Reviewing what I studied, how this work will be explained as well.
Graph Traversal
When we have a graph with nodes and edges, the problem of starting from a specific node and visiting all other nodes is called a Graph Traversal Problem or Graph Search. This traversal problem can be properly stated as:
Given a graph G = <V, E>, starting from a specific node s, visit all nodes (vertices) v in V.
BFS
BFS starts by expanding a frontier from the starting point (frontier: nodes previously visited). It then visits adjacent nodes from the current node.
BFS visits child nodes before grandchild nodes, making it equivalent to Level Order Traversal in trees (Root -> Left -> Right).
It is typically implemented using a Queue. The algorithm starts by placing the starting node in the queue, then repeatedly removes a node from the queue, checks all adjacent nodes, marks unvisited nodes as visited, and adds them to the queue. This process continues until the queue is empty.
Implementation
This implementation made an assumption that we are given adjacent link list.
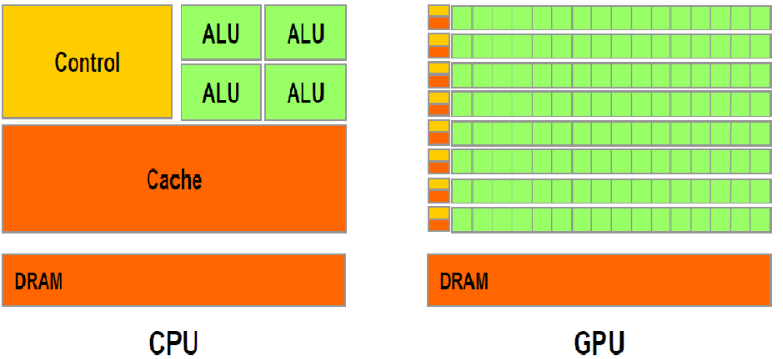
일단 장치 초기화 하기 이전에, Hardware 를 알아보자. 컴퓨터를 뜯어봤으면 알수 있는건 바로 CPU 와 GPU 를 한번쯤은 봤을것이다. 아래의 구조를 한번 보자.
CPU 는 마치 고급인력 처럼 보인다. CPU 는 뭔가 큰작업을 빠르게 처리할수 있는 ALU 4 개가 있고, 반대로 GPU 같은 경우는 수많은 ALU 가 존재하는데 약간 인력집단처럼 정말 많다. 바로 여기서 힌트를 얻을수 있는게, 단순 또는 값싼 인력을이 많아서, 독립적인 일을 병렬로 처리할수 있게 보인다. 만약 독립적인일을 CPU 로 하기엔 뭔가 고급 인력들을 잡일로 시키는것 같다. 그래서 주로 CPU 같은 경우, 뭔가 데이터나 연산들이 서로가 서로 연관관계일때 주로 사용되는게 좋다. 다시 정리해서 말하면 CPU 는 고급인력이고, GPU 는 약간 외주(outsourcing) 을 하는 느낌이다. GPU 에게 외주를 맡길거면, 어떤 일을 해야 하는지, 사인을 어느 부분에서 해야하는지, 등 알려주는게 좋아서, 바로 Rendering Pipeline 이라는게 정의가 되었다.
Rendering Pipeline in DirectX
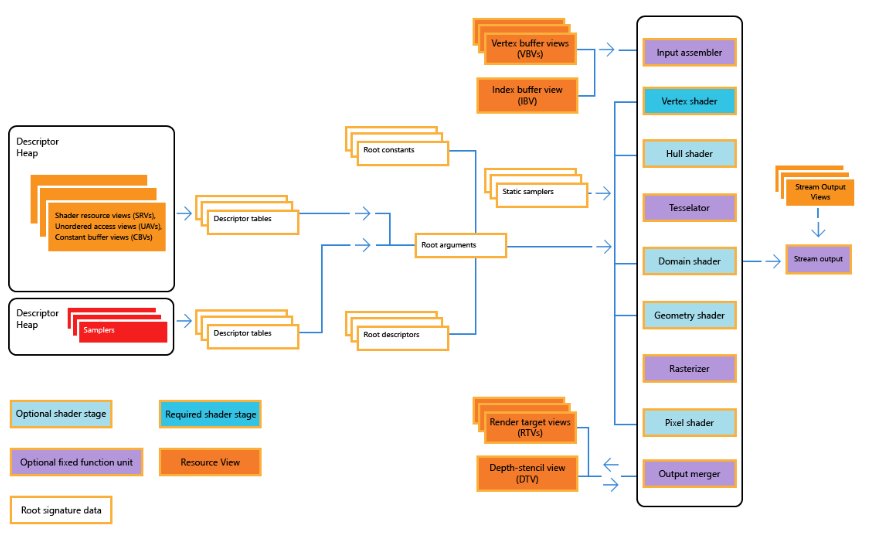
아래의 그림이 DirectX3D 11 의 Rendering Pipeline 이다. 각각이 뭐를 하는지 briefly 하게 넘어가보자.
Input Assembler 에서는 정점(Vertex) 의 정보들을 전달해주는거라고 생각을 하면 된다. 예를들어서 삼각형의 정점들이 어떻게 이루어졌는지. Vertex Shader 같은 경우, 아까의 정점들을 가지고 연산을 하는 단계이다. 예를들어서, Morphing, Translation, 등 정점의 이동등을 연산한다. Tessellation Stage 나 Geometry Shader Stage 같은경우 정점을 추가시켜주는 작업을 맡는다. 정점을 추가하는 이유는 예를 들어서 선명도를 좀더 표현하기 위해서 정점을 더 더해줘서 quality 를 올리는 등이 있다.
Rasterization Stage 는 정말 중요하다. 이 stage 가 오기전에는 정점을 가지고 놀았다면, 이제 각 정점에 Pixel 들을 입혀줘서, 삼각형이라고 한다면 어느정도 색깔과 모양을 그럴싸하게 표현해주는 stage 라고 생각하면 된다. 그런다음에 Pixel Shader 같은 경우 색상을 변경또는 조절을 담당한다. 그 다음에 최종 결과물을 이제 Output 으로 넘겨주는 형식이다.
이런 PipeLine 을 더 이해하고, 더 나아가서, GPU 에 다가 어떻게 일감을 던져주는지를 알려면 Device Initialization 이 필요하다. 이 아래에 설명이 있으니 한번 정리 해볼려고 한다.
Device Initialization (Component Descriptions)
일단 설계구조는 이렇다. Engine 안에 CommandQueue, DescriptorHeap, Device, SwapChain, RootSignautre 등이 들어간다. 그리고 Engine 내부에서는 초기화(Init) 이 들어가고, Rendering 을 할수 있는 Render 가 들어갈것이다.
일단 Device 를 한번 보자. Device 같은 경우, 인력 사무소라고 생각하면된다. 즉 GPU 와 소통할 공간이라고 생각하면 된다. 일단 Device 에서는 DirectX 를 지원하기위해서 ComPtr 타입을 사용한다. COM(Component Object Model) 인데, 이건 DX 의 programming 의 독립성과 하위 호환성을 위해서 만들어진 객체이며, COM 객체를 통해서, GPU 에 접근을 할수 있다. 즉 COM 을 사용하려면, ComPtr 을 접근을 통해서 COM 을 관리할수 있다.
Window 에서 device 를 사용하려면, Window API 를 사용해야하는데, 이때 CreateDXGIFactory 들지, D3D12CreateDevice 등 사용된다. 이때 사용되는 함수들은 Direct3D 와 같이 사용될수 있게끔 잘만들어줘야한다. 그래서 Device 객체안에서는 Init 이 존재한다.
그 다음 ComandQueue 를 알아보자. DX12 에 나온 친구인데, 뭔가 외주를 요청했을떄 따로 따로 일을 보내주면, 되게 비효율적이다. 그래서 한꺼번에 Command Queue 를 일들을 넣어줘서 실행시키는게 더 효율적이다. 그리고 Fence 라는 개념도 등장하는데, CPU 와 GPU 의 동기화를 맞춰줄떄 사용된다. 그냥 봐서는 일감만 던져주면 된다고 생각하지만, 만약에 그 일감이 돌아오기까지를 기다려서, 그다음 업무를 실행시킬떄는 Synchronize 를 해줘야하는데 그게 Fence 의 역활이다. 여기에서는 Init 과 sync 를 맞추기 위한 WaitSync 가 필요하다. 그리고 실질적으로 Rendering 이 시작되는 부분과 끝부분이 여기에서 필요하다. Rendering 을 한 결과물을 여기에서 RenderEnd 와 RenderBeging 을 통해서 RenderTarget 을 swapchain 에서 불러 들어와, 지금 현재 뿌려져있는걸 뿌리는걸 Handle 하고, RenderEnd 에서는 Backbuffer 와 현재 screen 에 뿌려진걸 바꿔주면서 다시 일감을 준다. 그리고 RenderEnd 에서 실제 수행한다.
그 다음 SwapChain 대해 알아보자. 일단은 직역을 하자면, 교환사슬이다. 이게 어떻게 사용되는지 생각을 해보면 일단 외주과정을 한번 살펴보면, 게임 세상에 어떤 상황을 묘사해서, 어떤 공식으로 계산을 할것인지를 외주 목록으로 던져줘서, GPU 가 열심히 계산을 한다음에 결과물을 받는다. 이 외주과정을 살펴보면, 한번만 한다고 하면 GPU 에서 처리한다음에 그대로 일을 보여주기만 하면 끝난다. 하지만 실제 게임은 그렇지 않다. 매 Frame 마다 게임은 실행되어야되며, 게임이 실행된다는건, 매 frame 마다 화면이 다르기때문에 GPU 의 계산한값과 CPU 로 부터 보여지는 화면등이 계속 바뀌어야한다는것이다. 그럴려면 SwapChain 이라는게 필요하다. 그리고 외주 결과물은 어떻게 받느냐라고 하면, 어떤 종이(컴퓨터에 관점에서는 buffer) 에 그려달라고 건내주면, 뭔가 특수 종이를 만들어서, GPU 에게 건내준다음에 그려줘서 결과물을 받아서 화면에 출력한다. 즉 이떄 하나의 종이로만 받지말고 CPU 와 GPU 가 사용하는 종이를 두개를 만들어서 바꿔주면 된다. 즉 하나는 현재 화면을 그리고, 나머지 하나는 외주의 결과물을 담으면 된다. 즉 이러한 개념이 Double Buffering 이라고 한다. 결론적으로 BackBuffer 에서는 GPU 의 결과값을 담고, 현재화면에서는 현재의 buffer 를 담고있으면 된다.
SwapChain 에는 backBuffer 의 index 를 가지고 있고, renderTarget 이 array 로 존재하기 때문에 buffer 의 Count 에 따라서 renderTarget 이 변경이된다. 그리고 SwapChain 에서 구현해야되는 함수는 어떤 Index 에 renderingTarget 이 있는지와, 현재 어떤것을 뿌려야해는지 등 있다.
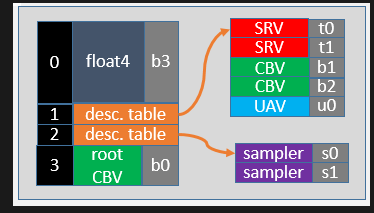
그 다음 descriptorHeap 이다. 일단 외주를 하는건 좋다. 하지만 기안서 즉, 어떤 어떤것을 실행해주고, 어떤 형태의 양식을 넘겨줘서 일을 맡겨야 속이 시원하다. 아무형태나 같다주면, 이게 뭐야 쓰레기인가 하면서 처리하지 못한다. 즉 descriptorHeap 에서는 각종 리소스를 어떤 용도로 사용하는지 꼼꼼하게 적어서 넘겨주는 역활이다.
DescriptorHeap 같은 경우 DX12 에서 생겨난건데, 이 descriptor Heap 을 통해서 RenderTargetView(RTV) 를 설정한다. 즉 기안서를 실행을 하면, 어떠한곳에서 Handle 을 하라고 넘겨줄거고, SwapChaing 에서 descriptor 를 실행해 그리고, RenderTargetView 를 생성해서, 만들어지면 SwapChain 에서 바꿔준다. 그리고 Resource 를 넘겨줄때, 그냥 넘겨주는게 아니라, 기안서(View) 를 통해 넘겨줘야하는데 backbufferview 로 넘겨주는 형식이다. 결론적으로 말해서 DescriptorHeap 은 어떤 Array 의 형식으로 이뤄져있는데, array 의 element 가 여러개의 View 를 가지고 있고, 그게 원본 resource 를 가르키고 있다.
즉 Engine main code 에서는 Render 를 할떄 CommandQueue 의 RenderBegin 과 RenderEnd() 가 계속 돌아간다.
그 다음 Root Signature 이다. 이건 약간 결재 또는 계약서이다. 즉 무엇을 대상으로 데이터를 가공하는지를 GPU 가 알고 있어야한다. 즉 CPU 에서 GPU 로 일감을 넘길때 어떤 data 나 resource 를 주는데 가공방법이나 이런걸주는데 서명을 해야 된다. 이것이 root signature 이다. 더나아가서 어떤 버퍼에서는 이런걸을 하기로 계약을하고 다른 버퍼에서는 이걸 계약하겠다라는 승인이 필요하다.
Root Signatuer 을 이해하려면 CPU 와 GPU 의 메모리구조의 이해가 필요하다. Cache 나 Register 안은 메모리의 양도 적지만 빠르다. 하지만 물리적인 관점에서 봤을때 우리가 사용하는 하드메모리는 평민같아서 되게 멀기도하고 딱히 외주를 넘겨줄때 승인이 필요하지 않다. 하지만 Register 나 Cache 같은 친구들은 비싼친구들이기 때문에 조금 승인받는것도 빡세다. 그래서 root signature 같은 경우 option 이 필요하다. 즉 성명 Type 이 필요하다. 처음에는 API 의 칸을 설정을 해주고, 중간에는 어떠한 용도로 사용 될지가 들어가고, 마지막은 shader programming 에서 register 의 bind 할 slot 이라고 생각하면 된다. 여기에서 중요한게 data 를 실제로 넣으려고 하는게 아니라, 계약서에 이러한 이러한 정보를 담겠다가 맞다. 즉 Resource 를 어떻게 어디서 붙힌다라는걸 설명해주는 문서 라고 생각하면 된다. 그리고 Register 를 선택한 이후에, Option 이 들어가는게 Pipeline 안에 stage 들을 보여줄수있는 옵션도 있다.
