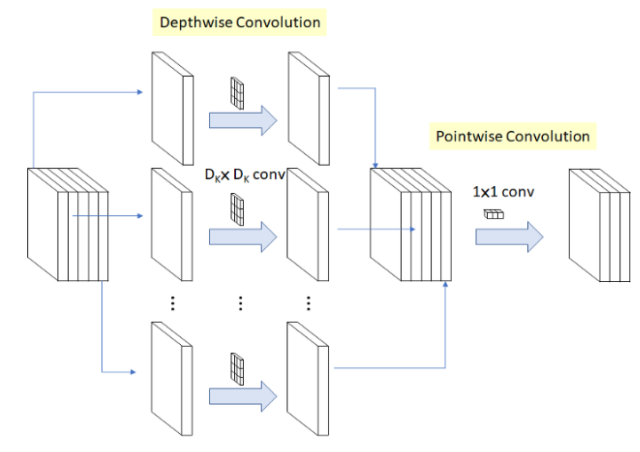
To understand how this is done, it’s important to grasp the concept of Depthwise Separable Convolution.
Unlike standard convolutions (often referred to as pointwise convolutions when using 1×1 kernels), depthwise separable convolutions learn a separate filter for each input channel. In traditional convolutions, each filter operates across all input channels, making it difficult to isolate spatial features. Depthwise convolution, on the other hand, performs a convolution independently per channel, similar to grouping filters—a technique that dramatically reduces computation while retaining performance.
Technique
Description
Channel Reduction
Reduce the number of channels using a width multiplier: channels × α (e.g., α = 1.0, 0.75, 0.5)
Compression
Reduce model size and parameters by setting a smaller α (e.g., α = 0.5)
Evenly Spaced Downsampling
Use stride = 2 in early layers (e.g., 224×224 → 112×112)
Shuffle Operation
Shuffle channels to promote cross-group information flow (e.g., ShuffleNet)
Knowledge Distillation & Compression
Model compression techniques like pruning, quantization, and distillation