CUDA Kernel
Kernel Function (Vector Addition)
일반적으로 c 에서는 두가지의 Vector(Array) 를 더한다고 가정을 했을때, 아래의 방식대로 더한다.
int main(void) {
// host side
const int SIZE = 6;
const int a[SIZE] = {1, 2, 3, 4, 5, 6 };
const int b[SIZE] = {10, 20, 30, 40, 50, 60 };
int c[SIZE] = {0};
for (register int i = 0; i < SIZE; ++i) {
c[i] = a[i] + b[i];
}
return 0;
}
```add.cu
위의 For-Loop 안에 있는 Body 가 있다, 이때를 `Kernel Function` 이라고도 한다. (with proper value). 실제 예시로는 아래와 같다. 왜 굳이 idx 를 넘기느냐는 병렬 처리를 위해서 `Kernel Function` 을 Define 하는것과 같다. 하지만 여기도 아직은 CPU 에서 처리를 하는거다. (CallStack 에는 CPU[0] executes add_kernel(0 ...)) 이런식으로 수행이 SIZE - 1 만큼 될거다. 즉 이건 sequential execution 이라고 생각한다.
```c
void add_kernel(int idx, const int* a, const int* b, int*c) {
int i = idx;
c[i] = a[i] + b[i];
}
for (register int i = 0; i < SIZE; ++i) {
add_kernel(i, a, b, c);
}
만약 multi-core CPU’s 또는 Parallel Execution 을 한다고 가정을 하면 어떨까? 즉 코어가 2개라면, 짝수개씩 병렬로 처리가 가능하다.
at time 0: CPU = core#0 = executes add_kernel(0, ...)
at time 0: CPU = core#1 = executes add_kernel(1, ...)
at time 1: CPU = core#0 = executes add_kernel(2, ...)
at time 1: CPU = core#1 = executes add_kernel(3, ...)
...
at time (n-1)/2: CPU = core#1 = executes add_kernel(SIZE - 1, ...)
그렇다면 GPU 는 어떻게 될까? GPU 는 엄청 많은 Core 들을 가지고 있기 때문에, 엄청난 Parallelism 을 가지고 갈수 있다. 아래와 같이 Time 0: 에 ForLoop 을 처리를 병렬 처리로 할수 있다는거다.
at time 0: CPU = core#0 = executes add_kernel(0, ...)
at time 0: CPU = core#1 = executes add_kernel(1, ...)
at time 0: CPU = core#2 = executes add_kernel(2, ...)
at time 0: CPU = core#3 = executes add_kernel(3, ...)
...
at time 0: CPU = core(#n-1) = executes add_kernel(SIZE - 1, ...)
위의 내용을 정리 하자면 아래와 같다. 즉 시간 순서별로 처리를 하는쪽은 CPU, 코어별로 처리를 하는건 GPU 라고 볼수 있다.
| CPU Kernels | GPU Kernels |
|---|---|
| with a single CPU Core, For loop | a set of GPU Cores |
| sequential execution | parallel execution |
| for-loop | kernel lanuch |
| CPU[0] for time 0 | GPU[0] for core #0 |
| CPU[1] for time 1 | GPU[1] for core #1 |
| CPU[n-1] for time n-1 | GPU[n-1] for core #n-1 |
CUDA vector addition 같은 경우 여러가지 Step 이 있다고 한다.
- host-side
- make A, B with source data
- prepare C for the result
- data copy host -> device
- cudaMemcpy from host to device
- addition in CUDA
- kernel launch for CUDA device
- result will be stored in device (VRAM)
- data copy device -> host
- cudaMemcpy from device to host
- host-side
- cout
Function Call vs Kernel Launch
기본적으로 C/C++ CPU 에서는 Function 을 부를때, Function Call 이라고 한다, 이의 Syntax 는 아래와같다.
void func_name(int param, ...);
for (int i = 0; i < SIZE; i++) {
func_name(param, ...)
}
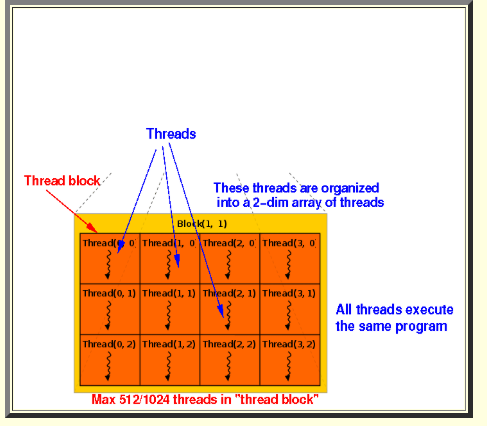
하지만 GPU 에서는 많이 다르다. c++ 에서 사용했을때와 다른 방식으로 Kernel(function) 을 사용한다. 이 Syntax 같 경우 Kernel launch Syntax 라고 한다. 의미적으로는 1 세트에 SIZE 만큼의 코어를 사용하겠다가 되는것이다. 또 다른 의미는 바로 1 이라는 인자 값은 Thread Block 몇개를 사용할건지와, 그 Thread Block 에 Thread 를 몇개 사용할지가 정의가된다. Thread Block 안에있는 Thread 는 코드 아래의 그림을 참조 하면 좋을것 같다.
__global void kernel_name(int param, ...);
kernel_name <<<1, SIZE>>>(param, ...)
실제로 예제 파일은 아래와같다. addKernel 이 실제로는 GPU 안에서의 FunctionCall 형태가 될거고, Index 를 넘기지 않기 때문에, 내부안에서 내 함수 Call 의 Index 를 찾을수 있다.