Root signautre 를 사용할때, constant buffer 를 사용하는데 CPU 와 연결되어있는 메모리를 GPU 에 있는 메모리에 옮겨준다음에, register 에 buffer 의 주소값만 던져주고, 나중에 CommandQueue 에서 처리할때, GPU가 일을 할수 있게 된다.
그 다음 Mesh 와 shader 이다. Mesh 같은 경우 즉 정점의 정보들을 가지고 있어야한다. resource 를 바로 보내는게 아니라 descriptorHeap 처럼 bufferview 라는걸 보여줘야한다. 여기에서 중요한건 뭐냐, 일단 vertex 의 정보를 buffer 에 넣어서 CPU 에서 만들어준 다음, 그 buffer 를 GPU 메모리에 할당을 해준다. 그렇다면 Mesh 가 Render 되는 부분은 CommmandQueue 안에 RenderBegin 과 RenderEnd 에 나머지부분을 그려주는 형태이다. 그리고 그리는 방식 또는 Topology 형태를 Parameter 로 지정이 가능하고, vertex buffer view 를 slot 에 끼워넣어서 vertex 를 그릴수 있다.
Shader 는 무엇이냐? 라고 묻는다면, 바로 외주인력들이 무엇을 해야하는지 말해주는거다. 뭔가 거대한 거물들이 계약서도 받고 도장도 찍었으면, 이제 그 거물급들이 각각의 인력들에게 오케이 이제 오늘부터 이거 해야되라고 말하는것이다. 즉 일감 기술서 이다. shader 프로그램을 읽고 로딩해서 실행한다. shader 에는 pixel shader (part of fragment shader) 와 vertex shader 가 존재한다. 잠깐 shader program? shader program 이 다행히 c++ 와 비슷한 syntax 를 가지고 있어서, 짜기도 쉬운데 문제는 Main 에서 Parameter 를 한정적으로 받을수 있다는게 문제이다. 아래의 Graphic Pipeline 을 한번 봐보자. 아래의 그림을 보면 Input Assember Stages 에서는 멋대로 data 값을 넘겨줄수 없다.(다른 stage 와 달리)
정리 해보자면….
ComPtr:
Microsoft 사에서, COM Object (Interface) 를 통해서, 각각의 DX 들을 접근
일종의 Smart Pointer
깡 Pointer 로 했을때는, 직접 Release() 를 해야함
Device
GPU 및 리소스 생성의 총괄 관리자 -> 인력사무소 (GPU)
CreateDXGIFactory() → DXGI 팩토리 생성
D3D12CreateDevice() → 실제 장치 생성
CommandQueue
외주 목록 큐
GPU 작업을 보내는 큐
ID3D12CommandAllocator: 명령 기록용 메모리 공간 –> 일감의 양
ID3D12GraphicsCommandList: 명령 목록 작성용 –> 작업 지시서
CommandList->Close() 후 Queue에 제출
Fence: GPU 작업 완료를 추적하는 동기화 객체 –> 작업 완료 알림 벨
SwapChain
결과물 전달 시스템
GPU에서 작업한 결과를 화면에 표시
BackBuffer: GPU가 그리는 대상
FrontBuffer: 화면에 출력되는 대상
Double Buffering 구조
Present()로 전환
DescriptorHeap
메뉴판
리소스를 설명하는 뷰들의 배열 (Texture, Buffer, Resource)
CBV / SRV / UAV / RTV / DSV 등을 저장
DX11의 View 역할 (RenderTargetView 등)
DescriptorTable
한 작업자용 메뉴세트
여러 Descriptor를 묶어서 Shader에 전달
Root Signature를 통해 바인딩
효율적인 리소스 접근을 위함
RootSignature
계약서 또는 결제
*CPU와 GPU는 메모리 구조가 다르기 때문에 데이터를 직접 공유할 수 없습니다. 대신, 특정한 형식으로 데이터를 준비하여 GPU가 이해할 수 있도록 전달해야 합니다.
Root Signature는 이 과정에서 어떤 리소스(메모리)를 사용할지 명시하여, CPU와 GPU가 어떤 데이터를 주고받을지 미리 정의합니다.
항상 연말에는 페이스북에 많은 개발자 회고록이 올라온다. 계속 보고만 있었는데, 많은 사람들이 여러 책을 읽고, 자기 개발을 하는거 보고 있다. 나도 나름대로 노력을 한것 같다. 그리고 2022 년에는 되게 많은 일들이 있었던것 같다. 그리고 한국 1년 개발자가 되어있는 나를 보며 회고록을 쓰려고 한다.
Adjustment & Changes
일단 저번해가 지나고 나서 많은 공부와 노력이 따로 필요했었다. 새로운 팀으로 넘어가 지속적인 개발이 필요했었고, 그때만큼은 내 몸을 아끼지 않았다. 그래서 운동은 따로 했었지만 허약해 있었고, 과호흡이 왔어서, 응급실을 갔었고 또 코로나에 걸려, 정해진 날짜에 훈련소를 가지 못했어서, 되게 당황했었지만, 나름 그 주 뒤에 바로가서 훈련받고 오고 무사히 돌아왔다. 한국에 적응을 할 시간 조차 없이 너무 이번 한해에 많은 일들이 있었다. 미국에서 바로 한국으로 넘어올시기에 몸이 않좋아 입원, 다음에 바로 취직, 훈련소.. 너무 많은일들이 짧고 굵게 휘몰아 쳤지만, 그래도 나름 생활을 잘했던 2022 년 이였다.
Development Perspective
개발은 정말 많은걸 목표로 두고 있었다. 일단 파이썬으로 개발해서, OpenGL Python, gRPC Interface 에 맞게 request & receive 를 하는 interface 를 만들었었고, 자율주행에서 중요한 맵과 맵을 합치는 것과, Command Pattern 을 이용해서 Undo / Redo Interface 만드는거 까지 했었다. 이걸로 더 나아가 최근에 특허까지 승인이된 우리 회사 Scenario Runner Software는 수많은 Refactoring 과 PyQt UI 구현 및 데이터 전달 부터 OpenScenario에서 정의된 시나리오를 실현시키기 까지 엄청난 노력을 썻다고 해도 무관하다. 나는 그 과정속에서 깔끔한 코드, 그리고 가독성이 높은 코드를 짜려고 많이 고민을 했었다. 사실 협업이라는게 쉽지 않은것도 맞다. 난 코드를 짤때 최대한 남들에게 피해가 안가게끔 짜는 편이였지만 그 방법이 틀리다는걸 잘알고 있다. 조금씩 조금씩 바뀌는것 보다는 조금 일이 많더라도, 방향을 잘잡아야한다 라는 말이 끝까지 와닿었던 Sid meyer 의 말도 참 내 경험상 많은걸 build up 해주었다.
2023 New Goal
2023 년은 되게 많은 일들이 있을것 같으면서도 어느정도의 변화의 짐작이 간다. 일단 일적으로는 MORAI SIM V2 작업을 새로운 언어로 포팅하는 작업을 해야한다. 정말 큰 일이기도 하면서도 어느정도의 시간이 흐를지 반복 테스틑 얼마나 해야될지 가늠이 안가지만, 팀의 성향이 다른 team 들의 영향을 많이 받는 Working Group 이라 어쩔수 없다. 하지만 정말 필요한 스킬은 Communication Skill 이다. 이제는 한국에 적응할 시기가 충분히 지났다.
일단 아래와 같이 나의 Goal 을 맞춰나갈꺼다. 그리고 잘지켜졌으면 좋겠다라는 바램이 있다.
Career 측면에서 일단 세갈래로 크게 나가고 싶다.
Computer Vision
Computer Graphics
Game Dev in C++
일단 Vision 쪽에서는, 카메라에 대한 기초와 3D Geometry 에 대한 공부를 시작 해야한다. 또 이거 말고도 2D 에서 사용되는 feature matching.. 등 pyramid 를 다시 복습하고 싶다. 그리고 graphics 는 DirectX11 이나 Vulkan 으로 rendering pipeline 을 구현 및 설명할수 있는 정도가 되는게 목표이다. 그 이후에 딥러닝을 병합한 dlss 도 한번 살펴봐야한다.
3번쨰는 굉장히 많은 노력이 필요한것같다. 대체적으로 게임 서버 운영 및 다중 플레이어 호환 등 시작해봐야 되며, 게임에 필요한 수학 (especiall on geometry), path planning algorithm, 등 algorithm 공부도 필요하다. 그리고 마지막으로 나만의 게임을 만들어보는게 이번년의 목표이다.
물론 계획이 rough 하지만 필요한부분을 간추렸고, direction 을 못찾았을때, 항상 지표가 되는게 되었으면 좋겠다. 이직도 4월이나 5월에 생각은 하고 있지만 경제상황을 봐서 지혜롭게 움직였으면 좋겠다는 생각이든다.
그리고 책을 이번엔 20권을 목표로 읽을 예정이다. 가끔씩은 이해를 잘못해서 그냥 넘어가는 경향이 있는데, 책을 읽는데만 그치는게 아니라, 생각하는 힘도 키워나아가야한다.
그리고 건강 및 가족 측면에서는 일단 운동은 계속 꾸준히 해야한다. 그리고 단커피와 술을 줄여서 간수치를 내리는것도 목표이다. 가족같은 경우는 더더욱 지금 상태를 유지하고 싶고, 매순간 잘하기로 마음을 먹었다. 취미는 서핑과 기타를 계속 치는게 목표이다. 하지만 많은 (검)토끼를 잡을수 있으니 잠시 내려 놔야할때는 내려놓을 필요도 있어보인다.
2023 년 어려울수도 있고, 그냥 문안하게 잘 지나갈수도 있지만, 조금 더 열심히, 부족한게 있으면 조금더 채워나가는 식으로 갔으면 좋겠다.
Image 를 처음으로 Screen 으로 봤을때, 2D 로 보일거다. OpenCV 를 사용했었더라면, Image Watch 로 봤을때, 각 pixel 값이 2D image 에 잘 저장이되어 보인다고 볼수 있다.
사실은 내부적으로 어떻게 되는지? 를 궁금해할수있다. C++ 에서의 운영체제에서는 데이터를 받을때 1차원형태로 받는다. 만약에 image 의 pixel 값이 [0, 255] 을 값을 Normalize 를 0 과 1 사이로 한다면, 한 element 에 들어가는것은 바로 float 값일거다. 그래서 float* myImg = new [width * height] 이런식으로 해서 Image를 1D 로 보관한다. 즉 어떻게 Indexing 하느냐에 따라서 2D 로 배열을 바꿀수 있다.
주로 기초적인 질문일수 있지만, API 를 사용하다보면 놓칠수도 있다. 왼쪽 가로축으로 시작해서 오른쪽으로 한칸 한칸 움직이고(Column), 그 다음 row 에 가서 위와 같은 방법으로 indexing 을 할 수 있다. 예를들어서 (0, 0), (1, 0), (2, 0) .. 이런식으로 가다가 두번째 row 에서는 (0, 1) (1, 1), (2, 1) .. 이런식으로 가서 맨 아래의 element 에서는 (#column, #row) 가 되는식으로 될것이다.
그렇다면 다시 거꾸로 해서, 2D image 에서 (2, 3) 이라는 데이터가 있다고 가정하자. 그리고 (2,3) 에 가서 data 를 변경 한다고 가정하면, 우리에게 주어진건 1D data 이기 때문에, 17 번째의 Index 를 찾아야한다. 어떤 인덱스 (i, j) 에서 1차원 index 를 가지고 올수 있는 방법은 i + width * j 이다.
Handling Screen(Image)
일단 Graphics 관점에서 뭔가 screen 에다가 표현을 하고 싶다고 한다면, DirectX11 을 사용해서 Pixel 값들을 움직일 수 있다. 여기서 Vec4 라는 구조체를 넣어서, screen 좌표에 있는 모든 pixel 값들을 하얀색으로 지정해준다. 그런 다음에 Update 에서 while 문에서 호출 했었을때, screen 좌표에있는 Pixel 을 빨간색을 칠해주고 그다음 pixel 을 가서 또 칠해준다. 즉 빨간색 pixel 이 움직이는것 처럼 보이게 할수 있다.
아래 부분의 주석으로 되어있는 코드는 CPU 에서 Memory 를 Map 을 만들어주고, memory copy 를 해서 GPU 에 넘겨주는 코드 부분이다. 이게 사실 Bottle Neck 이 될수 있다. 더 자세한건 Grpahics Pipeline 을 한번 참고 하기를 바란다.
제일 Image 를 해석하려면, 제일 좋은게 뭐일까라고 물어본다면 바로 이미지를 읽고 저장하는게 제일 중요하다. OpenCV 를 사용해서 Image 를 읽는것도 있지만, 제일 쉬운건 Python 에서 pip 관리 하는것처럼 vcpkg 를 사용해서 stb 를 사용하는게 제일 좋다. (단 image 가 너무 커질때는 조심해야한다.)
#define STB_IMAGE_IMPLEMENTATION
#include<stb_image.h>
#define STB_IMAGE_WRITE_IMPLEMENTATION
#include<stb_image_write.h>
#include<algorithm> // std::clmap(c++ 17)classImage{public:intwidth=0,height=0,channels=0;std::vector<Vec4>pixels;voidReadFromFile(constchar*fileName);voidWritePNG(constchar*filename);Vec4&GetPixel(inti,intj);}voidImage::ReadFromFile(constchar*fileName){// 대부분의 img 는 0 ~ 255 값을 가지고 있기때문에 unsigned char 로 저장unsignedchar*img=stbi_load(fileName,&width,&height,&channels,0);if(width){std::cout<<width<<" "<<height<<" "<<channels<<std::endl;}else{std::cout<<"Error: reading "<<filename<<" failed."<<std::endl;}// channel 이 3 이나 4 일걸 가정pixels.resize(width*height);for(inti=0;i<width*height;i++){pixels[i].v[0]=img[i*channels]/255.0f;pixels[i].v[1]=img[i*channels+1]/255.0f;pixels[i].v[2]=img[i*channels+2]/255.0f;pixels[i].v[3]=1.0f;}delete[]img;}voidImage::WritePNG(constchar*filename){// 32bit -> 8bitsstd::vector<unsignedchar>img(width*height*channels,0);for(inti=0;i<width*height;i++){img[i*channels]=uint8_t(pixels[i].v[0]*255.0f);img[i*channels+1]=uint8_t(pixels[i].v[1]*255.0f);img[i*channels+2]=uint8_t(pixels[i].v[2]*255.0f);}stbi_write_png(filename,width,height,channels,img.data(),width*channels);}Vec4&Image::GetPixel(inti,intj){i=std::clamp(i,0,this->width-1);j=std::clamp(j,0,this->height-1);returnthis->pixels[i+this->width*j];}
위의 함수를 적절히 이용해서, 아래와 같은 Image Data 를 읽고 저장할수 있다. 사진의 해상도가 높다면 깨질수도 있으니 확인이 필요하다.
Convolution
Deep Learning 에서 Image Object Detection 을 해봤더라면 Convolution Layer 라는 걸 사용해 본적이 있을것이다. 그리고 OpenCV 에서 Kernel size 아니면 Masking 을 사용하거나 적용해서 Edge 를 더 나타내거나, 여러 Blur 종류 들을 볼수 있을것이다. Convolution 의 내용은 아래 6 Basic Things to Know about Convolution 과 A Basic Introduction to Convolutions 를 참고하기 바른다.
Computer Graphics 측면에서 Convolution Filter 를 사용하게되면 연산량이 많아진다. 그래서 Separable Convolution 을 사용한다. Separable Convolution 같은 5 x 5 의 Kernel 이 있다고 하면 Middle point 에서 row 값을 평균을 내고, column 값에서 평균을 낸다. 즉 중앙을 기준으로 row 를 평균, column 을 평균을 내는 방식이다.
그렇다면 Box Blur 를 구현을 해보자. 구현 내용은 아래와같다. GetPixel 함수에서 clamping 을 했기 때문에 만약에 Padding 이 없을 경우, -2, -1 값들은 0, 1 로 push 하게 된다.
가우시안 Blur 를 사용하려면, weight 값을 줘야 된다. const float weights[5] = { 0.0545f, 0.2442f, 0.4026f, 0.2442f, 0.0545f };
위에서 Box Blur 와 마찬가지로 해결해보면, 아래와 같은 코드가 나온다.
for(inti=0;i<this->width;i++){Vec4neighborColorSum{0.0f,0.0f,0.0f,1.0f};for(intsi=0;si<5;si++){Vec4neighborColor=this->GetPixel(i+si-2,j);neighborColorSum.v[0]+=neighborColor.v[0]*weights[si];neighborColorSum.v[1]+=neighborColor.v[1]*weights[si];neighborColorSum.v[2]+=neighborColor.v[2]*weights[si];}pixelsBuffer[i+this->width*j].v[0]=neighborColorSum.v[0];pixelsBuffer[i+this->width*j].v[1]=neighborColorSum.v[1];pixelsBuffer[i+this->width*j].v[2]=neighborColorSum.v[2];}for(intj=0;j<this->height;j++){for(inti=0;i<this->width;i++){// 주변 픽셀들의 색을 평균내어서 (i, j)에 있는 픽셀의 색을 변경// this->pixels로부터 읽어온 값들을 평균내어서 pixelsBuffer의 값들을 바꾸기Vec4neighborColorSum{0.0f,0.0f,0.0f,1.0f};for(intsi=0;si<5;si++){Vec4neighborColor=this->GetPixel(i,j+si-2);neighborColorSum.v[0]+=neighborColor.v[0]*weights[si];neighborColorSum.v[1]+=neighborColor.v[1]*weights[si];neighborColorSum.v[2]+=neighborColor.v[2]*weights[si];}pixelsBuffer[i+this->width*j].v[0]=neighborColorSum.v[0];pixelsBuffer[i+this->width*j].v[1]=neighborColorSum.v[1];pixelsBuffer[i+this->width*j].v[2]=neighborColorSum.v[2];}}
Bloom Effect
Bloom 효과 같은경우는 밝은 Pixel 은 가만히두고, 어두운 Pixel 을 전부다 검은색으로 둔다음에 Gaussian Blur 를 사용한다. 그런다음에 원본이미지와 Blur 된 이미지를 더하면, Bloom Effect 가 일어난다. 일단 어두운 Pixel 을 전부다 검은색으로 바꾸는게 중요하다. 아래의 Resource 에서 Relative Luminance 를 참고하길 바란다. 그래서 이 식으로 하면 된다. Relative Luminance Y = 0.2126*R + 0.7152*G + 0.0722*B.
구현 방법은 아래와 같다. 즉 Pixel 을 가지고 와서 Relaitve Luminance 를 곱한 이후에, 어떤 threshold 에 넘는다고 하면 0 으로 바꿔치기하는 기술이다.
일반적으로 학교에서 배우는 모든 단순한 project level 은 단일 Core CPU 라고 생각하고 하나의 프로세스에서 순차적으로 작업을 해나가는것 으로 배웠다. 하지만 실무 또는 OS, Computer System 을 배우다 보면 MultiThreading 또는 MultiProcessing 이라는 이야기를 많이 한다. 그러면 일단 Process 와 Thread 의 개념을 알아야한다.
Process vs Thread
Process 라는건 OS 에서 작성한 프로그램을 실행시키는 단위라고 보면 되고, 하나의 Process 에서 여러개의 Thread 를 관리할수 있다라는것이다. 즉, 간단하게 말해서, 우리가 운동하기, 저녁먹기, 청소하기 이런것들이 Process 개념이며, 하나 운동이라는 Task 를 주어졌을때, Gym 을 가기 또는 저녁 반찬 준비하기가 Thread 라고 할수 있다.
MultiProcessing vs MultiThreading
Multiprocessing 같은 경우, 하나의 Program 을 만들고, 그 프로그램이 여러개의 Thread 를 만들어서, 여러개의 코어를 동시에 활용해서 효율성을 높이는 작업이며, Multithreading 은 하나의 CPU 에 여러개의 코어가 들어있는 경우, 그 코어들을 활용해서 동시에 여러가지 작업을 수행하는것이라고 생각하면 편하다.
단편적으로 multithreading 은 보편적으로 대세라고 보면되고, multiprocessing 같은 경우에는 여러개의 PC 들을 네트워크로 연결시켜서, 그 여러개의 PC 에 들어있는 코어를 전부 활용하는 Distributed Computing 이라고 본다. Multiprocessing 의 단점이라고 말을 할수 있는건 네트워크로 연결된 Phsycially 하게 멀어져있는 Computer 가 흩어져 있기때문에 하나의 PC 가 다른 PC 에 어떤 데이터를 가지고 있는지가 알수가 없다. 하지만 Multithread 는 여러개의 Thread 가 Memory 를 공유한다는 점에서는 장점이다. 이게 양날의 검일수도 있고 정말 잘사용하면 효율이 잘나온다.
Multithreading
위의 그림을 보면 Thread 1 이 시작이되고, 그 다음으로 Thread 2, 3 이렇게 시작된다 어떻게 보면 순차적으로 일어나는것과 같아보이지만, 개념상으로 어떤 Thread 가 먼저 끝낼지는 모르고, thread 3 개를 동시에 띄운다라고 생각하면 되고, 하나하나 Thread 를 실행시킨다고 하면된다. 즉 Main Thread 로 부터 시작해서, Thread 1, 2, 3 이라는 자식 Thread 를 만들어서 어떤 3000 작업을 한다고 하면 1000 개씩 각 3 개의 Thread 에게 일을 시키면된다. 아마 Ctrl + Alt + Delete 를 누르다보면, Task Manager 에서 Performance 를 가다보면 Core 개수를 확인 할수 있을거다.
C++ Thread Basics
바로 코드로 넘어가보자, 아마 이런 코드를 한번 실행시키면 굉장히 좋은 질문일것 같다. Thread 를 생성하고, while 문으로 돌린다. 근데 끝나 버린다. 이 이유 같은 경우 Main Thread 에서 Child Thread 를 만들었는데 (ID 는 모름) 근데 Main Thread 가 끝나 버린 케이스이다. 그걸 위해서는 t1.join() 이게 필요하다.
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
#include <vector>
#include <mutex>
using namespace std;
int main()
{
const int num_process = std::thread::hardware_concurrency();
std::thread t1 = std::thread([]() {while(true) {}});
}
만약의 위의 코드를 Debugging 용도로 사용하려면, 아래와 방식의 코드로 ID 를 Checking 할수 있다.
using namespace std;
int main()
{
const int num_process = std::thread::hardware_concurrency();
cout << std::this_thread::get_id() << endl;
std::thread t1 = std::thread([]() { std::this_thread::get_id() << endl; while(true) {}});
t1.join();
}
그 이후 간단하게 여러개의 Thread 를 만들어서, join() 을 시켜보자.
using namespace std;
int main()
{
const int num_process = std::thread::hardware_concurrency(); // number of core
cout << std::this_thread::get_id() << endl; // main thread
vector<std::thread> my_threads;
my_threads.resize(num_process);
for (auto& e : my_threads)
{
e = std::thread([]() {
cout << std::this_thread::get_id() << endl;
while (true) {}});
}
for (auto& e : my_threads)
{
e.join();
}
return 0;
}
이런식으로 하였을때 보면, threadID 들이 고르지 않게 나온다. 그 이유는 여러개의 Thread 가 동시에 Spawn 이 되고, 그리고 CPU 가 열심히 일하는것을 볼수 있다. 그렇다면 아래와 같이 Lambda 함수로 간단하게 만들어보자
intmain(){autowork_func=[](conststring&name){for(inti=0;i<5;++i){std::this_thread::sleep_for(std::chrono::milliseconds(100));cout<<name<<" "<<std::this_thread::get_id()<<" is working "<<i<<endl;}};std::threadt1=std::thread(work_func,"Jack");std::threadt2=std::thread(work_func,"Nick");t1.join();t2.join();}
이걸 Output 으로 보자면, 이것도 마찬가지로 ID 가 고르지 않을수 있다. 하지만 여기에서는, 실제 work_func 라는 lambda 함수를 사용해서 thread 를 binding 시켜서 실행하는 예제라고 보면 굉장히 쉽게 와다을수 있다. 그렇다면 어떻게 고르게, 우리가 PrintOut 할까가 문제이다. 사실 std::cout 은 t1 과 t2 가 공용으로 접근을 하려고 하기때문에, Race Condition 이 일어나서 서로 std::cout 을 하려고 난리를 칠것이다. 이것을 방지 할수 있는것이 바로 std::mutex => mutex 즉 mutual exclusive, 상호 배제라는 뜻이다. 즉 서로 못 건드리게 한다 바꿔 말하면 이건 내꺼 나만 쓸수 있어 하는 이렇게 선언을 할수 있는 존재이다. mutex 를 걸어주고, cout 그 부분에만 mtx.lock() 과 데이터의 사용을 마무리 짖는 mtx.unlock() 을 아래와 같이해주면 하나의 thread 가 일이 cout 이 끝나고 다른 Thread 가 잡아서 작업을 할수 있게 한다.
usingnamespacestd;mutexmtx;// mutual exclusionintmain(){std::vector<float>myArr;myArr.resize(10);constintnum_process=std::thread::hardware_concurrency();// number of coreautowork_func=[](conststring&name,std::vector<float>&myArr){for(inti=0;i<5;++i){std::this_thread::sleep_for(std::chrono::milliseconds(100));// Don't touch itmtx.lock();myArr.push_back(i);cout<<name<<" "<<std::this_thread::get_id()<<" is working "<<i<<endl;mtx.unlock();}};std::threadt1=std::thread(work_func,"JackJack",std::ref(myArr));std::threadt2=std::thread(work_func,"DashDash",std::ref(myArr));t1.join();t2.join();for(inti=0;i<myArr.size();i++){cout<<myArr[i]<<endl;}return0;}
이런식으로 하면, 기본적인 std::thread 에 관련된 내용을 커버했다. 뭐든지 직접해보고 손대보고 알아나가야 진정한 공부고, 기술이다.
Race Condition
잠깐 아래와 같은 예제를 보자. 예제로 shared_memory 라는 int 타입이라는 메모리를 공유한다고 하자. 일단 실행시킨다고 가정을 한다면, shared_memory 는 1000 이 되어있을거다.
그렇다면, 여러개의 Thread 를 동시에 시킨다고 하자. 그렇다면, shared_memory 가 2000 이 되어야하지만, 그렇지 않다. 그 원인은 일단 CPU 에서 shared_memory 값을 읽어서, CPU 안에서 값을 하나 더하고 그 더해진 결과 값을 shared_memory 변수로 다시 보내는데 t1 이 10 값을 읽어드렸을 사이에 t2 가 재빨리 11 로 값을 바꾼다거나 그러다가 t1 이 다시 12 를 덮어 씌어버리기때문에 덧셈 하나가 사라진거나 마찬가지이다. 즉 동시에 카운트 역활을 주어졌을때, 일은 수행하지만, 같을 덮어씌운다는 점에서 덧셈 몇개까 빠져버린것처럼 보이기 때문이다.
그래서 위처럼 할때, 정확히 shared_memory 가 2000 이나온걸 확인 할 수 있다. 하지만, Atomic Operation 이 느려질수도 있으니 그거에 주의를 두고 사용할때만 사용하자. 우리가 위에서 봤던 예제처럼 std::mutex 를 선언한 이후에, Operation(덧셈) 에 lock() 과 unlock() 을 걸어준다면, 사실 문제는 없다. 근데 프로그래머도 실수는 할수 있으므로 그걸 사용한 std::lock_guard 가 있다. 또 std17 에서는 std::scoped_lock() 을 사용하면 된다.