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
printf("%d\n", i)
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
// ...
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Launch a kernel on the GPU with one thread for each element.
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
//...
// cudaDeviceSynchronize waits for the kernel to finish, and returns
cudaError_t cudaStatus = cudaDeviceSynchronize();
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c)
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
아래와 같이, cudaDeviceSynchronize() 는 kernel 이 끝날때까지 기다렸다가 Error_t 를 Return 을 하게 된다. 성공을 하면, cudaSuccess 를 받는다. 그리고 마지막으로는 CPU 쪽으로 복사를 해준는 구문 cudaMemcpy(...) 가 존재하고, Error 를 내뱉는곳으로 가게된다면, CudaFree 를 해준다.
물론, Host 쪽에서 계속 쭉 Status 를 사용해서, 기다리지만 Kernel 안에서, Kernel launch 중에도 에러가 발생할수 있다. 그 부분은 아래와 같이 받을수 있다. 원래는 cudaError_t err = cudaPeekAtLastError() 그리고 cudaError_t err = cudaGetLastError() 가 있다 둘의 하는 역활은 동일하다! 하지만 내부안에서 있는 Error Flag 를 Reset 을 해주는게 cudaGetLastError() 이며, cudaPeekAtLastError() 는 Reset 을 하지 않는다. 그말은 Reset 을 last error only 가 아니라 모든 Error 에 대해서 저장을 한다고 생각을 하면된다. 그리고 아래처럼 Macro 를 설정을 해주어도 좋다.
// Check for any errors launching the kernel
cudaError_t cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
cudaError_t err = cudaPeekAtLastError();
// CAUTION: we check CUDA error even in release mode
// #if defined(NDEBUG)
// #define CUDA_CHECK_ERROR() 0
// #else
#define CUDA_CHECK_ERROR() do { \
cudaError_t e = cudaGetLastError(); \
if (cudaSuccess != e) { \
printf("cuda failure \"%s\" at %s:%d\n", \
cudaGetErrorString(e), \
__FILE__, __LINE__); \
exit(1); \
} \
} while (0)
// #endif
근데 여기서 궁금증이 있을수 있다. 예를 들어서, c++ 에서는 Return 의 반환값을 지정할수 있었지만, Kernel 은 그렇지 못하다. 무조건 void 로 return 하게끔해야한다. 이건 병렬처리를 하기 때문에, 100 만개의 병렬처리를 한다면 100 만개의 return 값을 가지게 되는데 이건 error code 에 더 가깝다. 그러면 계산이 끝났다라는걸 명시적으로 어떻게 확인하느냐가 포인트일 일것 같다. 바로 Memory 를 던져줬을떄, 그 배열을 update 해서 GPU 에서 CPU 로 데이터가 Memcopy 가 됬을때만 확인이 가능하다.
예제 파일로 Vector 안에 모든 Element 에 +1 씩 붙이는 프로그램을 실행한다고 하면 아래와 같이 정의할수 있다.
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void add_kernel(float *b, const float *a)
{
int i = threadIdx.x;
b[i] = a[i] + 1.0f;
}
int main()
{
const int arrSize = 8;
const float a[arrSize] = { 0., 1., 2., 3., 4., 5., 6., 7. };
float b[arrSize] = { 0., 0., 0., 0., 0., 0., 0., 0., };
printf("a = {%f,%f,%f,%f,%f,%f,%f,%f\n", a[0], a[1], a[2], a[3], a[4], a[5], a[6], a[7]);
float* dev_a = nullptr;
float* dev_b = nullptr;
cudaError_t cudaStatus;
cudaMalloc((void**)&dev_a, arrSize * sizeof(float));
cudaMalloc((void**)&dev_b, arrSize * sizeof(float));
cudaMemcpy(dev_a, a, arrSize * sizeof(float), cudaMemcpyHostToDevice);
add_kernel <<<1, arrSize >>>(dev_b, dev_a);
cudaStatus = cudaPeekAtLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
}
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize r eturned error code %d after launching addKernel!\n", cudaStatus);
}
// Result
cudaStatus = cudaMemcpy(b, dev_b, arrSize * sizeof(float), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
}
printf("b = {%f,%f,%f,%f,%f,%f,%f,%f\n", b[0], b[1], b[2], b[3], b[4], b[5], b[6], b[7]);
cudaFree(dev_a);
cudaFree(dev_b);
return 0;
}
그리고 참고적으로 꿀팁중에 하나는 const char* cudaGetErrorName( cudaError_t err) 이 함수가 있다.cudaError_t 를 넣어서 확인이 가능하며, Return 이 Enum Type 의 String 을 char arr 배열로 받을수 있으니 굉장히 좋은 debugging 꿀팁일수 있겠다. 또 다른건 const char* cudaGetErrorString(cudaError_t err) err code 에 대한 explanation string 값으로 return 을 하게끔 되어있다. 둘다 cout << <<endl; 사용 가능하다.
cudaGetLastError() -> Thread 단위 처리
여러가지의 Cuda Process 가 돌릴때, 내가 사용하고 있는 프로세스에서 여러가지의 Thread 가 갈라져서, 이들 thread 가 Cuda system 을 동시에 사용한다고 한다라면, CUDA Error 를 어떻게 처리하는지에 대한 고찰이 생길수도 있다. 그래서 각 Cpu Thread 가 Cuda 의 커널을 독자적으로 사용한다고 가정을 하면 Cuda eror 는 Cpu thread 기준으로 err 의 상태 관리를 하는게 좋다.