주의할 점은 this_thread::sleep_for(chrono::milliseconds(1)) 이 부분을 지운다고 하면, 동작을 제대로 할수 있다. 그 이유로는 일단 t1 이 다 더해버리고, t2 가 더할시점에서, t1 이 그냥 다 더하기 때문에 실제로는 두개가 처리가 안됬을수도 있기때문에 병렬처럼 처리한것 처럼 보일수 있다.
Task (작업) 기반 Asynchronous Programming
위에서 봤던 내용 처럼, Thread 로 어떠한 작업을 functor 또는 Lambda 함수로 지정해서 Task 를 parallel 하게 수행할수 있었다. 다른 방법으로는 어떤 Task 기반으로 되는 future, std::async() 를 사용하는 방법이다. Thread 와 비슷하게 사용할수 있지만, 조금 다르게 작동한다는걸 확인 해야하고, 공식 문서에도 이 방법이 선호되고 있는 추세이다. 일단 한번 비교를 하기위해서 두개의 코드를 봐보자.
위의 코드를 확인 하면, Thread 같은 경우 join() 이라는 함수를 통해서, Thread 에서 행해지는 작업을 기다리는거고, async 는 어떤 Task 를 미리 지정해주고, std::future<int> 라는 것을 통해서 값을 받아서, 작업이 끝나면, fut.get() 을 통해서 작업이 끝났다는걸 알수 있다. (즉 .get() 은 어떤 Task 가 있을때까지 기다렸다가 받을수 있는 형태로 되어있다는 소리). 아주 미묘한 차이이지만, Thread 에 t1.join() 이 없더라면 또는 어떤 작업에따라서, main thread 가 죽을수도 있는 현상이 발생할수도 있다. 하지만 그와 반대로 async 는 어떤 특정 작업이 진행해야한다라고 지정한 이후 (미래)에 끝날때까지를 기다리는거다라고 확인해서, 조금 편할수도 있다도 되겠다.
그렇다면 둘중 하나만 써야하냐? 그건 아니다. thread 와 future 를 같이 사용할수 있지만, promise (약속) 을 해야한다. 아래의 코드를 보자면, promise 로 부터 future 를 return 값으로 받는다. 이거 같은 경우는 이 Promise 가 처리가 되서 잘나오는지를 Return 값으로 받기위해서 넣어주고, r-value reference 로 thread 의 lambda 함수에 인자로 넘겨준다. 그리고 이 처리가 잘끝나면, std::move 를 통해서 promise 값이 나와서, future.get() 으로 받을수 있다. 여기서 중요한거는 debugging 을 해보면 처음에는 prom 과 fut 값이 pending 이라는걸 확인 할 수 있다. 즉 아직 값을 받을 준비 또는 처리단계를 거치지 못했다 라고 볼수 있다.
또 여기서 의문점이라고 할수 있는건 std::thread 대신에, 그냥 std::async() 쓰면 되지 않느냐라고 물어 볼수 있는데, 또 다르게 생각해보면, 그렇게 된다면, promise 를 애초에 쓸필요가 없어진다.
여러개를 Thread 를 이용했던것처럼, std::async() 도 여러개를 사용할수 있다. 아래의 코드를 한번 봐보자. 아래의 코드를 수행시에는 main 이 시작되고, async1 이 먼저 시작이되고 그이후에 async2 가 시작된다. 근데 sleep 조건으로 인해서 async2 가 끝나고 async1 이 끝나게 되어있다. 이러면 일단 Parallel 하게 작업한다는걸 짐작할수 있다.
만약에 return 값을 지정을 안한다고 하면 어떻게 될까? 그렇다면, async1 start 가 print 가 되고 async1 end 그다음에 async2 start, async2 end 그 이후에 main 이 작동된다.
그리고 만약에 이 예제를 thread 로 바꾸고 thread 로 바꾸면, 우리의 기댓값과는 다르게 작동이 된다. 이걸 통해서, async 와 thread 의 방식이 다르다는 점과 조심해야할 점을 생각할수 있다.
위의 코드를 보면 일단 main 함수의 2번째 줄은 function call 을 하는게 보인다. 하지만 inline 이라는 키워드를 쓰게 되면 구현부를 구지 function call 하지 않고, 바로 함수의 능력을 바로쓸수 있다는 장점이 있다. 하지만 inline 을 물론 다 함수에 붙여놓으면 이상하고, 그런다고 성능이 좋아지지는 않는다. 왜냐하면 compiler 해결하는 속도는 계속 증가하다보니까, inline 을 쓰든 안쓰든 성능 보장이 없다.
여기에서는 C++11, C++14, and C++17 에대해서 게임 개발에 필요한것부터 정리 하겠다. 아래의 목록과 같이 설명을 하고, 더 설명이 필요한 부분이 있다면, 아래에 더 섹션을 추가할 예정이다.
Auto
C++ 에서는 variable 앞에 항상 타입이 있었다. 예를 들어서, 함수의 인자 타입을 제약조건에서 벗어나려면, template 을 사용해서 하는 방법이 있었다. 하지만, 뭔가 파이썬 처럼 자동 추론 해주는 키워드가 있을까? 생각이든다. 정답은 있다. 일종의 조커 카드 키워드 인 auto 라는 키워드가 있다. 즉 이 키워드가 하는 역활은 compiler 에게 type deduction 을 부탁하는거다. (알아서 잘 맞춰봐 라는 명령을 날리는것 하고 똑같다.) 하지만, compiler 에게 맡기는건 항상 언제나 문제를 일으킨다. 예를들어서, 참조나 포인터 값을 추론 하라고 한다고 하면, 또한 const 를 사용한다면 어떻게 될까? 라는 질문을 할수 있다. 물론 auto 가 주는 편의한 점도 있다. 하지만 이것을 무분별하게 사용한다면 readability 또 떨어지지만, 진짜 진짜 타이핑이 길어지는 경우는 지양해야한다. 예를 들어서, loop 에 iterator 를 정의할때는 지향한다.
Brace {} Initialization
그다음은 brace {} Intialization 이다. 최신 OpenSource 를 보다보면 {} 이런식으로 사용하는걸 볼수 있다. 일단 variable initialization 을 보자. 처음에 int a = 10; 기존에는 이렇게 Initialization 을 했었다. 하지만 또 다른 방법은, 그 아래와 같이 {} b 와 c 를 0 으로 initialize 한걸 볼수 있다. 또 확인을 해보면 vector 등 container 초기화랑 되게 잘어울린다는걸 확인 할 수 잇다. 그리고 중괄호의 초기화 같은 경우, 축소 반환 방지라는게 있다. 이 말은 type conversion 이 깐깐해진다.
아래에서 또 intializer_list 라는게 있는데 만약 list 로 받는다고 가정을 할때, 만약에 생성자에 인자를 두개나 세개만 받는게 있다고 하면 initializer_list 의 생성자가 호출이 된다. 즉, 우선권을 얻어버린다.
#include<iostream>
#include<vector>usingnamespacestd;classKnight{public:Knight(){}Knight(inta,intb){}Knight(initializer_list<int>li)// 초기화할때 리스트{cout<<"Knight(Initialize List)"<<endl;}}intmain(){inta=10;intb{0};// int b(0);intc{0};// int c(0):Knightk1;Knightk2=k1// 복사 생성자 (대입 연산자)Knightk3{k2};// Knight 초기화vector<int>v1{1,2,3,4};// vector 초기화 1, 2, 3, 4 push_backintx=0;doubley{x};// errorKnightk4{};// 기본생성자Knightk5{1,2,3,4,5};return0;}
결론을 내자면 괄호 초기화할때 () 기본으로 간다, 뭔가 모던함을 보여주려면 {} 사용해도 된다. 근데 주로 vector 같은 경우에는 {} 초기화해도 된다.
nullptr
C 코드나 C style 인 C++ 코드에서 보면 NULL 을 종종 볼수 있을거다. 실제 이 값을 보면 0 이라는 값을 가지고 있다. 에를 들어서, #define NULL 0 이렇게 선언이 되어있어서 사용되었었다. 그런데 문제점은 만약 함수에서 정수 인자로 받는것과 pointer 로 받는게 있다고 하면 Null로 넘겨주면 정수인자로 받는 함수만 사용된다. 그래서 nullptr 의 자주 사용되며, 장점이된다. 도대체 그럼 nullptr 은 더 객체같은 존재다. 아래의 코드는 간단한 nullptr 의 구현부이다.
보너스 : 선언하자마자 객체를 만들고 싶다면 class 뒤에, instantiate 하고 싶은 name 을 주면 된다.
classNullPtr{public:// 그 어떤 타입의 포인터와도 치환 가능template<typenameT>operatorT*()const{return0;}// 그 어떤 타입의 멤버 포인터와도 치환 가능template<typenameC,typenameT>operatorTC::*()const{return0;}voidoperator&()=delete;// 주소갑 & 을 막는다.};
using
전에는 typedef 를 사용했던 이유는 뭔가 type 이름이 길어졌을때, 다른 이름으로 만든다음에 설정을 해주었었다. 사실 modern c++ 에서 using 을 사용하는게 결국은 typedef 랑 같다. 근데 사용하는 방법의 차이점을 알고 사용하면 굉장히 괜찮은 코드가 나올것이 분명하다. 한번 사용해보는 코드를 봐보자. 일단 using 을 사용함으로써 되게 가독성이 올라간다. 그리고 제일 중요한건 template 의 사용이다. typedef 는 template 을 사용할수 없다.
enum 은 너무 친숙하지만, modern c++ 에서는 살짝 나누어져있다. 일단 enum class 의 장점을 알아보자.
이름 공간 관리 (scoped)
암묵적인 변환 금지
일단 아래와 같이 봤을때, 만약 enum 값들 중에 같은값을 가지고 있으면, 재정의가 필요하다고 에러창을 보여지는걸 볼수 있다. 그래서 이게 전의 enum 의 단점이다. 보너스: enum 의 Type 을 지정이 가능하다. 그래서 enum class 를 사용해서 enum 의 범위를 지정시켜줘서, 똑같은 element 가 enum 에 있다고 한들 문제가 없어진다.
어? 설마 동적 할당에 대한 delete 였나? 라고 생각할수 있지만, 그런 keyword 가 아니다. 가끔씩은 compiler 에게 기본적으로 만들어진 생성자나 복사생성자를 부를때가 있다. 그럴때 뭔가 막고자 할때 그 함수를 없앤다가 더 말이 맞다. 과거의 코드를 한번 봐보자
classKnight{public:private:// 정의도지 않은 비공개 (private) 함수 --> 하지만 구현부에서는 돌아갈수있다. 그래서 완벽하게 막는 행위는 아니다.voidoperator=(constKnight&k);friendclassAdmin;// admin 에게는 허락 해주겠다.private:int_hp=100;}classAdmin{public:voidCopyKnight(constKnight&k){}}intmain(){Knightk1;Knightk2;// 복사 연산자k1=k2;return0;}
과연 modern c++ 에서는 이걸 어떻게 해결했을까?
classKnight{public:voidoperator=(constKnight&k)=delete}classAdmin{public:voidCopyKnight(constKnight&k){}}intmain(){Knightk1;Knightk2;// 복사 연산자k1=k2;// delete 되버림return0;}
override and final
c# 에서 뭔가 친숙한 keyword 이지만, c++ 에서 어떻게 사용됬는지 한번 확인을 해보자.
classCreature{public:};classPlayer:publicCreature{public:virtualvoidAttack(){cout<<"Player Attack"<<endl;}};classKnight:publicPlayer{public:virtualvoidAttack()override{cout<<"Kngiht"<<endl;}virtualvoidAttack()const// member 변수를 변경 할수 없음private:int_stamina=100;};classPet:publicKnight{public:virtualvoidAttack()final// 마지막 봉인 : 자식에게 그만 주겠당{cout<<"Pet"<<endl;}};intmain(){Player*player=newKnight();player->Attack();return0;}
rvalue
c++11 에서 제일 혁신적인 변화를 일으켰던 친구 중에 하나가 rvalue 이다. 즉 오른값과 std::move 이다. 왼값(lvalue) 와 오른값(rvalue) 에 대해서 알아보자. lvalue 란 단일식을 넘어서 계속 지속되는 개체 그리고 rvalue 는 lvalue 가 아닌 나머지 (임시 값, 열거형, 람다 i++ 등) 있다.
아래를 보면 a 는 왼값이고, 3 은 오른값이다. 왼값은 다시 사용해서 다른 오른값으로 대체 가능하지만, 오른값과 왼값을 바꿔서 뜨면 식이 수정할수 없는 왼값이라는 에러가 뜬다.
intmain(){inta=3;a=4;// 3 = a; Error : 식이 수정할수 없는 왼값이어야 된다. }
아래의 코드를 잠깐 봐보자. 우리가 일반적으로 함수에다가 객체를 pas_by_value 로 했을때는 객체가 복사가 이루어져서 원본 데이터가 변경되지 않는다. 그래서 원본 데이터를 수정하려면 reference 로 인자를 바꿔서 보내줬었다. 즉 k1 은 왼쪽값을 넘겨줘서 바꿔줬었다. 하지만 만약에 대표적인 오른값인 Knight() 를 넘겼다고 가정하자. 그러면 임시의 객체를 생성해서 넘겨주는건데, 오른값이라 허용이 되지 않는걸 확인할수 있다. 하지만, 읽기 용도로는 const 를 사용해서 할수 있다. 하지만 const 를 사용시에는 Knight 의 멤버함수나 멤버변수를 변경 못한다는 점에서 문제가 있다. 그러면 이걸 해결할수 있는 방법이 뭘까? 하면 오른값참조를 허용하게 하는 && 이다.
그럼 왜 구지 이걸 활용해야될까? 일단 RValue 같은 경우 원본 수정도 다해도되고, 함수가 다사용할때 사라지니까 마음대로 해! 라는 느낌이다. 즉 이게 이동 대상이 된다.
classKnight{public:int_hp=100;};voidTestKnight_LValueRef(Knight&knight){knight._hp=200}voidTestKnight_ConstLValueRef(constKnight&knight){}// 하지만 멤버 변수나 method 를 사용할수 없다. 원본 수정 No No...voidTestKnight_RValueRef(Knight&&knight){}// 오른값을 받는 특별한 아이를 지정. 이동대상!intmain(){Knightk1;TestKnight_LValueRef(k1);TestKnight_LValueRef(Knight());// 오른값으로 넘겨 줬을때는 Ref 로 넘길수 없다.TestKnight_ConstLValueRef(Knight());// 허용 --> Knight() 가 잠시 사용하다가 없어질수 있지만, 읽기 용도로 쓰일수 있음TestKnight_RValueRef(k1);// 왼값을 허용이 안된다.TestKnight_RValueRef(Knight());TestKnight_RValueRef(static_cast<Knight&&>(k1));}
만약 객체가 커졌더라면, 이게 어뗘한 이점이 있는지 확인을 해보자.
classPet{};classKnight{public:Knight(){cout<<"Knight()"<<endl;}Knight(constKnight&knight){cout<<"const Knight"<<endl;}~Knight(){if(_pet)delete_pet;}// 이동 생성자Knight(Knight&&knight);voidoperator=(constKnight&knight){cout<<"operator=(const Knight&)"<<endl;_hp=knight._hp;if(knight._pet)_pet=newPet(*knight._pet);}// 이동 대입 연산자voidoperator=(Knight&&knight)noexcept{// 소유권을 넘겨버림cout<<"operator=(Knight&&) "<<endl;_hp=knight._hp;_pet=knight._pet;knight._pet=nullptr;}public:int_hp=100;Pet*_pet=nullptr;};intmain(){Knightk2;k2._pet=newPet();k2._hp=1000;Knightk3;k3=static_cast<Knight&&>(k2);// k2 는 버리고 k3 에서 k2 의 pet 을 뺐어온다. 원본은 날려도 된다. 즉 이동 가능!k4=std::move(k3);// 오른쪽값 참조로 캐스팅 ---> static_cast<Knight&&>(k3); 이러면 k3 를 버리고 k4 가 소유권을 얕복으로 가져std::unique_ptr<Knight>uptr=std::make_unique<Knight>();// 세상에 하나만 존재std::unique_ptr<Knight>uptr2=uptr;// 복사 Xstd::unique_ptr<Knight>uptr2=std::move(uptr);// 이렇게 이용return0;}
forwarding reference
Forwarding Reference 는 C++17 에서 나왔다. 오른값참조와 조금 비슷하다. 근데 주의할점은 무조건 && 이 오른쪽 참조라고 생각을 하면 안된다. 일단 오른쪽 참조값을 할수 있는 이동생성자가 만들어졌고, 그리고 오른쪽 참조값을 받는 함수도 보인다. 하지만 template 이 들어있는 함수를 봐보면, 뭔가 오른쪽 참조값도 되고 왼쪽 참조값도 들어가지는걸 볼수 있다. 또한 auto 를 사용했을때도 오른값참조가 아닌 왼값참조로 되어있고, 또 std::move 를 사용해서 오른쪽값으로 참조로 넘겨준 값을 줬을때, 오른쪽값으로 되어있다는걸 볼수있다. 이 케이스가 바로 forwarding reference 인데, 특이한 케이스 즉 type deduction 을 할시에 생겨날때 주로 일어난다. 즉 카멜레온 같은존재이다. 근데 예외상황은 있다 template 을 사용한다고 해서 다 전달 참조가 아니라 만약 Test_ForwardingRef 함수앞에 인자로 const 가 들고 있게 되면(즉 읽기 전용) 왼값이 에러가 난다. 바로 오른값만 된다.
classKnight{public:Knight(){cout<<"Default Constructor"<<endl;}Knight(constKnight&knight){cout<<"const Knight& knight"<<endl;}Knight(Knight&&)noexcept{cout<<"Move Constructor"<<endl;}~Knight(){cout<<"~Knight"<<endl;}};voidTest_RValueRef(Knight&&k){}voidTest_Copy(Knightk){}template<typenameT>voidTest_ForwardingRef(T&¶m){Test_Copy(std::forward<T>(param));}intmain(){Knightk1;Test_RValueRef(std::move(k1));Test_ForwardingRef(std::move(k1));Test_ForwardingRef(k1);// 경우에따라서 왼쪽 참조가 될수도 있고 오른쪽 참조가 될수도 있다.auto&&k2=k1;// 참조는 참조인데 오른값이 아니다. 왼값참조로 되어있다!?auto&&k3=std::move(k1);// 일반적일때는 사용되지 않지만, type deduction 할때 일어난다. 전달참조가 일어난다.return0;}
즉 전달 참조를 구별하는 방법을 알아보았다. 만약에 입력값이 오른값인지 왼값인지 모를때는 구별하는 방법이 필요하다. 만약에 왼값을 std::move 를 사용하면 모든 소유권을 다 뺏는다는 소리니까 굉장히 좋지 않다. 오른값은 왼값이 아니고, 단일식에서 벗어나면 사용하지 못하고, 오른값참조는 오른값만 참조할 수 있는 참조 타입이였다. 아래를 구체적으로 보면 왼값이다.
일단 함수 객체를 빠르게 만드는 문법이다. 새로 추가된 문법은 아니지만, struct 를 사용하지 않고 한줄로 함수를 구현할수 있다는 점에서는 정말 좋다. python 에서는 익명함수라고도 한다. 그리고 람다에 의해 만들어진 실행시점의 객체를 closure 라고 불린다. 그리고 함수 객체 내부에 변수를 저장하는 개념과 유사한걸 capture 라고 불린다. capture 에 대해서는 생각을 해보면 스냅샷을 찍는것과 마찬가지이다. 캡처에도 모드가 존재하는데, 기본 방식은 복사방식(=), 참조 방식(&) 이다. 그리고 변수 마다 캡처모드를 지정해서 사용가능한데, 이게 더 가독성이 높고, 전체의 인자를 = 또는 & 를 하는건 지양한다.
enumclassItemType{None,Armor,Weapon,Jewelry,Consumable,}enumclassRarity{Common,Rare,Unique};classItem{public:Item(){}Item(intitemId,Rarityrarity,ItemTypetype):_itemId(itemId),_rarity(Rarity),_type(type){}public:int_itemId;Rarity_rarity=Rarity::Common;ItemType_type=ItemType::None;}intmain(){vector<Item>v;v.push_back(Item(1,Rarity::Common,ItemType::Weapon));v.push_back(Item(2,Rarity::Common,ItemType::Armor));v.push_back(Item(3,Rarity::Rare,ItemType::Jewelry));v.push_back(Item(4,Rarity::Unique,ItemType::Weapon));// lambda = 함수 객체를 손쉽게 만드는 문법{// [](인자) {구현부} 기본 형식 --> lambda expressionautoisUniqueLambda=[](Item&item){returnitem._rarity==Rarity::Unique;}autofindIt=std::find_if(v.begin(),v.end(),isUniqueLambda)if(findIt!=v.end())cout<<"Item Id:"findIt->_itemId<<endl;}{intitemId=4;autofindByItemLambda=[=](Item&item){returnitem._itemid==_itemId;};itemId=10;autofindByItemLambda=[&](Item&item){returnitem._itemid==_itemId;};// 10 으로 바뀌었다.}{intitemId=4;Rarityrarity=Rarity::Unique;ItemTypetype=ItemType::Weapon;autofindByItem=[=](Item&item){returnitem._itemId==itemId&&item._rarity==rarity&&item._type==type;}autofindByItem=[itemId,rarity,type](Item&item){returnitem._itemId==itemId&&item._rarity==rarity&&item._type==type;}}{// bug-caseclassKnight{public:voidResetHpJob(){// auto f = [this](){} --> [=](){}// {// this->_hp = 200;// } // 버그returnf;}public:int_hp=100;}Knight*k=newKnight();autojob=k->RequestHpJob();deletek;job();}}
smart pointer
smart pointer 포인터가 똑똑하다? C++ 의 장점이자 단점은 Memory 를 직접 건든다는거다. 하지만 단점중에 알아볼건 바로 dangling pointer 이다. 잠깐 살펴보자. 아래의 코드를 보자면, 뭔가 Knight 에 대한 세팅을 다해줬는데, _target 을 지워버린 셈이다. 이럴때 문제가 바로 crash 가 일어나지 않고, _target->_hp 에 쓰레기 값이 들어가 있는걸 볼수 있다. 즉 _target 에 참조하고 있는애들을 다 nullptr 로 바꿔줘야한다.
조금은 성능면에서 raw pointer 를 사용하기보다는, 코드의 안정성을 위한 코드가 필요해서 smart pointer 가 생겼다. 스마트 포인터란 포인터를 알맞는 정책에 따라 관리하는 객체 (포인터를 래핑해서 사용) 되었다. smart pointer 안에 종류는 아래와 같다
shared_ptr
weak_ptr
unique_ptr
smart pointer 안에서는, python 이나 c# 에서 Garbage Collector 에서 사용되는 reference count 를 해준다. 즉 아무도 사용하지 않을때, delete 를 해준다. 여기에서 중요한점은 RefCount = 1 로 세팅이 되어있고, 소멸할때는 0 으로 만들어준다음, 0 일때 지워주는게 보인다. (즉 refCount 를 확인하고 지워준다는게 특징이다.) 아래의 코드는 shared_ptr 이 어떻게 동작하는지를 확인할수있다.
classRefCountBlock{public:int_refCount=1;// 기본 값은 1. };template<typenameT>classSharedPtr{public:SharedPtr(){}SharedPtr(T*ptr):_ptr(ptr){if(_ptr!=nullptr){_block=newRefCountBlock();cout<<"RefCount : "<<_block->_refCount<<endl;}}SharedPtr(constSharedPtr&shared_ptr):_ptr(shared_ptr._ptr),_block(shared_ptr._block){if(_ptr!=nullptr){_block->_refCount++;}}~SharedPtr(){if(_ptr!=nullptr){_block->_refCount--;// delete _ptrif(_block->_refCount==0){delete_ptr;delete_block;}}}voidoperator=(constSharedPtr&shared_ptr){_ptr=shared_ptr._ptr;_block=shared_ptr._block;}public:T*_ptr=nullptr;RefCountBlock*_block=nullptr;};intmain(){SharedPtr<Knight>k1(newKnight());SharedPtr<Knight>k2=k1;SharedPtr<Knight>k3;{SharedPtr<Knight>k4(newKnight());k4=k1;}}
아래의 코드는 shared_ptr 를 직접 사용한 코드이다.
classKnight{public:Knight(){}~Knight(){}voidAttack(){if(_target){_target->_hp=_damage;cout<<"Hp:"<<_target->_hp<<endl;}}public:int_hp=100;int_damage=10;shared_ptr<Knight>_target=nullptr;}intmain(){shared_ptr<Knight>k1=make_shared<Knight>();// 빨리 동작{shared_ptr<Knight>k2=make_shared<Knight>();k1->_target=k2;}k1->Atttack();return0;}
하지만 shared_ptr 를 사용한다고 하더라도, 포인터의 똑같은 문제점인 순환구조에서는 refCount 가 0 이 되지 않아서, 큰문제가 있을거다. 아래의 예제 code segment 를 봐보자. 아래의 경우 k1 에서의 refCount 는 2 이고, k2 에서의 refCount 가 1 이기때문에 아무도 delete 를 안할것이다. 그래서, 순환구조로 있을때는 따로 nullptr 로 풀어줘야한다.
또다른 방법은 weak_ptr 를 사용한다. weak_ptr 를 사용함에따라서, ReferenceBlock 에는 또다른 _weakCount 라는게 생긴다. shared_pointer 와 달리, weak_ptr 같은 경우는 메모리가 날라갔는지 안날라갔는지 확인이 가능하다. 그래서 .expred() 를 사용해서 날라갔는지 안날라갔는지를 통해서, 그 ptr 를 lock 을 할수 있다. 즉 weak_ptr 는 생명주기를 확인할수 없다. 즉 shared_ptr 과 weak_ptr 차이점은 메모리의 한정 범위에서 자유로워지냐, 생명주기를 확인할수 있냐 등이 있다.
STL 는 Standard Template Library 라고 한다. 즉 프로그래밍 할때 필요한 자료구조 및 알고리즘등을 템플릿으로 제공하는 라이브러리이다. 일단 STL 라이브러리에 뭐가 있는지 알아보자. 첫번째는 Container 이다. Container 같은 경우 데이터를 저장하는 객체, 즉 하나의 Data Structure 이다.
Vector
일단 Container 의 종류의 하나인 vector 을 알아보자. 일단 알아볼가지가 몇개가 있다.
vector 의 동작 원리 (size / capacity)
중간 삽입 / 삭제
처음 / 끝 삽입 / 삭제
임의 접근
동적 배열이라고 함은, 뭔가 동적으로 배열으로 커지고, element 를 추가했을때 배열의 사이즈가 동적으로 커지는 현상을 말한다. 반대로 배열을 사용할때의 문제를 기억해보자. 문제점은 바로 배열의 사이즈다. 뭔가 동적으로 커지고 줄어드는게 힘들기때문에 배열의 단점이다. 하지만 동적배열은 고무줄 처럼 커지고 작아진다.
그렇다고 한다고 하면 vector 의 동작 원리는 뭐길래? 이렇게 고무줄 처럼 사이즈가 늘어나고 줄어들수 있을까? 일단은 두가지의 로직이 존재한다.
(여유분을 두고) 메모리를 할당한다.
여유분까지 꽉 찼으면, 메모리를 증설 한다.
그렇다면 질문!?
여유분은 얼만큼이 적당할까?
증설을 얼만큼 해야할까?
기존의 데이터를 어떻게 처리할까?
첫번째 질문 같은 경우, 아까 봤던것 처럼 v.size() 를 봤을때 실제 용량이고, v.capacity() 는 여유분을 포함한 용량이다. 아래의 코드를 샐행했을때 vector 의 크기가 변화함에 따라서 capacity 가 1.5 또는 2 배 증가하는게 보인다. 그럼 왜 이게 이렇게 설정이 되어있을까? 만약에 배열이 꽉 차있다고 하면 두배로 증가 시킨다. 예를들어서 처음에 [1 2 3 4 5] 되어있다고 치자, 그러면 2 배 만큼을 증설을 시킬거고 그 다음에는 메모리는 malloc 을 통해서 덧붙여도 되지만, 애초에 2배된걸 memory 를 할당해서 메모리를 1.5 를 만든 다음, 복사를 하는 식이다. 즉 더 넒은 곳으로 이사를 하게 된다. 결국에는 지금 현재 메모리에 들고 있는 1.5 배 또는 2 배를 더 큰걸 옮겨주는 정책이 정해져있는것이다. 만약에 1만큼 증가하면 복사하는 비용이 더더욱 커져서 1.5 배나 2 배로 늘어난다.
그럼 예를들어서 capacity() 처음에 저장할수 있는 방법은 v.reserve(100) 이렇게 하면 처음에 100개로 capacity 가 설정이된다. 그런다면 100 개가 넘어가면 150 으로 변경이된다. 마찬가지로 v.resize() 같은경우는 사이즈를 세팅해주는거다.
만약에 vector 를 clear 했다고 한다고 하면 size 나 capacity 의 변화는 어떻게 될까를 한번 알아보자. 아래의 코드를 실행해보면 capacity 는 그대로 1000 개 이고, size 는 0 으로 확인 할 수 있다. 완벽히 capacity 값을 0 으로 만드는 방법은 v 를 깡통인거에 해주면 같이 size 와 capacity 가 0 이될거다.
그럼 데이터 꺼내기 같은경우는 v.front() 맨처음거를 꺼내오거나, v.back() 맨뒤에거를 꺼내오거나 v.push_back 이 있는것처럼 v.pop_back() 이 있다. 심지어 Initialize 도 가능하다. vector<int> v(1000, 0) 를 할수 있는데 1000 은 v.size() 고 0 은 초기값이다. 그리고 복사도 가능하다.(예: vector<int> v2 = v)
일단 위와 같이 vector 의 동작원리를 알아보았다. 그 다음에 알아봐야될거는 어떻게 vector 안에 있는 element 들을 indexing 할수 있는지를 알아야한다. 이거를 알려면 일단 Iterator(반복자) 의 내용에 대해서 알아야 한다. 일단 iterator 는 pointer 와 유사한 개념이고 Container 의 Element 를 가르키고 다음 또는 이전 원소로 넘어갈수 있다.
아래의 코드를 한번 봐보자. 일단 iterator 와 pointer 의 차이가 없다고 보인다. 하지만 iterator 의 메모리를 까보면 추가적인 정보를 들고 있다는걸 확인 할수 있다. 주사값은 물론이고 내가 어떤 Container 로 들고 있다라는 정보도 있다. iterator 의 찾아들어가면 *() operator 가 있는걸 볼수 있다. 이게 포인터의 값을 들고 오는걸 볼수 있다.
pointer 와 비슷하게 ++-- operator 를 사용할수 있다. 포인터에서의 연산은 그다음 주소(데이터)로 넘어가거나 앞으로가거나였다. 아래의 코드에서 반복자의 처음과 끝을 볼수 있는데, 끝같은경우는 데이터의 마지막 값이 지나고, 쓰레기 값이 들어있다. 즉 유효하지 않은값까지 이다.
iterator 는 뭔가 복잡해 보인다. 그런데 사실 iterator 는 vector 뿐만아니라, 다른컨케이너도 공통적으로 있는 개념이다.
그럼 iterator 에서 어떤 애들이 있을까? 일단 아래의 코드를 한번봐보자. 일단 const_iterator 가 존재한다. 그말은 값을 변경 하지 못한다는 뜻이다. 그리고 역방향도 있는데 reverse_iterator 라는걸로 vector 를 설정해주고, iterating 을 한다.
vector<int>::const_iteratorit=v.begin();*it=100;// const 기 때문에 바꿀수 없다.// 역방향for(vector<int>reverse_iteratorit=v.begin();it!=v.end()++it){cout<<(*it)<<endl;}
다시 돌아가서 이제 vector 의 접근 / 삽입 / 삭제등을 어떻게 활용하는지 보고, 해당되는 performance 를 체크 해보자. 일단 vector 는 container 이기 때문에 하나의 메모리 블록에 연속하게 저장된다. 만약에 예를들어서 중간에 삽입을 한다고 하면, 사이즈가 증가 할때마다 큰곳으로 복사를 해주어야 하는데, 그때의 복사 비용이 커진다. 그리고 삭제 같은 경우, 블록을 하나 사라 진다고 하면, 그래서 중간 삽입 / 삭제가 비효율적이다라는걸 알수 있다. 이 이야기 처럼 처음 삽입 / 삭제도 비효율적이라고 볼수 있다. 하지만 끝 삽입 / 삭제같은 경우는 뒤에것만 지우기때문에 효율적이다. Random Access(임의 접근) 같은 경우도 사실 하나의 메모리 블록에 연속적이다는 특성으로 인해서 임의 접근이 쉽게 된다.
// Init: [0][1][2][3][4]v.insert(v.begin()+2,5);// After: [0][1][5][2][3][4]v.erase(v.begin()+2);// After: [0][1][2][3][4]v.erase(v.begin()+2,v.begin()+4);// After: [0][1][4] 4 는 삭제 되지 않음
실수중에 하나가, 예를 들어서 3 이라는 데이터가 있으면 일괄 삭제하는 케이스가 있다고 하자. 아래의 코드는 그 예제의 케이스다고 볼수 있다, 그리고 이 코드를 돌렸을때, 실패가 났을것이다. 삭제를 했을때, 이때의 iterator 는 container 의 소속이 아니게된다. 그 다음에 it 에서 유효하지 않기 때문에 그다음 loop 에서 실패가 난다. 그래서 v.erase(it) 하면 null 인 상태가 아니라, iterator 다시 받을수있다. 근데 사실이것만 하면 되는게 아니라, iterator 가 그냥 넘어갔다고 하면 3 뒤에 나오는 element 는 스킵을 한다는게 포인트다. 즉 넘어가게끔 else 넘어가게 해주어야한다. 그리고 내부에서 절대 절대 clear() 를 call 하면 안된다.
template<typenameT>classIterator{public:Iterator():_ptr(nullptr){}Iterator(T*ptr):_ptr(ptr){}Iterator&operator++(){_ptr++;return*this;}Iteratoroperator+(constintcount){Iteratortemp=*this;temp._ptr+=count;returntemp;}Iteratoroperator++(int){Iteratortemp=*this;_ptr++;returntemp;}Iterator&operator--(){_ptr++;return*this;}Iteratoroperator--(int){Iteratortemp=*this;_ptr++;returntemp;}booloperator==(constIterator&right){return_ptr==right._ptr;}booloperator!=(constIterator&right){return_ptr!=right._ptr;}T&operator*(){return*_ptr;}public:T*_ptr;};template<typenameT>classVector{public:Vecotr():_data(nullptr),_size(0),_capacity(0){}~Vecotr(){if(_data)delete[]_data;}voidpush_back(constT&val){if(_size==_capacity){intnewCapacity=static_cast<int>(_capacity*1.5);if(newCapacity==_capacity)newCapacity++;reserve(newCapacity);}_data[_size]=val;_size++;}voidreserve(intcapacity){_capacity=capacity;T*newData=newT[_capacity];for(inti=0;i<_size;i++)newData[i]=_data[i];// 기존에 있는 데이터를 날린다.if(_data)delete[]_data;_data=newData;}T&operator[](constintpos){return_data[pos];}// v[i] = i;intsize(){return_size;}intcapacity(){return_capacity;}private:T*_data;int_size;int_capacity;typedefIterator<T>iterator;Iteratorbegin(){returniterator(&data[0]);}Iteratorend(){returnbegin()+_size;}};intmain(){Vector<int>v;for(inti=0;i<100;i++){v.push_back(100);cout<<v.size()<<" "<<v.capacity()<<endl;}for(inti=0;i<v.size();i++){cout<<v[i]<<endl;}for(Vector<int>::iteratorit=v.begin();i!=v.end()++it){cout<<(*it)<<endl;}return0;}
Lists
Vector 와 비슷한 container 의 형식인 List(LinkList) 가 있다. 하지만 List 는 Node 형식으로 되어있다. 즉, 트리 형식으로 만들수 있다는거다. 일단 아래의 코드를 보면, List 에서 대표적으로 유용하게 사용되는게 보인다. 일단 vector 를 비교하면, capacity 가 따로 없다 그 이유는 vector 와달리 Node 형식으로 동작을 한다. 그리고 다른걸 봐보면 push_front 나 pop_front 가 존재한다. 이것도 List 가 Vector 와 다른 형식으로 값을 Contain 하기 때문이다. 마지막으로 random access 가 지원되지 않고, 어떤 element 를 지우는것도 까다롭지 않게 구현이 되어있는걸 볼수 있다.
#include<list>intmain(){list<int>l1;for(inti=0;i<100;i++)l1.push_back(i);li.push_front(10);// vector 와 다르게 동작intsize=l1.size();// // li.capacity() ? // 동적배열인 형식이 아닌 Node 형식으로 동작intfirst=li.front();intlast=li.back();// li[3] = 10; // 임의 접근 안됨list<int>::iteratoritBegin=li.begin();list<int>::iteratoritEnd=li.end();for(list<int>::iteratorit=li.begin();it!=li.end();++it){cout<<(*it)<<endl;}li.insert(itBegin,100);li.erase(li.begin());li.pop_front();li.remove(10);return0;}
위처럼 코드를 잠깐 살펴보았는데, 이제 List 가 어떤 동작 방식을 가지고 있는지 확인을 해보자. 만약 연결리스트의 개념을 알고 있으면, 메모리의 구조를 잘 이해하게 될거다. 일단 연결리스트에 종류가 있는데, 단일, 이중, 원형 LinkList 들로 이루어져있다. 즉 1 -> 2 -> 3 이런식으로 각 각 넘버는 Node 형태로 되어있고, 이 Node 들은 data 를 가지고 있고 그리고 Node 의 주소값을 가지고 있다. 여기서 포인트가 자기 자신의 Node 타입인 아이를 들고 있으면 무한정 Node 안에 Node 가 반복될것이다. 하지만 여기서 봐야될거는 Node 의 포인터 즉 주소값을 가지고 있는게 포인트이기때문에, 그다음의 주소값을 들고 있으면 리스트처럼 들어갈수 있다. 이중리스트 같은 경우는 아래의 Node2 를 보면 된다. Previous 의 주소값과 그다음 주소값을 나타내는게 보인다.
일단 STL 에서는 이중 리스트로 되어있다. 이중리스트가 Node 형식으로 되어있으니까, 중간 삽입 또는 삭제 그리고 처음 / 끝 삽입 또는 삭제가 잘될거라는건 쉽게 믿을수 있다. 하지만 모든게 다 장점을 들고 있었더라면 List 를 많이 썼을거다. 하지만 List 의 단점이 있다. List 의 임의 접근이 쉽지 않다. 그니까 노드 들을 계속 타고 타고 가서 몇번째를 노드에 그 데이터를 가지고 갈수 있다. 그래서 List 에서 성능이 않좋기 때문에, 임의접근의 기능을 지원하지 않는다.
아래의 code segment 를 한번 봐보자. 일단 list 의 앞과 뒤의 주소를 ptrBegin 그리고 ptrEnd 로 저장을 해보자. 그런 다음 데이터의 저장된 Previous 와 Next 의 주소값을 확인하고 그 Node 자신의 데이터 값도 확인을 해보면 잘들어있는게 보인다. 그리고 Link List 에서 맨뒤의 값을 봐보면 Next 가 쓰레기 값으로 들어가있는걸 볼수있다. 이말은 Next 가 쓰레기 값이면 list 의 size 를 알수 있다. 그리고 Link List 이기때문에 궁금할수 있는건 맨마지막에서 빼면 앞으로 가는지, 그리고 뒤에서 맨앞으로 가면 어떻게 되는지 아래의 코드에서 확인 할수 있다. 그래서 LinkList 의 허용범위를 확인 할수 있다.
list<int>iteratoritBegin=li.begin();list<int>iteratoritEnd=li.end();// list<int>::iterator itTest1 = -- itBegin; // 앞에서 맨뒤로 가는건 허용Xlist<int>::iteratoritTest2=--itEnd;// 앞으로 가는건 허용// list<int>::iterator itTest3 = ++itEnd; // 뒤에서 맨 앞으로 가는건 허용Xint*ptrBegin=&(li.front());int*ptrEnd=&(li.end());list<int>::iteratorit2=li.begin()+10;
또 여기에서 의문점이 임의접근이 안되는데 중간 삽입 / 삭제가 빠르다는건 약간의 역설이 들어간다. 이미 삭제된 대상이 정해져 있으면 쉽지만, 그 index 를 가지고 이동해서 삭제하는 어렵다라는걸 알수 있다. 즉 erase 는 빠르게 되지만, 숫가락으로 그 index 까지 찾아줘야하는건 우리의 몫인거다. 그래서 그 다음 아래 코드를 보면, 저렇게 iterator 로 remember 로 받아들인다음에 나중에 삭제할 index 를 찾을수 있는 방법도 있다.
li.erase(li.begin()+50)// 허용 되지 않음list<int>::iteratorit=li.begin();for(inti=0;i<50;i++)++it;li.erase(it);
#include<list>
#include<iostream>usingnamespacestd;template<typenameT>classNode{public:Node():_next(nullptr),_prev(nullptr),_data(T()){}~Node(constT&value):_next(nullptr),_prev(nullptr),_data(value){}public:Node*_next;Node*_prev;T_data;};template<typename>TclassIterator{public:Iterator():_node(nullptr){}Iterator(Node<T>*node):_node(node){}// ++itIterator<T>&operator++(){_node=_node->_next;return*this;}//it++Iterator<T>operator++(int){Iterator<T>temp=*this;_node=_node->_next;returntemp;}// --itIterator<T>&operator++(){_node=_node->_prev;return*this;}// it--Iterator<T>operator++(int){Iterator<T>temp=*this;_node=_node->_prev;returntemp;}T&operator*(){return_node->_data;}booloperator==(constIterator&right){return_node==right._node;}booloperator!=(constIterator&right){return_node!=right.node;}public:Node<T>*_node;}template<typenameT>classList{public:List():_size(0){_header=newNode<T>();_header->_next=_header;_header->_prev=_header;}~List(){while(_size>0)pop_back();delete_header;}voidpush_back(constT&value){AddNode(_header,value);}voidpop_back(){RemoveNode(_header->_prev);}Node<T>*AddNode(Node<T>*before,constT&value){Node<T>*node=newNode<T>(value);Node<T>*prevNode=before->_prev;prevNode->_next=node;node->_prev=prevNode;node->_next=before;before->_prev=node;_size++;returnnode;}Node<T>*RemoveNode(Node<T>*node){Node<T>*_prevNode=node->_prev;Node<T>*_nextNode=node->_next;_prevNode->_next=_nextNode;_nextNode->_prev=_prevNode;deletenode;_size--;returnnextNode;}intsize(){return_size;}public:typedefIterator<T>iterator;iteratorbegin(){returniterator(_header->_next);}// Header in the Last element would be the frist elemiteratorend(){returniterator(_header);}iteratorinsert(iteratorit,constT&value){Node<T>*node=AddNode(it._node,value);returniterator(node);}iteratorerase(iteratorit){Node<T>*node=RemoveNode(it._node);returniterator(node);}public:Node<T>*_header;int_size;};intmain(){list<int>li;list<int>::iteratoreraseIt;for(inti=0;i<10;i++){if(i==5){eraseIt=li.insert(li.end(),i);}else{li.push_back(i);}}li.pop_back();li.erase(eraseIt);for(list<int>::iteratorit=li.begin();it!=li.end(),++it){cout<<(*it)<<end;s}return0;}
Deque
이제 vector 와 list 를 알아 보았다. 이 둘은 sequence container 라고 하는데, 데이터가 넣어지는대로 sequential 하게 넣어지기 때문이다. 우리가 이제 새로배울건 deque, double-ended queue 라고 한다. deque 같은 경우는 vector 와 list 의 사이로 생각하면 된다. 기존에 vector 에서는 배열의 크기를 늘리려면 새로운걸 크게 할당한다음에 복사하는 형태 였다. 하지만 deque 같은 경우는 그 배열 자체를 늘리는게 아닌 새로운 메모리 영역을 이어지게끔 즉 list 형식으로 만들어진다. 결론적으로 vector 와 마찬가지로 배열 기반으로 동작하지만, 메모리 할당하는 방식이 List 와 같다. 아래의 코드를 보면 vector 와 다르게 push_front 를 지원하는걸 볼수 있다.
그렇다고 하면 vector 와 마찬가지로 처음 / 끝 에 대한 삽입 / 삭제가 효율성은 좋고 중간 삽입 삭제가 효율성이 않좋다는걸 확인 할수 있다. 임의 접근 같은 경우는 deque 는 아파트와 같다. deque 에서 F11 를 누르면 확인할 수 있는게, Offset 이라는 친구가 있어서 몇번째 층에 있는지를 확인할수 있고, 거기에 하나씩하나씩 element 를 더하는게 보인다. 즉 offset 과 얼만큼 떨어져있는지를 봐보면 임의 접근은 쉽게 된다는게 장점이다.
Map
Python 과 C# 코드를 보면 Dictionary 라는 타입이 존재 할거다. 바로 Key 와 Value 로 매칭되는식으로 연결되어있는 Hashtable 같은 자료구조이다. c++ 에서도 이런걸 지원하는데 바로 Map 이라는 친구이다. 이 친구는 연관 컨데이너라고도 부른다. 만약에 Python 을 사용해보았더라면, dict 의 indexing 하는 법과 data 를 꺼내오는 방법, 초기 생성등 알것이다. 일단 다시 돌아와서 vector 와 list 의 치명적인 단점으로 꼽자면, 뭔가 아이디에 매칭되는값을 찾으려고 할때 생각보다 코드가 많이 들어간다. 이걸 보완할수 있는게 바로 Map 이다. Map 에서는 균형 이진 트리 (AVL) 로 되어있으니까, 노드 기반을 되어있다. 아래의 첫번째 코드를 봐보면, 한노드에 대한 데이터 구조를 확인 할수 있다.
그렇다면 Map에 대한 예제를 한번 봐보자. 아래와 같이 살펴보자. 일단 Map 에는 key 와 value 의 타입을 설정해줘야되고, key 와 value pair 이기때문에 pair 라는걸 사용해서 m 에 넣어주었다는걸 확인 할수 있다. 그다음에 어떤 아이디를 찾았다고 한다면 erase 를 통해서 삭제가 가능하다. 뭔가 찾을때는 find 라는 걸 사용하면 되는데 이때의 return 타입을 확인해보면 map 에 있는 iterator 라고 확인 할 수 있다. 만약에 find 를 해서 return 값이 map 을 돌다가 끝에 도착하지 않는다고 한다면 그 key 에 매칭되면 찾은거고, end() 에 왔으면 못찾은거다.
여기서 궁금할수 있는거는 insert 와 erase 를 똑같은 키에다가 데이터를 넣었다고 한다면 어떻게 될까라는 질문을 할수 있다. erase 같은경우는 count 를 내뱉는데, 찾아서 지울께 있다면 1 로 내뱉고, 지워졌는데 또 erase 를 하면 0 으로 return 하는데, 이말은 두번호출은 괜찮다는거다. 하지만 insert 같은 경우, 처음 호출하는 insert 만 적용이되고 두번째 호출된 insert 는 되지않는다. 즉 덮어 쓰이지 않는다. 순회하는 부분도 확인 할 수 있는데 key 와 value 값으로 map 은 이루어져있기 때문에, Map 에 있는 iterator 에 first 값은 key 값이고, second 값은 value 로 이루어져있다는 걸 확인 할수 있다.
#include<map>template<typenameT1,typenameT2>structPair{T1t1;T2t2;}intmain(){map<int,int>m;pair<map<int,int>::iterator,bool>ok;// 확인 기능ok=m.insert(make_pair(1,100));ok=m.insert(make_pair(1,200));for(inti=0;i<10000;i++){m.insert(pair<int,int>(i,i*100));}for(inti=0;i<5000;i++){intrandomValue=rand()%5000;m.erase(randomValue);}// find the datamap<int,int>::iteratorfindIt=m.find(1000);if(findIt!=m.end()){cout<<"Found"<<endl;}else{cout<<"Not Found"<<endl;}unsignedintcount=0;count=m.erase(10);count=m.erase(10);// iteration on mapfor(map<int,int>::iteratorit=m.begin();it!=m.end();++it){pair<int,int>&p=(*it);intkey=p.first;// it->firstintvalue=p.second;// it->second}return0;}
이 이후에 확인 해야될거는 map 안에 key / value pair 값이 있느냐 없느냐의 따라서 insert 를 해주는 코드이다. [] operator 사용할시의 유의점이 있는데, 대임을 하지 않더라도 (key/value) 형태의 데이터가 추가 된다. 이때는 강제로 0 으로 initialize 시켜준다.
if(findIt!=m.end()){findIt->second=200;}else{m.insert(make_pair(10000,300));}// 없으면 추가, 있으면 수정m[5]=500;m.clear()for(inti=0;i<10;i++){cout<<m[i]<<endl;}
Set, Multimap, and Multiset
map 의 형제들을 초대하려고 한다. set, multimap, and multiset 이다. set 같은 경우 map 과 달리 단독적으로 key 만 사용하고 싶을때 사용하는 자료구조이다. 아래와 같이 코드를 보면서 set 을 확인 해볼수 있다.
#include<set>intmain(){set<int>s;s.insert(10);s.insert(20);s.insert(30);s.insert(40);s.erase(40);s.erase(30);set<int>::iteratorfindIt=s.find(50);if(findIt!=s.end()){cout<<"found"<<endl;}for(set<int>::iteratorit=s.begin();it!=s.end();++it){cout<<(*it)<<endl;}// s[2] =10 // not allowed}
multimap 과 multiset 같은경우는 동일한 key 값에 대해서 다른 value 가 있을때 사용할수 있는 자료구조인데, 아래의 코드 에서 확인을 해보자. 일단 multimap 같은 경우 경우 map 과 다르게 동일한 key 에 다른 Value 가 들어간거니, 뭔가 혼동을 줄이기위해서 직접 안에 들어가 데이터를 수정하는건 막혀있다. 여기서 질문 할수 있는건, 지울때 key 값을 넘겨줬을때, 그때는 어떤 value 가 들어있든 상관없이, 그 key 에 해당하는 pair 들을 다 삭제한다. 만약에 그럼 특정 value 에 지우고 싶다면 어떻게 할까? 그럴땐 아래와 같이 iterator 를 돌아서 제일 먼저 찾아지는 친구를 지우게끔 할수도 있다.
#include<map>
#include<set>intmain(){multimap<int,int>mm;mm.insert(make_pair(1,100));mm.insett(make_pair(1,200));mm.insett(make_pair(2,200));mm.insett(make_pair(2,500));// mm[1] = 500 // not allowed unsginedintcount=mm.erase(1);multimap<int,int>::iteratoritFind==mm.find(1);if(itFind!=mm.end()){mm.erase(itFind);}pair<multimap<int,int>::iterator,multimap<int,int>::iterator>itPair;itPair=mm.equal_range(1);multimap<int,int>::iteratoritBegin=mm.lower_bound(1);// 1 이나오는 첫 순간multimap<int,int>::iteratoritEnd=mm.upper_bound(1);// 1 이끝나는 마지막for(multimap<int,int>::iteratorit=itPair.first;it!=itpair.second;++it){cout<<it->first<<" "<<it->second<<endl;}for(multimap<int,int>::iteratorit=itBegin;it!=itEnd;++it){cout<<it->first<<" "<<it->second<<endl;}multiset<int>ms;ms.insert(100);ms.insert(100);ms.insert(100);ms.insert(200);ms.insert(200);ms.insert(200);multiset<int>::iteratorfindIt=ms.find(100);pair<multiset<set>::iterator,multiset<int>::iterator>itPair2;itPair2=ms.equal_range(100);for(multiset<int>::iteratorit=itPair2.first;it!=it!=itPair2.second;++it){cout<<(*it)<<endl;}multiset<int>::iteratoritBegin=ms.lower_bound(100);multiset<int>::iteratoritEnd=ms.upper_bound(100);for(multiset<int>::iteratorit=itBegin;it!=itEnd;++it){cout<<(*it)<<endl;}return0;}
Algorithm
이제까지 data sturcutre 를 알아봤다. 사용에 따라서, data 를 어떻게 생성해주고, 선언하는걸 알아보았다. 하지만 여기서 끝나는건 아니다 데이터를 만들었으면 가공도 해야되기때문에 c++ 에서는 algorithm 이라는 라이브러리가 있다. 대표적으로 사용되는 걸 알아보자.
find
find_if
count
count_if
all_of
any_of
none_of
for_each
remove
remove_if
위에서 사용한 method 를 아래와 같이 question 과 구현을 해보았다. 다만 remove 와 remove_if 를 조심하자! 이 둘은 결국 vector 안에서 중간 삭제나 처음 삭제가 일어나는데, 이때 먼저 필요한 데이터만 뽑아와서 복사를 한다음에, 복사 할필요 없는 element 도 복사 하니까, 실제 filtering 이 잘 안되어있을수 있다. 그래서 실제 return 값은 filtering 이 끝나는 위치(iterator)를 return 한다.
#include<algorithm>
#include<vector>intmain(){intnumber=50;// Q1 : Find the element if the number matchesstd::vector<int>::iteratoritFind=std::find(v.begin(),v.end(),number);if(itFind==v.end()){cout<<"not found"<<endl;}else{cout<<"Found"<<endl;}// Q2 : check if the element in vector is divisible by 11.structCanDivideBy11{booloperator()(intn){return(n%11==0);}};std::vector<int>::iteratoritFind=std::find_if(v.begin(),v.end(),CanDvideBy11());if(itFind==v.end()){cout<<"not found"<<endl;}else{cout<<"Found"<<endl;}// Q3 :find how many odd number is in vectorstructisOdd{booloperator()(intn){return(n%2)!=0;}};std::vector<int>::iteratorifFind=std::count_if(v.begin(),v.end(),isOdd())if(itFind==v.end()){cout<<"not found"<<endl;}else{cout<<"Found"<<endl;}// 모든 데이터 홀수?boolb1=std::all_of(v.begin(),v.end(),isOdd());// 홀수인 데이터가 하나라도 있어?boolb2=std::any_of(v.begin(),v.end(),isOdd());// 모든 데이터가 홀수가 아니야?boolb3=std::none_of(v.begin(),v.end(),isOdd());// Q4 multiply three on every elements in a vectorstructMultiplyByThree{booloperator()(int&n){n=n*3;}};std::for_each(v.begin(),v.end(),MultiplyByThree);// Q5 remove all data which is an odd numberv.clear();v.push_back(1);v.push_back(4);v.push_back(5);v.push_back(2);v.push_back(3);vector<int>::iteratorit=std::remove_if(v.begin(),v.end(),IsOdd());v.erase(it,v.end());// v.erase(std::remove_if(v.begin(), v.end(), IsOdd()), v.end());return0;}
함수 선언이나 변수 선언을 할때, 항상 앞에는 타입이 존재했다. return 받을 타입이나, 아니면 이 타입으로 저장한다는 식으로. 그렇다면 함수를 변수로 사용할수 있을까? 의 질문의 시작이 함수 포인터의 시작이다.
일단 함수를 뭔가 변수로 설정하려고 한다면, 함수의 signature 이 중요하다. 일단은 사실상 함수의 이름은 신경 써주지 않는다고하고 아래의 코드를 보면 int(int a, int b) 이런식으로 된다. 근데 어떻게 이름을 줄까? 라는 생각을 해보는데. 이건 typedef 로 생각하면 된다.
그래서 signature 은 typedef int(FUNC_TYPE)(int a, int b) 이런식으로 주면 된다. 하지만 Modern C++ 에서는 더 편한걸로 using 을 사용해서, using FUNC_TYPE = int(int a, int b) 이런식으로 표현이 가능하기도 하다. 그런다음에 FUNC_TYPE* fn 이라고 생성하면 함수의 포인터라고 할수 있다.
아래의 코드를 봐보기전에, 뭔가 함수의 return 값을 봐보면, 함수의 시작 주소가 있다는걸 힌트를 알수 있다. 그 말은 즉슨 포인터를 이용해, 그 함수를 point 하게 둘수 있다는 말이다. 아래와 같이 fn 즉 FUNC_TYPE 의 signature 만 맞으면, 함수를 호출이 가능하다는 소리이다. 그리고 아래의 (*fn) 이 signature 같은 경우는 fn 을 타고 들어가서 (1, 2) 를 넣어준다라고 생각하면 될것 같다.
근데 구지 생각을 해보면, 왜 이렇게 까지 써야되냐? 라는 질문을 할 수 있는데, 그 이유는 함수의 signature 가 동일하게 되면 쉽게 스위칭이 가능하다 라는 말이다. 아래의 코드를 한번 봐보자. Add 를 다 쓴 이후 Sub 으로 바로 스위칭이 가능하다. 어떻게 보면 나머지를 고칠 필요 없이, 강력한 Tool 로 쓸수 있다.
intAdd(inta,intb){returna+b;}intSum(inta,intb){returna-b;}intmain(){typedefint(FUNC_TYPE)(int,int);FUNC_TYPE*fn;fn=Add;// add.. 를 다 쓴이후fn=Sub;// sub 처리}
또 다른 예제를 알아보자. 아래의 Item 클래스를 만들어줬고 Item pointer 를 return 해주는 코드가 있다고 하자. 뭔가 같은 기능을 계속 인자만 바꿔서 주는게 굉장히 코드가 길어지고, 유지 보수가 좋지 않다. 그래서 인자값으로 함수의 안전체크나 조건문들을 넘겨주게 된다면 이 코드의 유지 보수성은 더 올라갈것이다.
그런데, 물론 장점도 있지만 단점도 있다. 아까 계속 언급한 함수의 signature 가 달라진다면 물론 다르게 표현을 해야된다. 아래의 코드를 보면 실패하게 된다 왜냐하면 isOwnerItem 의 signautre 가 아까 IsRareItem 과 다르기 때문이다. 그래서 아래의 코드를 보면 같이 맞춰지게 int 값도 따로 추가해주면 된다. 즉 꼬리의 꼬리물기가 되서, 뭔가 함수의 인자수가 많아져서 좋지 않은 구조가 된다. 즉 결론은 함수도 주소가 있어서 함수포인터를 사용해서 함수의 call 바로 할수 있다.
사실은 블로그를 커버하다가, 한번도 typedef 에 대해 설명을 하지 않았다. typedef 그냥 형태 만 봤을때 typedef [] [] 이런식으로 생겼다. 하지만 봤을때 오른쪽이 커스텀 타입을 정의를 했었다. 근데 이걸 더 정확하게 보면, 선언 문법에서 typedef 를 앞에다 붙이는쪽으로 왔었다. 아래와 같이 선언을 하면, 바로 앞에 typedef 를 붙여지는거다. 그래서 Code Segment 를 봤을때 아래를 보면 함수의 Signature 은 (int, int)의 인자를 받고 int 로 받고, 그다음에 함수의 포인터이기때문에 (*PFUNC) 라는걸 선언을 한거다. 그다음에 typedef 를 넣으면 된다.
그래서 이걸 멤버함수에 속한다라는걸 보여주어야기 때문에 아래의 코드 처럼 하면된다. 아래에 보면, 주소값을 달라는 표시도 해주어야한다. 이건 C 언어의 호환성 때문에 한다.
classKnight{public:// Static FunctionstaticvoidHelloWorld(){}// Member FunctionintGetHP(){return_hp;}int_hp=100;}typedefint(Knight::*MEMBERPFUNC)(int,int);intmain(){PMEMFUNCmfn;mfn=&Knight::GetHp;Knightk1;(k1.*mfn)(1,1);Knight*k2=newKnight();(k2->*mfn)(1,1);deletek2;return0;}
일반적으로 자신과 다른 클래스가 있고 멤버함수가 동일하다고 하더라도, 이미 지정해주었기 때문에, 객체를 바꾸더라도 실행이 안된다는거에 주의하자.
Functor
함수 객체는 함수처럼 동작하는 객체를 뜻하는데, 위와 같이 함수 포인터의 단점이 너무 잘보였었다. 일단 함수의 signature 가 동일한 친구들 만 사용됬었고 다르다고 하다면, 인자를 늘려가야하는 큰단점, 즉 generic 하게 사용하지 못한다는 점이 큰 단점이 였다. 또 다른 큰 단점은 자세하게 debug 하지 않으면 객체의 상태의 유지성을 모른다는거다. 예를 들어서 Knight 의 객체 안에 _hp 라는 field 가 있는데, 함수 포인터 같은 경우는 인자만 넘기지, 그 field 가 뭘하는지, 유지 됬는지 잘모른다는 뜻이다.
함수처럼 동작하는 객체라는게 뭘까라는 걸 알아보자. 일단 함수 처럼 작동하려면 힌트는 () 이런 연산자가 필요하다. () 연산자 오버로딩이 필요하다는거다.
예시로 보여준건 MMO 에서 함수 객체를 사용하는 예시가 있다. 게임은 클라와 서버가 있는데, 서버같은 경우는 클라가 보내준 네트워크 패킷을 받아서 처리하는데 만약에, 클라가 (5,0) 으로 좌표로 이동 시켜줘! 라고 서버한테 요청을 했다고 하자. 실시간 MMO 라고 하면 클라가 정말 많을텐데, 이때 처리할때 사용할수 있다. 이때, Functor 만들어준 시점과 그리고 실제 실행할 시점을 분리 시키는걸 볼수 있다. 아래가 바로 Command Pattern 을 비슷하게 사용해서 Tracking 이 가능할거다.
classMoveTask{public:voidoperator()(){// TODOcout<<"Move"<<endl;}public:int_playerId;int_posX;int_posY;}intmain(){MoveTasktask;task._playerId=100;task._posX=5;task._posY=3;// 나중에 여유될때 일감을 실행task();return0;}
Template Basics
Template 이란 함수나 클래스를 찍어내는 툴이라고 생각하면 된다. 템플릿의 종류는 Function Template 과 Class Template 이 존재한다. 일단 예시같은 경우는 이런거다 여러 다른 타입들을 받는 똑같은 함수가 존재한다고 하자. 다 똑같은 기능을 가지고 있지만 인자값으로 다르게 존재 하는걸 볼수 있다. 이거를 한번에 묶을수 있는 존재가 있을까? 라는 생각이든다. 그게 바로 형식을 틀로 잡을수 있는 template 이 있다. 즉 조커 카드이다.
Template 에 대해서 한번 봐보자. 일단 아래의 코드처럼 typename T 라고 지정해준걸 볼수 있다. 그리고 그 인자의 type 을 Print() 함수에 넣어진걸 확인 할 수 있다. 즉 어떤 타입이 들어오든지 T 로 들어와서 컴파일러가 각각 type 을 정해주는걸로 볼수 있다. 아래 처럼 코드를 실행 해보았을때, 잘 빌드가 성공된걸 볼수 있다. 그리고 맨 아래에 보면 Print 뒤에 <double> 이란게 나와있다. 이거 같은 경우는 컴파일러에 맡기는것보다 내가 이런 형식을 원한다라는걸 강제적으로 줄수도 있다. 이말은 즉슨 컴파일러에게 힌트를 주는거다. 그리고 아래의 Add 함수를 봐보자. 여기에서는 인자가 같을때 즉 (int, int), (double, double), 이런식으로 타입이 같은 인자가 들어왔을때도 줄일수도 있고, return 값으로도 T 를 줄수도 있다. 이 말은 또 각기 다른 타입의 인자를 넣어줄수도 있다. PrintMultiple() 을 참고하자. 그리고 객체의 있는걸 Type 으로 넘겨준다고 하면 실행 되지 않는다. 그 이유는 Knight 라는 클래스는 프로그래머가 만든 커스텀 한 타입이기때문에 지원되지 않아서 ofstream 에 있는걸 가져다가 오버로딩을 해줘야한다.
template<typenameT>voidPrint(Ta){cout<<a<<endl;}template<typenameT>TAdd(Ta,Tb){returna+b;}template<typenameT1,typenameT2>voidPrintMultiple(T1a,T2b){cout<<a<<" "<<b<<endl;}classKnight{public:// ...public:int_hp=100;};// 연산자 오버로딩 (전역함수)ofstream&operator<<(ofstream&os,constKnight&k){os<<k._hp<<endl;returnos;}intmain(){Print(50);Print(50.0f);Print<double>(50.0);ret=Add(2,3);PrintMultiple("Hello",3);Knightk1;Print(k1);// 연산자 오버로딩이 없으면 안됨return0;}
위와 같이 template 은 조커카드였다. 하지만 어떤객체에 대해서 특수 조커 카드를 만들려고 했을때, 어떻게 해야될까? 라는 질문을 할수 있다. 즉 어떤 규칙을 따르는 template 을 template 특수화라고 한다.아래의 코드를 봐보자. 아래와 같이 어떤 특정한걸 주고 싶을때는 객체를 인자로 넘겨주고 temmplate 안에 있는거는 비어있게 해줘야 template 의 특수화가 된다.
이제 class template 을 보기위해 아래 코드를 봐보자. 일단 RandomBox 라는 클래스가 있고, 만약에 GetRandomData() 가 만약에 Float 로 내뱉는 return 이 필요하다고 하면 float 데이터를 담을수 있는 바구니가 필요하면서, float 을 return 하는 GetRandomData() version 을 만들어야할것이다. 그래서 이 다음 코드를 봐보면 template 이 적용된걸 볼 수 있다.
그런데 typename 을 무조건 붙여야되는건 아니다. 즉 다시 말해서 template 안에 들어가는건 골라줘야하는 목록 이라고 볼수 있다. 예를들어서 아래의 코드를 봐보자. SIZE 에다가 인자를 아무거나 주되 int type 인자를 받아야하는 어떤 설정을 따로 해줄수 있다. 하지만, rb1, rb2 가 같이 instantiate 했지만, 서로 다른 객체라는걸 알수 있어서 함수의 인자의 signature 이 같다고 하더라도, 객체는 다르게 이루어졌다고 볼수 있다. 위와 같이 함수에서 템플릿 특수화를 썻던것처럼, 클래스에서도 template 특수화를 사용할수 있다.
template<typenameT,intSIZE>classRandomBox{public:TGetRandomData(){intidx=rand()%SIZE;return_data[idx];}public:T_data[SIZE];}intmain(){srand(static_cast<unsignedint>(time(nullptr)));RandomBox<int,10>rb1;for(inti=0;i<10;i++){rb1._data[i]=i;}intvalue1=rb1.GetRandomData();cout<<value1<<endl;RandomBox<int,20>rb2;for(inti=0;i<20;i++){rb2._data[i]=i;}intvalue2=rb2.GetRandomData();cout<<value2<<endl;//rb1 = rb2; // 서로 다른 객체return0;}
템플릿 특수화를 한번 보자. 위의 코드에서 무조건 double 로 return 하는 값들로만 모아보자. 아래와 같이 보면 double 로 뭔가 규약을주고, 사이즈와 관련된것들은 int 로 아무인자나 받게 보여진다. 만약 double 로 호출을 한다고 하면 RandomBox<double, int SIZE> 가 호출이 되고, 그 외의 것들은 RandomBox 가 호출이 될거다.
template<intSIZE>template<typenameT,intSIZE>classRandomBox{public:TGetRandomData(){intidx=rand()%SIZE;return_data[idx];}public:T_data[SIZE];}classRandomBox<double,intSIZE>{public:doubleGetRandomData(){intidx=rand()%SIZE;return_data[idx];}public:double_data[SIZE];}intmain(){srand(static_cast<unsignedint>(time(nullptr)));RandomBox<int,10>rb1;for(inti=0;i<10;i++){rb1._data[i]=i;}intvalue1=rb1.GetRandomData();cout<<value1<<endl;RandomBox<double,20>rb2;for(inti=0;i<20;i++){rb2._data[i]=i+0.5;}doublevalue2=rb2.GetRandomData();cout<<value2<<endl;//rb1 = rb2; // 서로 다른 객체return0;}
Callback Function
Callback 함수 같은 경우는 결국 다시 호출하다. 약간 Call me back 과 같다. 또는 다시 역으로 호출하다라는 느낌이다. Functor 와 마찬가지로 어떤 상황이 일어나면 이 기능을 호출해줘 라는 느낌으로 사용하면 된다.
classItem{public:int_itemId=0;int_rarity=0;int_ownderId=0;}classFindByOwnderId{public:booloperator()(constItem*item)// 수정이 필요없음{return(item->_ownerId==_ownderId);}public:int_ownerId;}classFindByRarity{public:booloperator()(constItem*item)// 수정이 필요없음{return(item->_rarity==_rarity);}public:int_rairty;}template<typenameT>Item*FindItem(itemitems[],intitemCount,Tselector){for(inti=0;i<itemCount;i++){Item*item=&items[i];// TODO Conditionif(selector(item))returnitem;}returnnullptr;}intmain(){ItemItems[10];items[3]._ownerId=100;items[5]._rarity=1;FindByOwnderIdfunctor1;functor1._ownerId=100;FindByRarityfunctor2;functor2._rarity=1;Item*item1=FindItem(items,10,functor1);Item*item2=FindItem(items,10,functor2);return0;}






](../../../assets/img/photo/1-29-2024/thread.png)
